零. 目录
1. 概述
2.
3.
一. 概述
0. 核心参考博文:
https://blog.csdn.net/qq_36459481/article/details/90937809
1. 语言的历史
计算机只能运行二进制,即她只认识0101,所以最开始的程序是用0101编码出来的,用这些01串去控制CPU进行计算,同时还要手动为程序分配存储空间以及输入和输入。显然,这是反人类的.....
wxy碎碎念:计算机无非就俩件事,把数据找个地方放着(存储),和计算并得到结果。所以我们再阐述编程语言的时候基本都要关联一下这两方面。
后来,芯片厂商发明了一些助记符,也就是汇编语言。所谓的01串,无非就是让CPU去计算,去移动,去获取等等,于是把这些行为用固定的指令去代替,然后将指令可以很容易的翻译成二进制代码。各家的汇编格式可能不一样,例如gcc的汇编器使用的是AT&T文法,常见的汇编语言可以使用nasm编译。但是,汇编会直接和硬件比如寄存器打交道,只要与硬件相关那么他的可移植性就....
最后,高级语言诞生了,管你什么硬件,我代表的就是一个逻辑(算法),至于硬件怎么去实现我的逻辑?不管!,于是,可移植性大大提升!
2. 从高级语言到机器语言的转化
根据语言的历史我们基本上可以判断,转化基本上就是 高级 --->汇编 ---->机器, 即
Higher Level language -- compiling?--> assembled code --assembling--> object Program --linking--> executable program
参考链接: http://www.uobabylon.edu.iq/eprints/publication_1_26931_35.pdf
https://en.wikipedia.org/wiki/Compiler
0)Compiler, 编译
- wiki参考:The name "compiler" is primarily used for programs that translate source code from a high-level programming language to a lower level language (e.g., assembly language, object code, or machine code) to create an executable program.
解析:广义的编译器"compiler"是指将一种编程语言(源代码)转化成另一种(目标代码)的计算机程序。现在主要专门指将高级编程语言转化成一种可执行的低级的语言(例如,汇编语言,目标代码,或者机器代码)。也就是说,Compliler的结果不是一定要是汇编,或者一定要直接就是机器码,而是根据你的要求生成,但是有一点是明确的,被操作的对象:高级编程语言。
解析:再一次说明编译后得到汇编并不是必要的,可以直接就是机器码,本来汇编和机器码就是一对一关系(注意,不是等同),只不过前者是一种对人类更友好的表现形式。那么为什么需要汇编呢?
而在gcc编译工具套件中,为了便于Unix平台之间做移植,所以就将汇编器assembler从compiler中单独分离出来,所以在我们最常用的gcc工具编译中,编译compiler可以理解成狭义的"高级语言-->汇编语言", 而从 “汇编语言 -> 机器语言”则经历了assembler和linked。
除此之外,比如LLVM和MSVC支持将程序编译成一个库函数,也就是一独立的模块,但并不能直接运行,只有等待被别人调用(对应linked)的时候,才会真正被运行起来。
wxy: 到此时不知道你是否有这样的疑问。1)unix平台之间的移植怎么就需要了,我全部编译成机器码就不能在多平台之间移植了么? 2)同理, 作为可被调用的库函数,怎么就需要了?
https://en.wikipedia.org/wiki/Relocation_%28computing%29
https://stackoverflow.com/questions/52901266/does-the-compiler-actually-produce-machine-code
https://stackoverflow.com/questions/2135788/what-do-c-and-assembler-actually-compile-to
解析:当有多进程的操作系统的出现,以及动态/静态链接库函数的需求,都要求不能向嵌入式编程那般,直接去操作地址,而是使用符号来代表地址。
于是,编译得到的汇编程序中的地址都是一堆符号,汇编器使用的也是这些符号表来转化成机器码,知道链接器才开始将地址做真正的映射(注意,因为有操作系统,即使此时提到的地址也不是真正的物理地址).
wxy:关于这部分,我们就需要深入讨论下计算机原理,即程序是怎么运行的,以及操作系统所扮演的角色。参见我另一篇博文:
另外,关于gcc,之前只是知道这是一个编译器工具套件,但是常常看到xx是基于gcc,那么说明gcc并不是简单的编译,肯定是由他的风格,于是现在,我大概理解gcc的如下特性了。
首先,也是最重要的,他是可以根据平台编译出运行在操作系统上的object文件,这种文件不是一般的单片机/嵌入式的可执行文件,而是使用的相对地址来表示
然后,你会调用不同的底层操作系统,或者库函数,于是编译器会根据你指定的平台执行对应的接口(一般,见glibc?),
最后,为了达到如上的目的,其整个编译一般情况下经过了compiler,assembler,linked的过程。当然,如果你不需要引用一些库文件.so,.o等,则可以直接一下编译得到最后的.
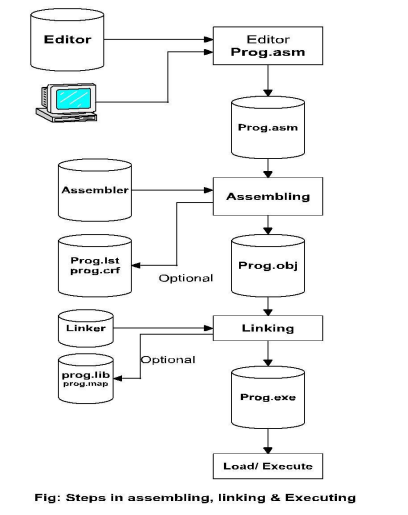
1)Assembling,汇编
- 汇编是指将源(source)程序转化成目标(object)程序,其会生成一个.obj格式的中间过程文件或模块。
- 汇编时,会为数据段(data segment)中每一份数据项(data item), 以及代码段(code segment)中的指令计算地址偏移量。
- 在汇编期间,会在生成的.obj模块前面创建一个头文件,该文件包含了一份不完整的地址信息。
- 汇编器(Assembler)会检查语法错误, 如果则不生成object模块。
- 汇编器会创建.obj .lst和.crf格式的文件,后面两种文件是在运行时创建的,且可选。
- 对于很短的程序也可以手动完成汇编,程序员可以使用查表的方式将每一个助记符翻译成机器语言(machine language)。
- 汇编器会逐条读取程序中的汇编指令并作为ASCII字符,然后将其翻译成对应的机器码(machine code)。
汇编器的类型:
有两种类型的汇编器
(1) One pass 汇编器
- 这种类型的汇编器会一次性扫描所有的汇编程序然后转化成object码。
- 这个汇编器只有定义前向引用的程序。
- 跳转指令使用在扫描期间出现在程序后面的那个地址,所以在这种情况下,程序员会在程序组装后定义这些地址。(wxy: 没理解)
(1) Two pass 汇编器
- 这种类型的汇编器会扫描汇编语言两次.
- 第一次pass会生成程序中的名称(name)和标签(labels)的符号表,并计算他们的相对地址。
- 这个表可以在列表文件的末尾看到,这里用户不需要定义任何东西。
- 第二遍pass使用第一遍构建的表并完成目标代码的创建。
- 这个汇编器比之前的那个更高效、更容易。
2)Linking,链接
- 这一步涉及的是将 .OBJ 模块转换为 .EXE(可执行)模块,即可执行机器码。
- 正是使用上一步汇编器留下的地址完成的。
- 它会将汇编过的目标文件分别进行组装。
- 链接会创建 .EXE、.LIB、.MAP 格式的文件,其中最后两个是可选的。
3) Loading and Executing,加载和执行
- 他会将程序加载到内存中等待执行。
- 他会解析剩余的地址。
- 这一步的处理会在程序加载之前创建程序段前缀(PSP)。
- 最后执行并产生结果。
汇编编译器assembler编译目标代码二进制文件(nasm -f elf -g -F stabs *.asm),连接器linker(ld -o bin_file *.o)除了把目标代码组合成一个单个的块,还要确保模块以外的函数调用能够指向正确的内存引用(连接器必须建立一个索引,也就是符号表,里面存放的是它连接的每一个目标模块中的每一个已命名项,其中存放着一些关于哪个名字或叫符号指向模块内部哪个位置的信息)。
立即数,内置在机器指令内部,它不是存放在寄存器中,也不是存放在位于某个指令之外的内存中。
1, 寄存器打中括号代表寄存器的内存地址中的内存数据。例:
mov eax,[ebx+16]。
2, 在汇编中,变量名代表的地址,不是数据。例:
Msg: "Hello World"
mov ecx,Msg #复制Msg地址到ecx寄存器,而不是数据
mov edx,[Msg] #复制数据,而不是地址
MsgLen: equ $-Msg #$代表末尾,长度=末尾位置减开始位置
https://www.zhihu.com/question/315568815/answer/661107210
https://stackoverflow.com/questions/6287210/assembling-and-linking-steps-for-assembly-language
https://www.zhihu.com/question/348237008/answer/843382847
2,
- 机器语言(CPU可以直接识别的语言)不存在“变量”这个概念,它只能操作内存和寄存器(CPU内部的几个暂存电路,数量很有限)。变量这个概念在实现的时候通常是将之对应于某个寄存器或者某一片内存。
- CPU提供了一系列指令来方便程序员维护一个叫“栈”的数据结构。栈位于内存当中,栈顶和栈底都保存在特殊的寄存器当中,CPU可以随时将数据压栈或者出栈。这个“数据”的含义实际上比较宽泛,它可以是一个数字、字符,也可以是CPU的运行状态。CPU可以将某一刻的运行状态压栈,然后跳转到其他地方执行一段程序,然后出栈恢复之前的执行状态,这就实现了函数的调用。没错,CPU也不太认识什么叫做“函数”,不过将运行状态压栈以及恢复运行状态都有专门的指令,一般就把它们成为”子程序调用指令“和“返回指令”。
- 对于“局部变量”,CPU连“变量”都不认识,所以局部变量什么的也不存在了。不过这玩意可以依靠栈来实现,通过压栈就可以随时分配一个内存,出栈就可以认为这个内存区域不再被使用。配合刚才说过的“函数”调用的实现方法,这种依靠压栈分配出的内存一定只能被当前正在执行的函数使用。因为函数调用前,这片内存还没有被分配,返回后这片内存也不再使用了
编译阶段发生了什么,编译阶段编译器会分析源代码,然后把源代码转成一系列的出入栈操作指令,还有调用指令等。比如说foo那一段变成了:
中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心(Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
global main flag1: add eax, 1 ret main: mov eax, 0 call flag1 ret
(gdb) disas main0x080483f4 <+0>: mov $0x0,%eax => 0x080483f9 <+5>: call 0x80483f0 <flag1> //在此处打断点,此时程序还未执行call语句 0x080483fe <+10>: ret 0x080483ff <+11>: nop (gdb) info register eip eip 0x80483f9 0x80483f9 <main+5> //所以eip中是接下来要执行语句的地址,即call语句 (gdb) info register esp esp 0xffffd16c 0xffffd16c (gdb) stepi 0x080483f0 in flag1 () //此时进入flag1函数,到达该函数的第一条语句待执行
(gdb) disas
=> 0x080483f0 <+0>: add $0x1,%eax
0x080483f3 <+3>: ret
(gdb) info register eip eip 0x80483f0 0x80483f0 <flag1> //此时eip的内容就是即将执行语句的地址,即flag1函数的第一条 (gdb) info register esp //桟指针上移(地址负增长)一条指令的长度,即4字节,内容是call指令的下一条,即ret指令 esp 0xffffd168 0xffffd168 (gdb) p/x *(unsigned int*)$esp $1 = 0x80483fe
局部变量都是桟,那么全局变量和静态变量呢?
- 前端负责:词法分析 -> 语法分析 -> 语义分析 -> 中间代码生成
- 后端负责:平台无关优化 -> 指令选择 -> 平台相关优化 -> 指令调度 -> 寄存器分配 -> 目标代码生成
#gcc -S helloc.c //编译得到汇编语言文件helloc.s #gcc -C helloc.s -o helloc.o //汇编得到二进制文件helloc.o #gcc -o helloc helloc.o //链接代码中引用的库文件,得到最终的目标文件
错误信息: helloc.o:在函数‘_fini’中: (.fini+0x0): multiple definition of `_fini' /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crti.o:(.fini+0x0):第一次在此定义 helloc.o:在函数‘data_start’中: (.data+0x0): multiple definition of `__data_start' /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crt1.o:(.data+0x0):第一次在此定义 helloc.o:(.rodata+0x8): multiple definition of `__dso_handle' /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtbegin.o:(.rodata+0x0):第一次在此定义 helloc.o:(.rodata+0x0): multiple definition of `_IO_stdin_used' /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crt1.o:(.rodata.cst4+0x0):第一次在此定义 helloc.o:在函数‘_start’中: (.text+0x0): multiple definition of `_start' /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crt1.o:(.text+0x0):第一次在此定义 helloc.o:在函数‘_init’中: (.init+0x0): multiple definition of `_init' /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crti.o:(.init+0x0):第一次在此定义 /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtend.o:(.tm_clone_table+0x0): multiple definition of `__TMC_END__' helloc.o:(.data+0x8):第一次在此定义 /usr/bin/ld: error in helloc.o(.eh_frame); no .eh_frame_hdr table will be created. collect2: 错误:ld 返回 1
定位:
根据错误信息大概看出来是有重定义了,那么就说名在链接之前有些工作已经做了,也就是说前两步执行有问题?
仔细看了下前两条命令,突然觉得-C好奇怪,另外发现执行完第二步生成的.o文件就是绿色的(表示可执行)
于是,将第二改成如下,OK。
#gcc -c helloc.s -o helloc.o
2,系统异常崩溃,通过如下两方面可以定位之
反汇编用法:
#objdump -SCl Test_agent > test.txt
当系统日至出错如下:
Nov 25 21:47:02 localhost kernel: Test_agent[12558]: segfault at 1a4 ip 0000000000447c3a sp 00007fab166f9aa0 error 4 in Test_agent[400000+d0000]
则可结合得到的汇编代码进行定位,判断是哪里出现的问题
#include <stdio.h> int static add(int a, int b, int n1, int n2, int n3, int n4, int n5){ 0: 55 push %rbp //同样,压桟的是上一个函数的信息,即上一桟帧的 1: 48 89 e5 mov %rsp,%rbp 4: 89 7d fc mov %edi,-0x4(%rbp) 7: 89 75 f8 mov %esi,-0x8(%rbp) a: 89 55 f4 mov %edx,-0xc(%rbp) d: 89 4d f0 mov %ecx,-0x10(%rbp) 10: 44 89 45 ec mov %r8d,-0x14(%rbp) 14: 44 89 4d e8 mov %r9d,-0x18(%rbp) return a + b; 18: 8b 45 f8 mov -0x8(%rbp),%eax 1b: 8b 55 fc mov -0x4(%rbp),%edx 1e: 01 d0 add %edx,%eax } 20: 5d pop %rbp 21: c3 retq 0000000000000022 <main>: int main(){ 22: 55 push %rbp //main函数也是被调用的,是被_start函数调用的,所以也需要压桟,就是把上一桟帧的桟底的位置放入桟中 23: 48 89 e5 mov %rsp,%rbp //将当前栈顶的值给栈底,相当于原来的栈顶从此,作为本函数栈帧的栈底了 26: 48 83 ec 28 sub $0x28,%rsp //栈顶上移16*2 + 8 == 40个字节 int x1,x2,x3,x4,x5,x6,x7,x8,x9; int x=5; 2a: c7 45 fc 05 00 00 00 movl $0x5,-0x4(%rbp) //从基值开始向下的4个字节赋值为5,相当于这块是x的位置, movl代表移动4字节,累计占用4字节 int y=6; 31: c7 45 f8 06 00 00 00 movl $0x6,-0x8(%rbp) //接下来4字节是y的, 累计占用了8字节 x8=10; 38: c7 45 f4 0a 00 00 00 movl $0xa,-0xc(%rbp) //接下来的4字节是x8,,累计占用了12字节 x9=11; 3f: c7 45 f0 0b 00 00 00 movl $0xb,-0x10(%rbp) //接下来的4字节是x9, 累计占用了16字节 int u=add(x,y,1,1,1,1,x8); 46: 8b 75 f8 mov -0x8(%rbp),%esi //把y的值给si 49: 8b 45 fc mov -0x4(%rbp),%eax //把x的值给ax 4c: 8b 55 f4 mov -0xc(%rbp),%edx //把x8的值给dx 4f: 89 14 24 mov %edx,(%rsp) //把x8的值入栈,纯入栈,栈指针不动,将占用4字节,累计占用20字节 52: 41 b9 01 00 00 00 mov $0x1,%r9d //把常量入参给r9 58: 41 b8 01 00 00 00 mov $0x1,%r8d // ... r8 5e: b9 01 00 00 00 mov $0x1,%ecx // ... cx 63: ba 01 00 00 00 mov $0x1,%edx // ... dx 68: 89 c7 mov %eax,%edi //把x的值给di 6a: e8 91 ff ff ff callq 0 <add> //跳转.......,这里面隐藏了一个压栈操作,即会将call的下一指令的地址(64位?8字节?)压栈,栈顶指针是否偏移?累计28个字节? 6f: 89 45 ec mov %eax,-0x14(%rbp) //用来取得函数调用得到的结果到ax寄存器中? } 72: c9 leaveq 73: c3 retq [root@localhost testCompile]#