1. 基础数据类型补充
join把列表变成字字符串
li = ["李嘉诚", "麻花藤", "⻩海峰", "刘嘉玲"] s = "_".join(li) print(s) 李嘉诚_麻花藤_⻩海峰_刘嘉玲 li = "⻩花⼤闺⼥" s = "_".join(li) print(s) ⻩_花_⼤_闺_⼥
列表: 循环删除列表中的每⼀个元素
li = [11, 22, 33, 44] for e in li: li.remove(e) print(li) 结果: [22, 44]
分析原因:
for的运⾏过程. 会有⼀个指针来记录当前循环的元素是哪⼀个, ⼀开始这个指针指向第0个('11'). 然后获取到第0个元素. 紧接着删除第0个. 这个时候. 原来是第⼀个的元素('22')会⾃动的变成第0个. 然后指针向后移动⼀次, 指向1元素''33''. 这时原来的1已经变成了0, 也就不会被删除了,再删除的话就会从1元素(''33'')开始
⽤pop删除试试看:
li = [11, 22, 33, 44] for i in range(0, len(li)): del li[i] print(li) 结果: 报错 # i= 0, 1, 2 删除的时候li[0] 被删除之后. 后⾯⼀个就变成了第0个. # 以此类推. 当i = 2的时候. list中只有⼀个元素. 但是这个时候删除的是第2个此时i = 2 肯定报错啊
经过分析发现. 循环删除都不⾏. 不论是⽤del还是⽤remove. 都不能实现. 那么pop呢?
for el in li: li.pop() # pop也不⾏ print(li) 结果: [11, 22]
只有这样才是可以的:
for i in range(0, len(li)): # 循环len(li)次, 然后从后往前删除 li.pop() print(li)
或者. ⽤另⼀个列表来记录你要删除的内容. 然后循环删除
lst = ["我不是药神", "西游记", "西红柿首富", "天龙八部"] # list在循环的时候不能删. 因为会改变索引 del_lst = [] for el in lst: del_lst.append(el) # 记录下来要删除的内容 for el in del_lst: # 循环记录的内容 lst.remove(el) # 删除原来的内容 print(lst)
4. fromkeys()
dict中的fromkey(),可以帮我们通过list来创建⼀个dict
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"]) print(dic) 输出结果为:{'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']}
前⾯列表中的每⼀项都会作为key, 后⾯列表中的内容作为value. ⽣成dict
dic = {"a":"123"}
s = dict.fromkeys("王健林", "思聪" ) # 返回给你一个新字典
print(s) 输出结果为:{'林': '思聪', '健': '思聪', '王': '思聪'}
fromkeys() 不会对原来的字典产生影响. 产生新字典
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"]) print(dic) dic.get("jay").append("胡⼤") print(dic) 结果: {'jay': ['周杰伦', '麻花藤', '胡⼤'], 'JJ': ['周杰伦', '麻花藤', '胡⼤']}
代码中只是更改了jay那个列表. 但是由于jay和JJ⽤的是同⼀个列表. 所以. 前⾯那个改了. 后⾯那个也会跟着改
5. dict中的元素在迭代过程中是不允许进⾏删除的
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦⽼板'}
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
del dic[k] # dictionary changed size during iteration, 在循环迭代的时候不允许进⾏删除操作
print(dic)
那怎么办呢? 把要删除的元素暂时先保存在⼀个list中, 然后循环list, 再删除
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦⽼板'}
dic_del_list = []
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k) 记录要删除的内容
for el in dic_del_list: 循环要删除的内容
del dic[el] 删除原来的内容
print(dic)
6.类型转换
元组 => 列表 list(tuple) 列表 => 元组 tuple(list) list=>str str.join(list) str=>list str.split() 转换成False的数据: 0,'',None,[],(),{},set() ==> False
⼆. set集合
1.set集合中的元素是不重复的,里面的元素必须是可hash的(int, str, tuple,bool),
我们可以这样来记. set就是dict类型的数据,但是不保存value, 只保存key. set也⽤{}表⽰
注意: set集合中的元素必须是可hash的, 但是set本⾝是不可hash得. set是可变的.
注意: set集合中的元素必须是可hash的, 但是set本⾝是不可hash得. set是可变的. set1 = {'1','alex',2,True,[1,2,3]} # 报错 set2 = {'1','alex',2,True,{1:2}} # 报错 set3 = {'1','alex',2,True,(1,2,[2,3,4])} # 报错
可以使⽤set来去掉重复:
s = {"周杰伦", "周杰伦", "周星星"}
print(s)
结果:
{'周星星', '周杰伦'}
# 给list去重复
lst = [45, 5, "哈哈", 45, '哈哈', 50]
lst = list(set(lst)) # 把list转换成set, 然后再转换回list
print(lst)
三. 深浅拷⻉
1. 直接赋值. 两个变量指向同一个对象.
lst1 = ["金毛狮王", "紫衫龙王", "白眉鹰王", "青衣服往"] lst2 = lst1 # 列表, 进行赋值操作. 实际上是引用内存地址的赋值. 内存中此时只有一个列表. 两个变量指向一个列表 lst2.append("杨做事") # 对期中的一个进行操作. 两个都跟着变 print(lst2) print(lst1) 输出结果为: ['金毛狮王', '紫衫龙王', '白眉鹰王', '青衣服往', '杨做事'] ['金毛狮王', '紫衫龙王', '白眉鹰王', '青衣服往', '杨做事']
2. 浅拷贝 copy 创建新对象
lst1 = ["赵本山", "刘能", "赵四"] # lst2 = lst1.copy() # lst2 和lst1 不是一个对象了 lst2 = lst1[:] # 切片会产生新的对象 lst1.append("谢大脚") print(lst1, lst2) print(id(lst1), id(lst2)) 输出结果为: ['赵本山', '刘能', '赵四', '谢大脚'] ['赵本山', '刘能', '赵四'] 2592283646600 2592283644168
lst1 = ["超人", "七龙珠", "葫芦娃", "山中小猎人", ["金城武", "王力宏", "渣渣辉"]] lst2 = lst1.copy() # 浅拷贝,拷贝第一层,即["金城武", "王力宏", "渣渣辉"],此时还是同一个对象,如图 lst1[4].append("大阳哥") print(lst1, lst2) 输出结果为: ['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] ['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']]
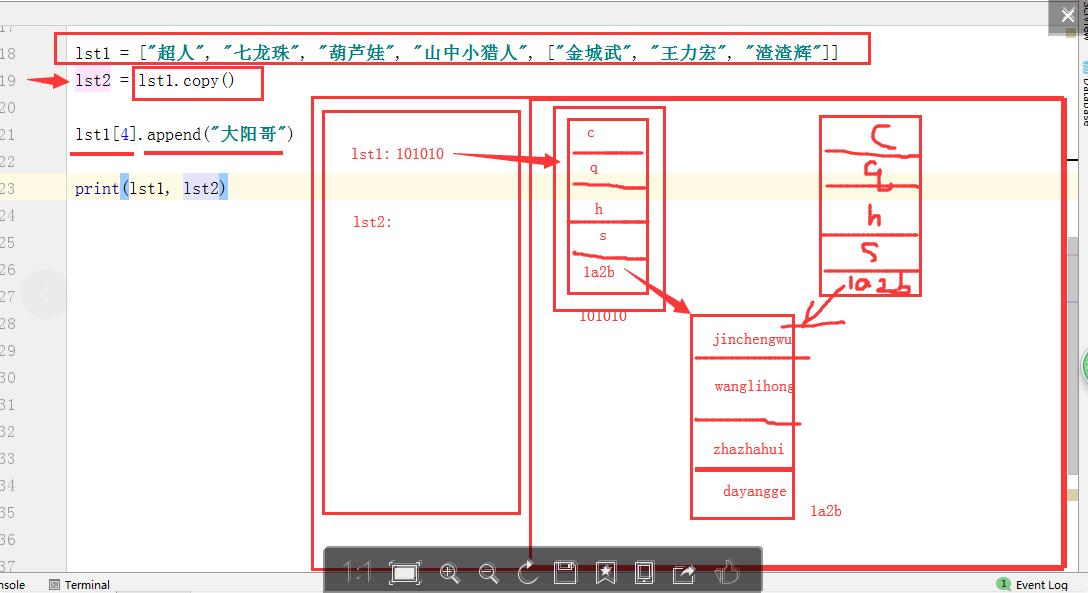
3.深拷⻉
深度拷贝: 对象中的所有内容都会被拷贝一份 import copy copy.deepcopy()
import copy lst1 = ["超人", "七龙珠", "葫芦娃", "山中小猎人", ["金城武", "王力宏", "渣渣辉"]] lst2 = copy.deepcopy(lst1) # 把lst1扔进去进行深度拷贝 , 包括内部的所有内容进行拷贝 lst1[4].append("大阳哥") print(lst1) print(lst2) print(id(lst1),id(lst2)) 输出结果为: ['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] ['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉']] 1512751668040 1512751668552 #此时内存地址已发生了改变