一、概念
1、分区:
Hadoop默认分区是根据key的hashCode对ReduceTask个数取模得到的,用户无法控制哪个key存储到哪个分区。
想要控制哪个key存储到哪个分区,需要自定义类继承Partitioner<KEY, VALUE>,
泛型KEY, VALUE分别对应Mapper里的输出key,value,因为分区是在map()之后,环形缓冲区溢写时完成的。
提示:如果ReduceTask的数量大于自定义类中重写的getPartition()设置的分区数时,会产生空的输出文件part-r-00000
如果ReduceTask的数量小于自定义类中重写的getPartition()设置的分区数时,有一部分分区数据无处安放,就会报错
如果ReduceTask的数量等于1,则不会走自定义的分区方法,系统默认分区就是1,最终只会输出一个分区文件
分区号必须从0开始,逐一增加
2、全排序:
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,
因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
二、项目举例
1、待处理文本
data.txt
2、需求:
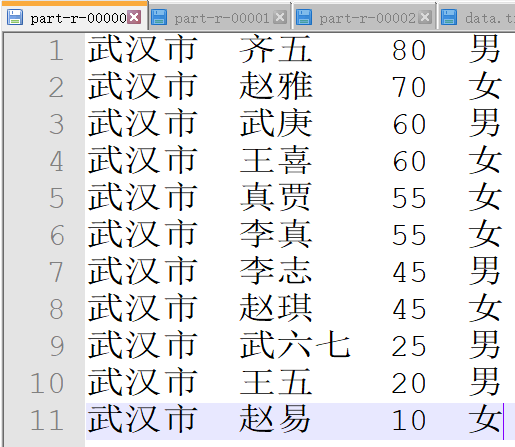
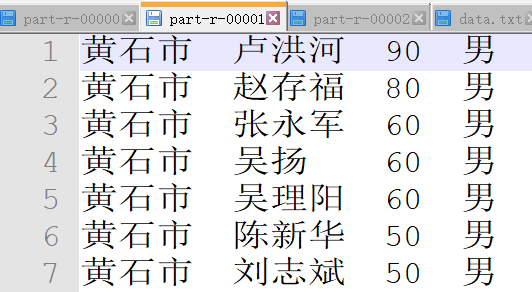
分别统计出各市感染人员信息,输出到对应文件中(说明:武汉的人员信息统一输出到一个文件,十堰的人员信息统一输出到一个文件),
输出结果按照感染人员的年龄做倒叙排列。输出结果举例:
地区 姓名 年龄 性别
武汉 张三 70 女
武汉 李四 50 男
武汉 王五 60 女
武汉 赵六 55 男
3、Person2Bean.java

package com.jh.work8; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class Person2Bean implements WritableComparable<Person2Bean> { private String area; // 感染地区 private String name; // 感染姓名 private Integer age; // 感染年龄 private String sex; // 感染性别 public Person2Bean() { } @Override public String toString() { return area + " " + name + " " + age + " " + sex; } public String getArea() { return area; } public void setArea(String area) { this.area = area; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } // 排序 @Override public int compareTo(Person2Bean o) { // 按感染年龄倒序排序(这里主要是区内排序) return o.getAge().compareTo(this.age); } // 序列化 @Override public void write(DataOutput out) throws IOException { out.writeUTF(area); out.writeUTF(name); out.writeUTF(sex); out.writeInt(age); } // 反序列化 @Override public void readFields(DataInput in) throws IOException { area = in.readUTF(); name = in.readUTF(); sex = in.readUTF(); age = in.readInt(); } }
4、Person2Mapper.java
package com.jh.work8; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class Person2Mapper extends Mapper<LongWritable,Text,Person2Bean,NullWritable> { private Person2Bean bean = new Person2Bean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 取文本每行内容,并分割 String[] split = value.toString().split(" "); // 赋值 bean.setArea(split[0]); bean.setAge(Integer.parseInt(split[1])); bean.setSex(split[2]); bean.setName(split[3]); context.write(bean,NullWritable.get()); } }
5、PersonPartition.java
package com.jh.work8; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Partitioner; public class PersonPartition extends Partitioner<Person2Bean,NullWritable> { /* 自定义分区,继承Partitioner 泛型对应Mapper端的输出 */ @Override public int getPartition(Person2Bean person2Bean, NullWritable nullWritable, int numPartitions) { // 根据感染地区做三个分区 switch (person2Bean.getArea()){ case "武汉市": return 0; case "黄石市": return 1; default: return 2; } } }
6、Person2Reduce.java
package com.jh.work8; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class Person2Reduce extends Reducer<Person2Bean,NullWritable,Person2Bean,NullWritable> { @Override protected void reduce(Person2Bean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { // 输出所有 for (NullWritable value : values) { context.write(key,NullWritable.get()); } } }
7、Person2Driver.java
package com.jh.work8; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class Person2Driver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 获取配置文件和job对象 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 设置jar的路径 job.setJarByClass(Person2Driver.class); // 设置mapper类和reducer类 job.setMapperClass(Person2Mapper.class); job.setReducerClass(Person2Reduce.class); // 设置mapper输出的key和value的数据类型 job.setMapOutputKeyClass(Person2Bean.class); job.setMapOutputValueClass(NullWritable.class); // 设置reduce输出的key和value的数据类型 job.setOutputKeyClass(Person2Bean.class); job.setOutputValueClass(NullWritable.class); // 设置自定义分区的类 job.setPartitionerClass(PersonPartition.class); // 设置ReduceTask的数量 job.setNumReduceTasks(3); // 设置要处理文件的输入路径 FileInputFormat.setInputPaths(job,new Path(args[0])); // 设置计算完毕后的数据文件的输出路径 FileOutputFormat.setOutputPath(job,new Path(args[1])); // 提交计算任务(job) boolean result = job.waitForCompletion(true); System.exit(result ? 0:1); } }
8、最终输出为三个文件: