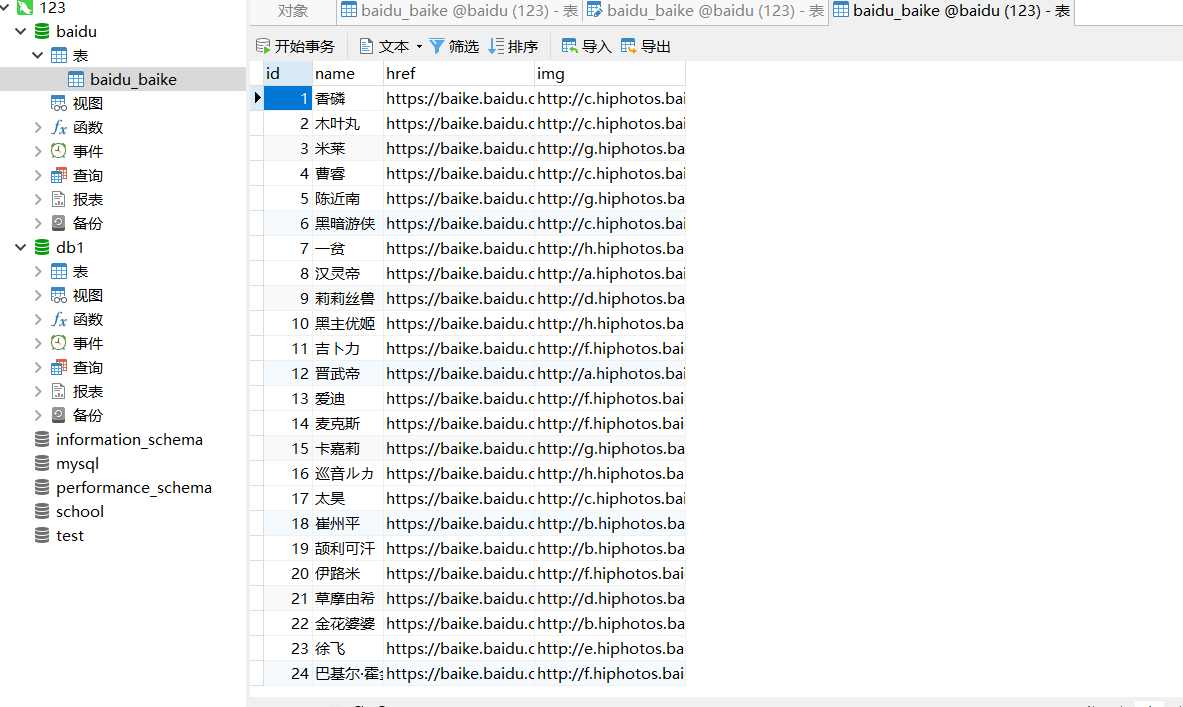
网页情况:
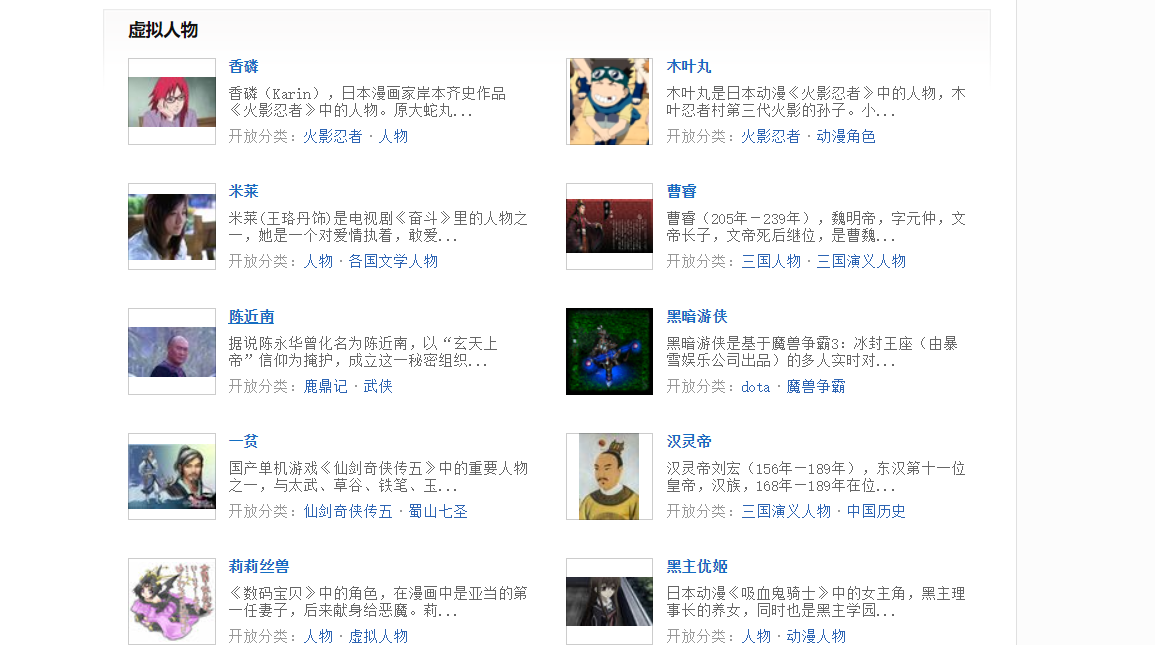
代码:
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup as bs
import re
import time
import pymysql
def get_one_page(url):
#得到一页的内容
try:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
#使用BeautifuSoup解析一页的内容
soup = bs(html,'lxml')
for data in soup.find_all('div',class_="photo"):
name = data.a['title']
href = "https://baike.baidu.com"+data.a['href']
img = data.img['src']
#有些人物没有图片,图片链接有误需要拼接
if re.search("^/static",img):
img ="https://baike.baidu.com" + img
yield {
'name':name,
'href':href,
'img':img
}
def write_mysql(item):
#写入Mysql数据库
conn = pymysql.connect(
host='localhost',
user='root',
password='',
database='baidu',
charset='utf8' # 别写成utf-8
)
cursor = conn.cursor() # 建立游标
sql = "insert into baidu_baike(name,href,img) values(%s,%s,%s)"
cursor.execute(sql,(item['name'],item['href'],item['img'])) # 注意excute的位置参数的问题
conn.commit() # 修改值的时候,一定需要commit
cursor.close() # 关闭
conn.close() # 关闭
def main(url):
#主函数
html = get_one_page(url)
items = parse_one_page(html)
for item in items:
write_mysql(item)
if __name__ == '__main__':
#分析URL构成,拼接URL
for i in range(1,7):
url = "http://baike.baidu.com/fenlei/虚拟人物?limit=30&index=" + str(i) + "&offset=" + str(
30 * (int(i) - 1)) + "# gotoList"
main(url)
print('正在爬取第%s页'%i)
time.sleep(1)
print("全部写入成功!")
运行结果:
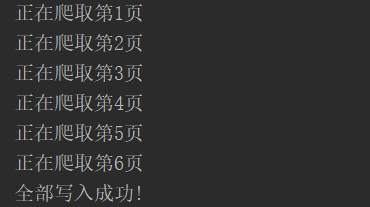
mysql数据库结果: