摘要
Siam-RPN提出了一种基于RPN的孪生网络结构。由孪生子网络和RPN网络组成,它抛弃了传统的多尺度测试和在线跟踪,从而使得跟踪速度非常快。在VOT实时跟踪挑战上达到了最好的效果,速度最高160fps。
一、研究动机
作者将流行的跟踪算法分为两类,一类是基于相关滤波类并进行在线更新的跟踪算法,另一类是使用深度特征抛弃在线更新的跟踪算法,前者严重限制了跟踪速度,后者没有使用域特定信息(即某个特定的跟踪视频的信息)。
作者提出的网络分为模板支和检测支。训练过程中,在相关特征图上执行proposal extraction、没有预定义好的类别信息;在跟踪过程中使用one-shot检测框架和meta-learning。其中,两个原因使得跟踪算法效果很好:大量数据训练;RPN结构使得跟踪尺度和比例都非常好。
二、相关工作
相关滤波类的跟踪算法:GOTURN、Re3、Siamese-FC、CFNet。后两个没有做回归去调整候选框位置,并且需要多尺度测试,破坏了模型的优雅性。
RPN网络:RPN网络广泛应用在目标检测任务中,从RCNN到Faster-RCNN,RPN网络产生proposals代替了原始的selective search方法,提高了检测速度,后来FPN改进了RPN网络,提高了对微小物体的检测能力,以及后来的PRN的改进版本的使用,像SSD、YOLO等都是非常高效的检测器。
One-shot learning:贝叶斯方法和meta-learning方法。后者用新的神经网络估计目标网络前向传播的梯度。(However, the performance of Learnet is not competitive the modern DCF based methods, e.g.CCOT in multiple benchmarks )
三、算法原理
1. Siam-RPN网络结构
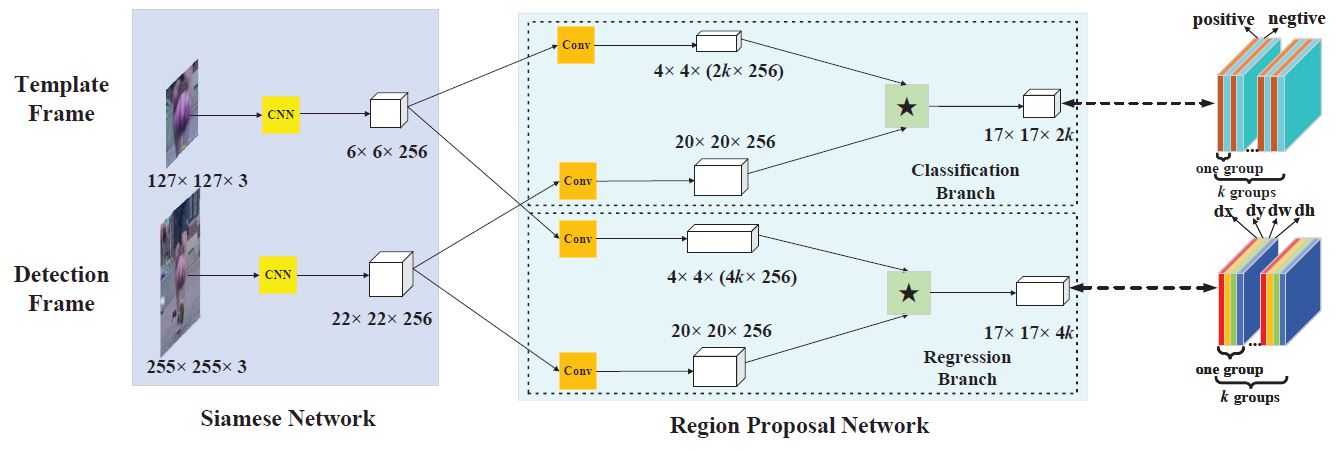
此网络由Siamese Network和Region Proposal Network两部分组成。前者用来提取特征,后者用来产生候选区域。其中,RPN子网络由两个分支组成,一个是用来区分目标和背景的分类分支,另外一个是微调候选区域的回归分支。整个网络实现了端到端的训练。
Siamese Network提取特征:
该部分和Siam-FC相同,详见另外一篇博客给定(L_{ au})是一种转换操作(left(L_{ au} x ight)[u]=x[u- au]),函数(h)作为全卷积网络变换函数,(k)是全卷积网络变换的比例因子,则(hleft(L_{k au} x ight)=L_{ au} h(x)),表示的含义是:先对(x)进行有比例因子的转换操作再进行全卷积操作等同于先对(x)进行全卷积操作再进行转换操作。将网络作为一种变换(varphi),将这种变换分别应用到模板支和检测支上,产生模板和搜索区域的特征(varphi(z), varphi(x))。
RPN网络:
RPN网络由两部分组成,一部分是分类分支,用于区分目标和背景,另一部分是回归分支,它将候选区域进行微调。对于分类分支,它将给出每个样本被预测为目标和背景的打分。网络将用Siam网络提取到的模板和检测帧的特征用一个新的卷积核进行卷积,在缩小了特征图的同时,产生了如图大小为(4 imes4 imes(2k imes256))的模板帧特征([varphi(z)]_{c l s})和大小为(20 imes20 imes256)的检测帧特征([varphi(x)]_{c l s}),他们分别表示的含义是:模板帧特征大小是(4 imes4),而且它在k种不同的anchors有k中变化,对每种变化的模板都产生一个特征;检测帧特征大小是(20 imes20 imes256)。然后,以模板帧的特征作为卷积核(2k个(4 imes4 imes256))去卷积检测帧的特征从而产生响应图(A_{w imes h}^{c l s})。 回归分支和分类分支类似,不过它给出的是每个样本的位置回归值,这个位置回归值包含dx, dy, dw, dh四个值。
在训练过程中,用cross-entropy loss作为分类分支的损失函数,用smooth (L_{1})loss作为回归分支的损失函数。
关于损失函数的细节,待完全理解后补充。
端到端训练Siam-RPN:
从ILSVRC和Youtube-BB中的视频提取的样本对作为训练数据,用SGD方法对网络进行训练,同时也运用了一些数据增强处理。在细节方面,因为相同目标在相邻帧变化不会很大,作者采用一种尺度5种不同比例的anchors([0.33,0.5,1,2,3])(注意proposals如何从特征图映射到原图),同时将IoU>0.6的定为正样本,IoU<0.3的定为负样本;在一个训练对里最多有16个正样本且共有64个样本。
2. One-shot跟踪
one-shot检测:
该篇文章是第一次将one-shot策略用在跟踪任务中,这篇文章是讲如何实现one-shot learning的。最核心的思想方法就是通过离线训练的方法得到一个了learner net(文章里简称为learnet),然后通过在线的方式动态生成一个pupil net的参数,而且learnet只需要一张样本就可以生成pupil net的网络参数。Pupil net可以为分类器或者其他任务。为了简单起见,参数为动态生成的只有其中一层或者两层,如图所示,*代表有参数的层,红色的代表参数由learnet动态生成的。
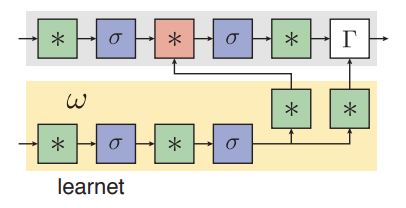
one-shot检测的任务是学习一个参数W使得预测函数(psi(x ; W))的平均损失(mathcal{L})最小,给定n个样本(mathcal{x}_{i})以及样本标签(ell_{i})。
针对跟踪问题,假设前向传播函数(omega)将(left(z ; W^{prime} ight))映射到W,其中(z_{i})是模板帧,上述公式可以变成如下公式,表示用模板帧图像学习用于跟踪的参数。
更进一步,(varphi)为Siam网络提取特征,(zeta)为RPN网络,则one-shot检测任务可以表示为:
将one-shot检测用到跟踪中:
如图所示,将上式可以做如下解释:
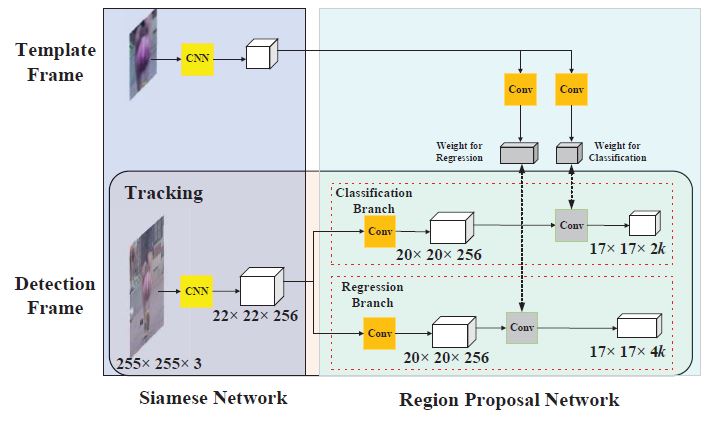
检测帧在对每一帧目标进行检测时就是对proposals进行分类,即相当于一个分类器。该分类器进行分类时需要一个响应得分图,该响应图是由检测帧特征图用模板帧特征图作为卷积核进行卷积得到的。如图灰色的方块,标识有weight for regression和weight for classification即为模板帧特征图,它用第一帧图像信息进行训练(即就是前文提到的one-shot检测,只用第一帧图像信息训练出一层网络的参数),然后将训练好的参数作为卷积核用到检测支中,对检测帧特征进行卷积得到响应图(大小为(17 iems17 iems2k))
作者将模板支的输出作为本地检测的卷积核,在整个跟踪过程中,卷积核参数都是用第一帧信息提前计算好的,当前帧跟踪可以看做如上图所示的one-shot检测,提取出检测支中得分前M的样本的分类输出信息(A_{w imes h imes 2 k}^{c l s}=left{left(x_{i}^{c l s}, y_{j}^{c l s}, c_{l}^{c l s} ight) ight})和回归输出信息(A_{w imes h imes 4 k}^{r e g}=left{left(x_{i}^{r e g}, y_{j}^{r e g}, d x_{p}^{r e g}, d y_{p}^{r e g}, d w_{p}^{r e g}, d h_{p}^{r e g} ight) ight})。根据输出信息,可以得到前M个proposals的位置信息(P R O^{*}=left{left(x_{i}^{ ext { pro }}, y_{j}^{ ext { pro }}, w_{l}^{ ext { pro }}, h_{l}^{ ext { pro }} ight) ight})
proposals的选择策略:
- 策略1:选择在目标周围(g imes g imes k)的anchors而不是在整个特征图上的(m imes n imes k)的anchors,如图g=7
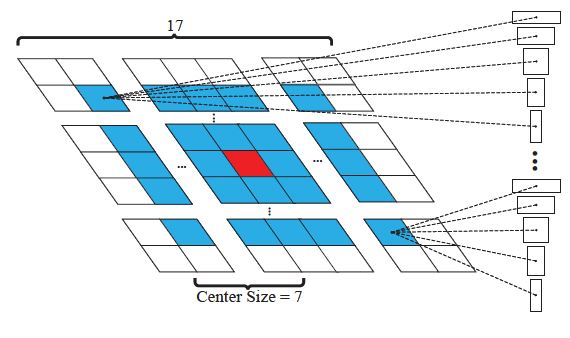
- 策略2:用cosine窗口和尺度变化penalty对剩下的proposals得分进行重新排序。在策略1执行并删除了离目标较远的proposals后,cosine窗口用于抑制最大位移,然后增加penalty以抑制尺寸和比例的大幅变化。最后选出得分最高的前K个proposals,并用NMS选出最终的跟踪目标位置。另外,在跟踪目标得到后,通过线性插值更新目标尺寸,保持形状平稳变化。
此部分待看完代码后详细补充。
四、实验结果
作者对比了VOT2015、VOT2016和VOT2017实时、以及OTB2015。实验环境是Intel i7、12G RAM、Nvidia GTX1060。
1. VOT结果
VOT2015结果:
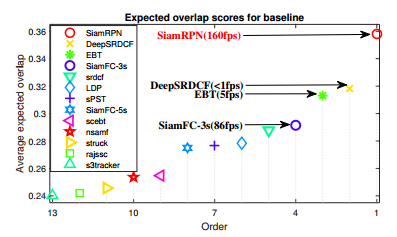
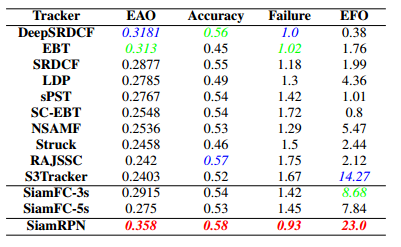
VOT2016结果:
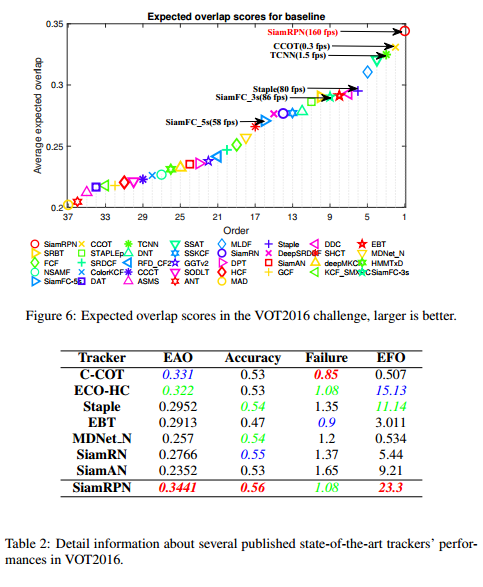
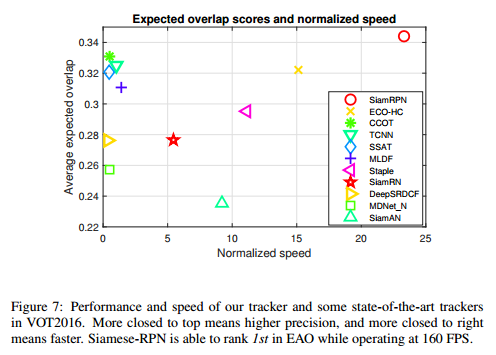
VOT2017结果:
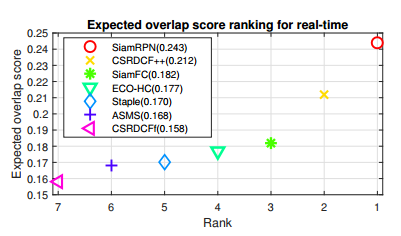
2. OTB2015结果
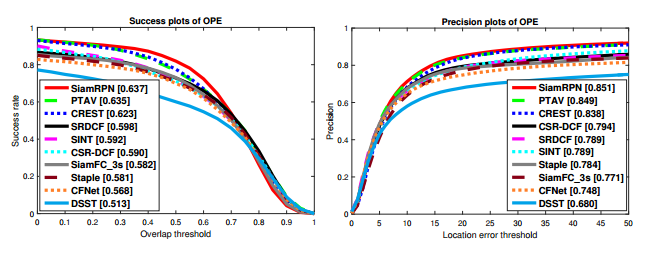
可以看到Siam-RPN在VOT和OTB上效果都挺好的。
3. 讨论
作者针对训练数据对模型效果的影响和anchors的选择两个方面进行了讨论,结果表明:
- 训练模型的数据量越大,训练的模型效果越好。
- 不同尺度的anchors对模型效果有一定影响,在目标周围不同大小区域提取proposals对模型效果也有一定影响。
五、相关链接
原文链接:原文链接
代码链接:代码链接
相关算法链接:Learning feed-forward one-shot learners
版权声明:本文为博主原创文章,未经博主允许不得转载。