我们会告诉你 Nginx 如何工作及其背后的理念,还有如何优化以加快应用的性能,如何安装启动和保持运行。
这个教程有三个部分:
-
基本概念 —— 这部分需要去了解 Nginx 的一些指令和使用场景,继承模型,以及 Nginx 如何选择 server 块,location 的顺序。
-
性能 —— 介绍改善 Nginx 速度的方法和技巧,我们会在这里谈及 gzip 压缩,缓存,buffer 和超时。
-
SSL 安装 —— 如何配置服务器使用 HTTPS
创建这个系列,我们希望,一是作为参考书,可以通过快速查找到相关问题(比如 gzip 压缩,SSL 等)的解决方式,也可以直接通读全文。为了获得更好的学习效果,我们建议你在本机安装 Nginx 并且尝试进行实践。
tcp_nodelay, tcp_nopush 和 sendfile
tcp_nodelay
在 TCP 发展早期,工程师需要面对流量冲突和堵塞的问题,其中涌现了大批的解决方案,其中之一是由 John Nagle 提出的算法。
Nagle 的算法旨在防止通讯被大量的小包淹没。该理论不涉及全尺寸 tcp 包(最大报文长度,简称 MSS)的处理。只针对比 MSS 小的包,只有当接收方成功地将以前的包(ACK)的所有确认发送回来时,这些包才会被发送。在等待期间,发送方可以缓冲更多的数据之后再发送。

与此同时,诞生了另一个理论,延时 ACK
在 TCP 通讯中,在发送数据后,需要接收回应包(ACK)来确认数据被成功传达。
延时 ACK 旨在解决线路被大量的 ACK 包拥堵的状况。为了减少 ACK 包的数量,接收者等待需要回传的数据加上 ACK 包回传给发送方,如果没有数据需要回传,必须在至少每 2 个 MSS,或每 200 至 500 毫秒内发送 ACK(以防我们不再收到包)。

正如你可能在一开始就注意到的那样 —— 这可能会导致在持久连接上的一些暂时的死锁。让我们重现它!
假设:
-
初始拥塞窗口等于 2。拥塞窗口是另一个 TCP 机制的一部分,称为慢启动。细节现在并不重要,只要记住它限制了一次可以发送多少个包。在第一次往返中,我们可以发送 2 个 MSS 包。在第二次发送中:4 个 MSS 包,第三次发送中:8 个MSS,依此类推。
-
4 个已缓存的等待发送的数据包:A, B, C, D
-
A, B, C是 MSS 包
-
D 是一个小包
场景:
-
由于是初始的拥塞窗口,发送端被允许传送两个包:A 和 B
-
接收端在成功获得这两个包之后,发送一个 ACK
-
发件端发送 C 包。然而,Nagle 却阻止它发送 D 包(包长度太小,等待 C 的ACK)
-
在接收端,延迟 ACK 使他无法发送 ACK(每隔 2 个包或每隔 200 毫秒发送一次)
-
在 200ms 之后,接收器发送 C 包的 ACK
-
发送端收到 ACK 并发送 D 包
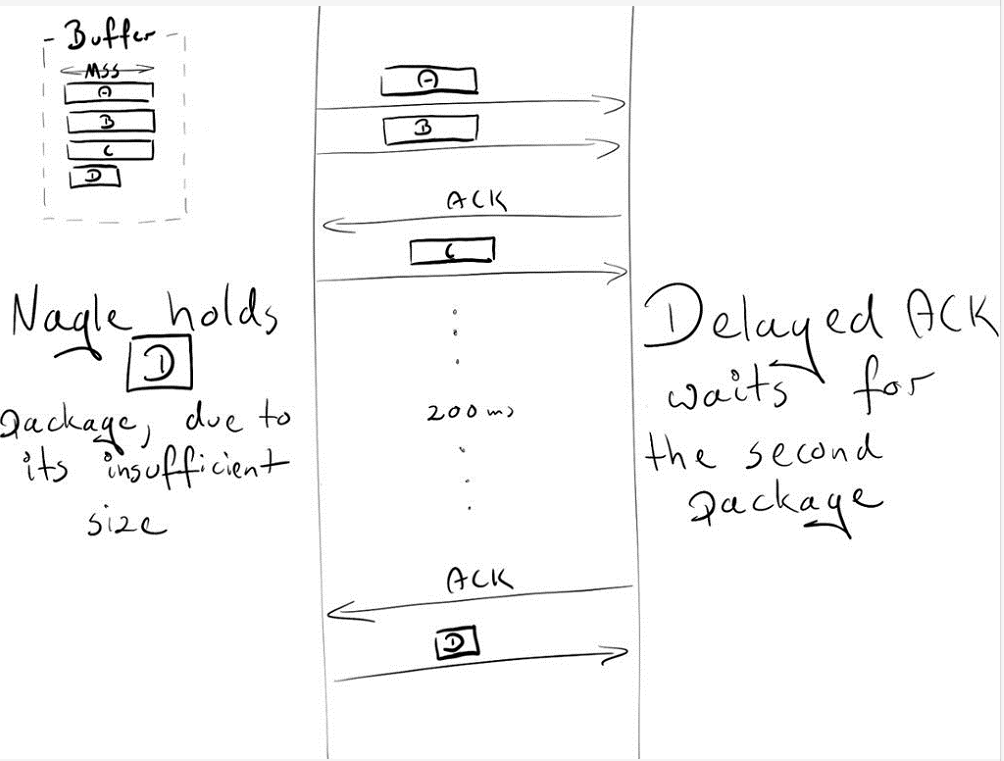
在这个数据交换过程中,由于 Nagel 和延迟 ACK 之间的死锁,引入了 200ms 的延迟。
Nagle 算法是当时真正的救世主,而且目前仍然具有极大的价值。但在大多数情况下,我们不会在我们的网站上使用它,因此可以通过添加 TCP_NODELAY 标志来安全地关闭它。

享受这200ms提速吧!
更多的细节,推荐阅读其他优秀的文章。
sendfile
正常来说,当要发送一个文件时需要下面的步骤:
-
malloc(3) - 分配一个本地缓冲区,储存对象数据。
-
read(2) - 检索和复制对象到本地缓冲区。
-
write(2) - 从本地缓冲区复制对象到 socket 缓冲区。
这涉及到两个上下文切换(读,写),并使相同对象的第二个副本成为不必要的。正如你所看到的,这不是最佳的方式。值得庆幸的是还有另一个系统调用,提升了发送文件(的效率),它被称为:sendfile(2)(想不到吧!居然是这名字)。这个调用在文件 cache 中检索一个对象,并传递指针(不需要复制整个对象),直接传递到 socket 描述符,Netflix 表示,使用 sendfile(2) 将网络吞吐量从 6Gbps 提高到了 30Gbps。
然而,sendfile(2) 有一些注意事项:
-
不可用于 UNIX sockets(例如:当通过你的上游服务器发送静态文件时)
-
能否执行不同的操作,取决于操作系统(这里查看更多)
在 nginx 中打开它

tcp_nopush
tcp_nopush 与 tcp_nodelay 相反。不是为了尽可能快地推送数据包,它的目标是一次性优化数据的发送量。
在发送给客户端之前,它将强制等待包达到最大长度(MSS)。而且这个指令只有在 sendfile 开启时才起作用。

看起来 tcp_nopush 和 tcp_nodelay 是互斥的。但是,如果所有 3 个指令都开启了,nginx 会:
-
确保数据包在发送给客户之前是已满的
-
对于最后一个数据包,tcp_nopush 将被删除 —— 允许 TCP 立即发送,没有 200ms 的延迟
我应该使用多少进程?
工作进程
worker_process 指令会指定:应该运行多少个 worker。默认情况下,此值设置为 1。最安全的设置是通过传递 auto 选项来使用核心数量。
但由于 Nginx 的架构,其处理请求的速度非常快 - 我们可能一次不会使用超过 2-4 个进程(除非你正在托管 Facebook 或在 nginx 内部执行一些 CPU 密集型的任务)。

worker 连接
与 worker_process 直接绑定的指令是 worker_connections。它指定一个工作进程可以一次打开多少个连接。这个数目包括所有连接(例如与代理服务器的连接),而不仅仅是与客户端的连接。此外,值得记住的是,一个客户端可以打开多个连接,同时获取其他资源。

打开文件数目限制
在基于 Unix 系统中的“一切都是文件”。这意味着文档、目录、管道甚至套接字都是文件。系统对一个进程可以打开多少文件有一个限制。要查看该限制:

这个系统限制必须根据 worker_connections 进行调整。任何传入的连接都会打开至少一个文件(通常是两个连接套接字以及后端连接套接字或磁盘上的静态文件)。所以这个值等于 worker_connections*2 是安全的。幸运的是,Nginx 提供了一个配置选项来增加这个系统的值。要使用这个配置,请添加具有适当数目的 worker_rlimit_nofile 指令并重新加载 nginx。

配置
worker_process auto;
worker_rlimit_nofile 2048; # Changes the limit on the maximum number of open files (RLIMIT_NOFILE) for worker processes.
worker_connections 1024; # Sets the maximum number of simultaneous connections that can be opened by a worker process.
最大连接数
如上所述,我们可以计算一次可以处理多少个并发连接:

keep_alive_timeout (后续有更多介绍) + avg_response_time 告诉我们:单个连接持续了多久。我们也除以 2,通常情况下,你将有一个客户端打开 2 个连接的情况:一个在 nginx 和客户端之间,另一个在 nginx 和上游服务器之间。
Gzip
启用 gzip 可以显著降低响应的(报文)大小,因此,客户端(网页)会显得更快些。
压缩级别
Gzip 有不同的压缩级别,1 到 9 级。递增这个级别将会减少文件的大小,但也会增加资源消耗。作为标准我们将这个数字(级别)保持在 3 - 5 级,就像上面说的那样,它将会得到较小的节省,同时也会得到更大的 CPU 使用率。
这有个通过 gzip 的不同的压缩级别压缩文件的例子,0 代表未压缩文件。


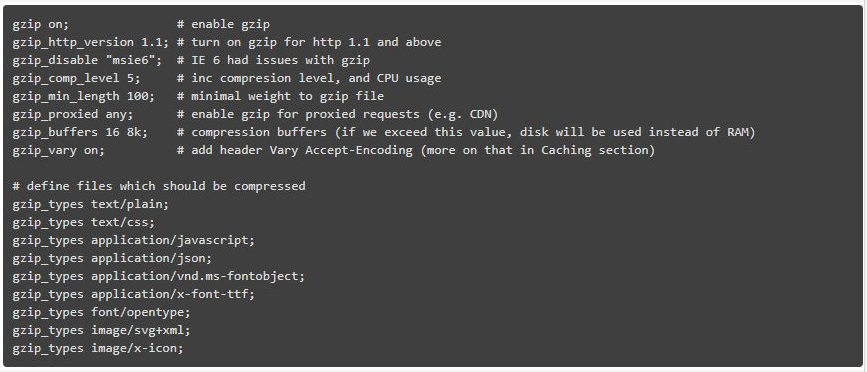
gzip_http_version 1.1;
这条指令告诉 nginx 仅在 HTTP 1.1 以上的版本才能使用 gzip。我们在这里不涉及 HTTP 1.0,至于 HTTP 1.0 版本,它是不可能既使用 keep-alive 和 gzip 的。因此你必须做出决定:使用 HTTP 1.0 的客户端要么错过 gzip,要么错过 keep-alive。
配置
缓存
缓存是另一回事,它能提升用户的请求速度。
管理缓存可以仅由 2 个 header 控制:
-
在 HTTP/1.1 中用 Cache-Control 管理缓存
-
Pragma 对于 HTTP/1.0 客户端的向后兼容性
缓存本身可以分为两类:公共缓存和私有缓存。公共缓存是被多个用户共同使用的。专用缓存专用于单个用户。我们可以很容易地区分,应该使用哪种缓存:

对于标准资源,我们想保存1个月:

上面的配置似乎足够了。然而,使用公共缓存时有一个注意事项。
让我们看看如果将我们的资源存储在公共缓存(如 CDN)中,URI 将是唯一的标识符。在这种情况下,我们认为 gzip 是开启的。
有2个浏览器:
-
旧的,不支持 gzip
-
新的,支持 gzip
旧的浏览器给 CDN 发送了一个 netguru.co/style 请求。但是 CDN 也没有这个资源,它将会给我们的服务器发送请求,并且返回未经压缩的响应。CDN 在哈希里存储文件(为以后使用):

然后将其返回给客户端。
现在,新的浏览器发送相同的请求到 CDN,请求 netguru.co/style.css,获取 gzip 打包的资源。由于 CDN 仅通过 URI 标识资源,它将为新浏览器返回一样的未压缩资源。新的浏览器将尝试提取未打包的文件,但是将获得无用的东西。
如果我们能够告诉公共缓存是怎样进行 URI 和编码的资源识别,我们就可以避免这个问题。

这正是 Vary Accept-Encoding: 完成的。它告诉公共缓存,可以通过 URI 和 Accept-Encoding header 区分资源。
所以我们的最终配置如下:

超时
client_body_timeout 和 client_header_timeout 定义了 nginx 在抛出 408(请求超时)错误之前应该等待客户端传输主体或头信息的时间。
send_timeout 设置向客户端发送响应的超时时间。超时仅在两次连续的写入操作之间被设置,而不是用于整个响应的传输过程。如果客户端在给定时间内没有收到任何内容,则连接将被关闭。
设置这些值时要小心,因为等待时间过长会使你容易受到攻击者的攻击,并且等待时间太短的话会切断与速度较慢的客户端的连接。

Buffers
client_body_buffer_size
设置读取客户端请求正文的缓冲区大小。如果请求主体大于缓冲区,则整个主体或仅其部分被写入临时文件。对 client_body_buffer_size 而言,设置 16k 大小在大多数情况下是足够的。
这是又一个可以产生巨大影响的设置,必须谨慎使用。太小了,则 nginx 会不断地使用 I/O 把剩余的部分写入文件。太大了,则当攻击者可以打开所有连接但你无法在系统上分配足够缓冲来处理这些连接时,你可能容易受到 DOS 攻击。
client_header_buffer_size 和 large_client_header_buffers
如果 header 不能跟 client_header_buffer_size 匹配上,就会使用 large_client_header_buffers。如果请求也不适合 large_client_header_buffers,将给客户端返回一个错误提示。对于大多数的请求来说,1KB 的缓存是足够的。但是,如果一个包含大量记录的请求,1KB 是不够的。
如果请求行的长度超限,将给客户端返回一个 414(请求的 URI 太长)错误提示。如果请求的 header 长度超限,将抛出一个 400(错误请求)的错误代码
client_max_body_size
设置客户端请求主体的最大允许范围,在请求头字段中指定“内容长度”。如果您希望允许用户上传文件,调整此配置以满足您的需要。
配置

Keep-Alive
HTTP 所依赖的 TCP 协议需要执行三次握手来启动连接。这意味着在服务器可发送数据(例如图像)之前,需要在客户机和服务器之间进行三次完整的往返。
假设你从 Warsaw 请求的 /image.jpg,并连接到在柏林最近的服务器:
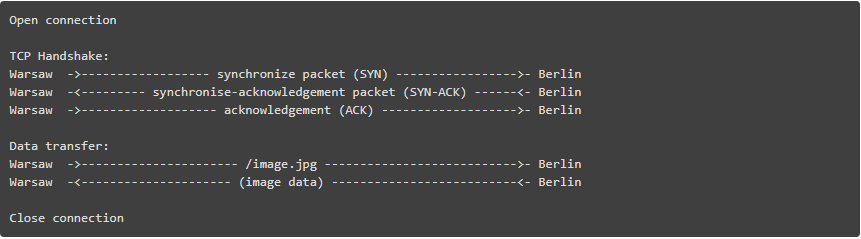
对于另一次请求,你将不得不再次执行整个初始化。如果你在短时间内发送多次请求,这可能会快速累积起来。这样的话 keep-alive 使用起来就方便了。在成功响应之后,它保持连接空闲给定的时间段(例如 10 秒)。如果在这段时间内有另一个请求,现有的连接将被重用,空闲时间将被刷新。
Nginx 提供了几个指令来调整 keepalive 设置。这些可以分为两类:
-
在客户端和 nginx 之间 keep-alive
keepalive_disable msie6; # disable selected browsers.
# The number of requests a client can make over a single keepalive connection. The default is 100, but a much higher value can be especially useful for testing with a load‑generation tool, which generally sends a large number of requests from a single client.
keepalive_requests 100000;
# How long an idle keepalive connection remains open.
keepalive_timeout 60;
在 nginx 和上游服务器之间 keep-alive
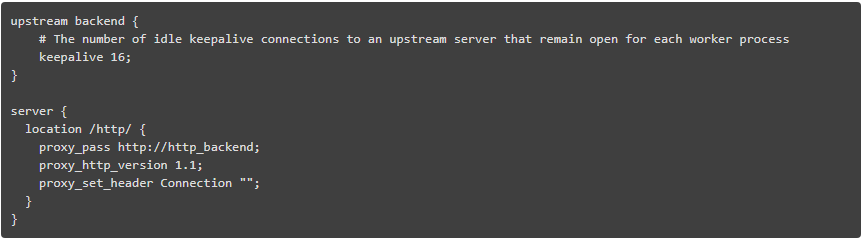
就这些了。
转自:http://mp.weixin.qq.com/s/XjReKjCO3eCH6oGhBJJS5g