[图像分类]论文笔记VovNet(专注GPU计算、能耗高效的网络结构)
论文链接:An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
1. 简介
- DenseNet在目标检测任务上表现很好。因为它通过聚合不同receptive field特征层的方式,保留了中间特征层的信息。它通过feature reuse 使得模型的大小和flops大大降低,但是,实验证明,DenseNet backbone更加耗时也增加了能耗:dense connection架构使得输入channel线性递增,导致了更多的内存访问消耗,进而导致更多的计算消耗和能耗。
2. 高效网络设计要素 Factors of Efficient Network Design
根据shuffleNet v2,减小flops和model size并不能保证GPU运算时间的减少。比如,shuffleNet v2和mobileNet v2有类似的计算量(FLOPS),但是前者比后者快, squeezeNet虽然比VGG少了50倍的参数量,但是它比VGG能耗更多。那么哪些是影响GPU运算效率和能耗的因素呢?
2.1. Memory Access Cost (MAC)
- 对于CNN,能耗在内存访问而不是计算上。
- 影响MAC的主要是是内存占用(intermediate activation memory footprint),它主要受卷积核和feature map大小的影响。
2.2. GPU-Computation Efficiency
- 通过减少FLOP是来加速的前提是,每个flop point的计算效率是一致的。
- GPU特性:
- 擅长parallel computation,tensor越大,GPU使用效率越高。
- 把大的卷积操作拆分成碎片的小操作将不利于GPU计算。
- 因此,设计layer数量少的网络是更好的选择。mobileNet使用1x1卷积来减少计算量,不过这不利于GPU计算。
- 为了衡量GPU使用效率,我们使用Flops/s指标。
3. Proposed Method
3.1. Rethinking Dense Connection
- DenseNet通过把当浅层和深层的feature map concat来实现更好的特征提取。在参数和计算量有限的情况下,densenet将比resnet等网络做更多的trade-off 。在shuffleNet V2文章中,我们有
其中,
- 上述公式展示了MAC的下界限。可以看出:在计算量和参数量固定的前提下,conv的input和output的size一致,可以最小化MAC。
- 使用Dense connect模块,输出的channel size不变,但是输入的channel size一直在线性增加,因此DenseNet有很高的MAC。
- bottleneck connection同样不利于GPU计算。在模型很大的时候,计算量随着深度指数二阶增长。bottleneck 把一个3x3的卷积分成了两个计算,相当于增加了一次序列运算。
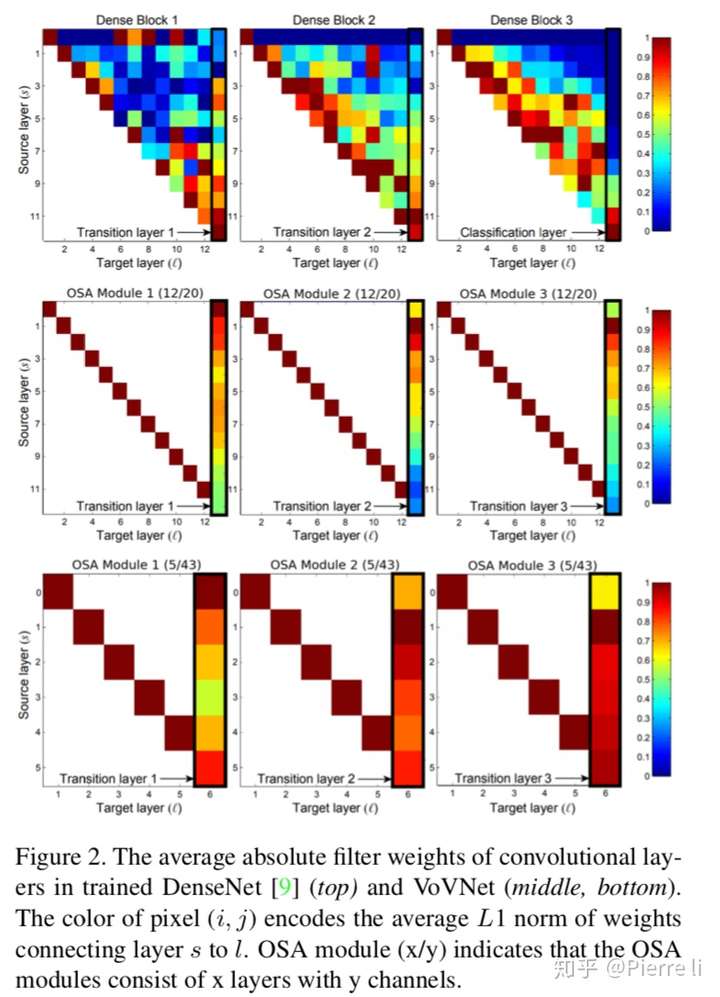
- 上图分析了DenseNet中,浅层feature map对深层feature map的贡献。可以看出,前者对后者的贡献很少。所以我们提出假设1:中间层聚合能力和最后层的聚合能力成反比。也就是说,中间层特征层对的聚合能力越好,那么最后的feature map的聚合能力就越弱。
- 因此,让中间的feature maps的聚合能力弱化或者减少其相关性,会更利于最后feature map表达能力的提升。因为可以进一步提出假设,相比于它们造成的损耗而言,中间特征层的dense connection并不重要。
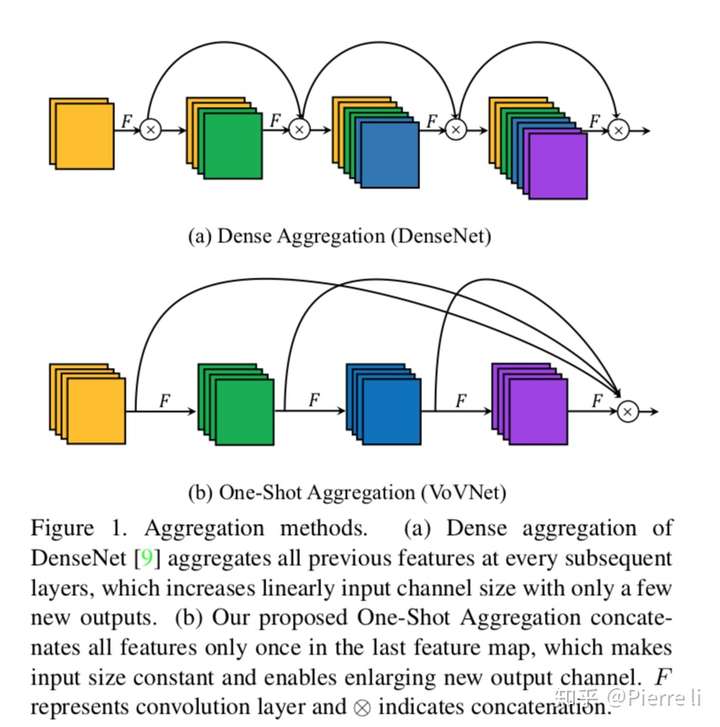
3.2. One-Shot Aggregation
- 因此,本文提出OSA(one-shot-aggregation)模块。在OSA module中,每一层产生两种连接,一种是通过conv和下一层连接,产生receptive field 更大的feature map,另一种是和最后的输出层相连,以聚合足够好的特征。
- 计算发现,通过使用OSA module,5层43channels的DenseNet-40的MAC可以被减少30%(3.7M -> 2.5M)
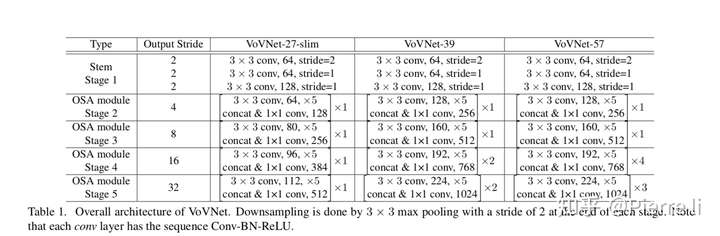
- 进步一地,我们基于OSA module构建VovNet网络结构。如上图所示,我们分别构建了VoVNet-27-slim,VoVNet-39, VoVNet-57。其中downsampling 通过3x3 stride=2的conv实现。
4. Experiments
实验1: VoVNet vs. DenseNet. 对比不同backbone下的目标检测模型性能(PASCALVOC)
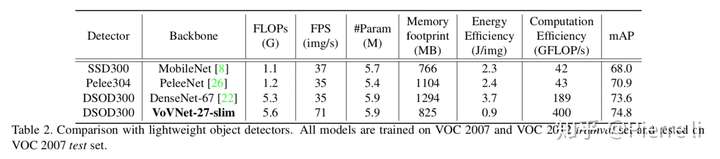
- 对比指标:
- Flops:模型需要的计算量
- FPS:模型推断速度img/s
- 参数数量
- 内存占用
- 能耗
- GPU使用效率(GFlops/s)
- mAP(目标检测性能评价指标)
- 现象1:相比于DenseNet-67,PeleeNet减少了Flops,但是推断速度没有提升,与之相反,VoVNet-27-slim稍微增加了Flops,而推断速度提升了一倍。同时,VoVNet-27-slim的精度比其他模型都高。
- 现象2:VoVNet-27-slim的内存占用、能耗、GPU使用效率都是最高的。
- 结论1:相比其他模型,VoVNet做到了准确率和效率的均衡,提升了目标检测的整体性能。
另外,PeleeNet是通过把dense block拆分为更小的dense block实现flops减少的。由此,可以推断把dense block分解为小片段的计算并不利于GPU运算。
实验2:Ablation study on 1×1 conv bottleneck.
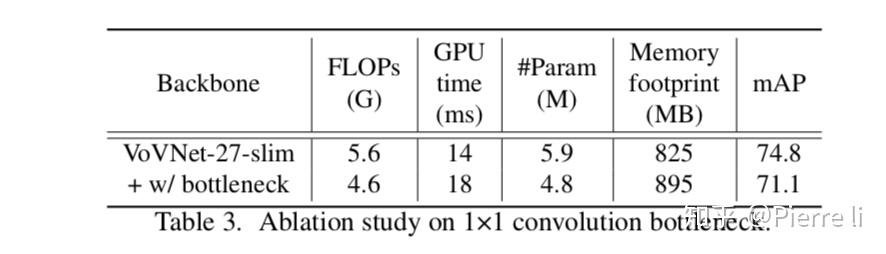
结论2:可以看出,1x1 bottleneck增加了GPU Inference时间,降低了mAP,尽管它减少了参数数量和计算量。
因为1x1 bottleneck增加网路层数,要求更多的激活层,因为增加了内存占用。
实验3: GPU-Computation Efficiency.
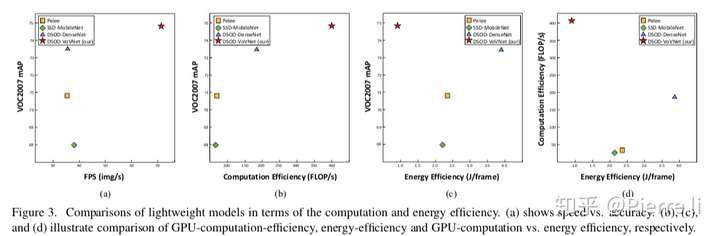
- (a) VoVNet兼顾准确率和Inference 速度
- (b) VoVNet兼顾准确率和GPU使用率
- (c) VoVNet兼顾准确率和能耗
- (d) VoVNet监督能耗和GPU使用率
# 这里的能耗计算不知道怎么进行的
实验室4:基于RefineDet架构比较VoVNet、ResNet和DenseNet
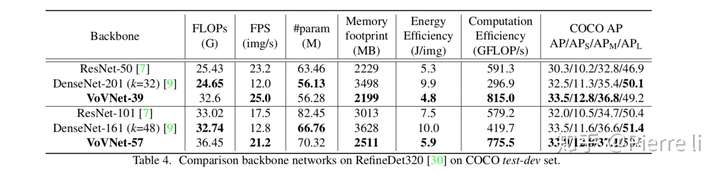
结论4:从COCO数据集测试结果看,相比于ResNet,VoVnet在Inference速度,内存占用,能耗,GPU使用率和准确率上都占据优势。尽管很多时候,VoVNet需要更多的计算量以及参数量。
- 对比DenseNet161(k=48)和DenseNet201(k=32)可以发现,深且”瘦“的网络,GPU使用率更低。【有两个变量,暂时不知道哪个是主要的】
- 另外,我们发现,相比于ResNet,VoVNet在小目标上的表现更好。
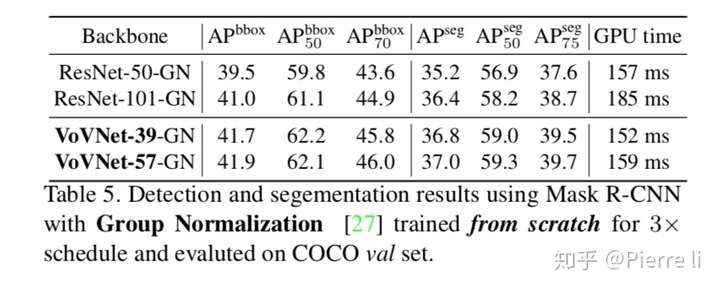
实验5:Mask R-CNN from scratch
我们通过替换Mask R-CNN的backbone,也发现VoVNet在Inference速度和准确率上优于ResNet.