#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __author__:anxu.qi
# Date:2018/11/30
info = {
'stu1101': "TengLan Wu",
'stu1102': "LongZe Luola",
"stu1103": "XiaoZe Maliya",
}
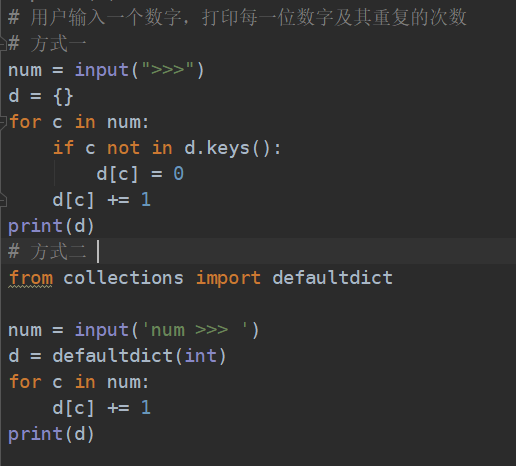
############################ 字典 dict ##################################
key-value 键值对的数据的集合
可变的、无序的、key不重复
字典是无序的
字典的 key 是按照哈希来进行保存的,所以字典的key一定要能被哈希,被哈希就是不可变的。
注:字典的key不能是:列表,字典
字典的value 可以是任意值
# 字典的每一个元素,都是键值对, 而且是无序的
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
## 索引
# print(user_info['age'])
# 30
## 切片没有
自定定义:两种方式都可以,推荐使用第一种
字典定义 dict 定义 初始化
d = dict() 或者 d = {}
dict(**kwargs) 使用 name=value 初始化一个字典
dict(iterable,**kwarg) 使用可迭代对象和name=value对 来构造字典 。
不过可迭代对象必须是一个二元结构。
d = dict(((1,'a'),(2,'b')) 或者 d = dict(([1,'a'],[2,'b']))




####################################### 多级字典的嵌套示例 #############################################
# key 尽量不要写中文,因为有时候编码不一致,取不出来值
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] = "可以再国内做镜像"
print(av_catalog)
# 打印所有的值 values()
print(av_catalog.values())
# 打印所有的key keys()
print(av_catalog.keys())
# 字典是无序的,是没有下标的,可以根据key来获取具体的值
#################### 字典 查 #################################
print(info)
# {'stu1103': 'XiaoZe Maliya', 'stu1102': 'LongZe Luola', 'stu1101': 'TengLan Wu'}
# 方式一:
print(info["stu1101"]) # info 存在则不会报错,不存在就会报错
# 方式二:
print(info.get("stu110113")) # get 有就返回该值,没有这个值就返回None
# None
# TengLan Wu
# 方式三: in
print("stu1103" in info) # 等与 python2.x info.has_key("stu1103")
#################### 字典 改 #################################
info["stu1101"] = "武藤兰" # 存在直接替换
print(info)
# {'stu1102': 'LongZe Luola', 'stu1101': '武藤兰', 'stu1103': 'XiaoZe Maliya'}
#################### 合并更新 update ####################################
a = {
'stu01':"nginx",
'stu02':"mysql",
'stu03':'zabbix'
}
b = {
'stu01':"tami",
1:3,
2:5
}
a.update(b)
print(a)
# {'stu03': 'zabbix', 'stu02': 'mysql', 2: 5, 'stu01': 'tami', 1: 3}
# 把b作为一个参数传为了update,把两个字典合并,如果a字典中有和b字典中相同的key,则覆盖a中的value
# 如果没有这个kye那么,将b中的key和value都添加到a字典中
#################### 字典 增 ##################################
info["stu1104"] = "CangJingkong" # 不存在则创建一条
print(info)
# {'stu1104': 'CangJingkong', 'stu1102': 'LongZe Luola', 'stu1101': '武藤兰', 'stu1103': 'XiaoZe Maliya'}
# 创建一个新的值 ,去字典里能取到我就返回,如果取不到我就设置一个新的。
av_catalog.setdefault("TaiWan", {"www.baiddu.com":[1, 2]})
#################### 字典 删 ##################################
# 方式一:
del info["stu1101"]
print(info)
# {'stu1104': 'CangJingkong', 'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
# 方式二:
info.pop("stu1102") # 删除指定的元素,并可以拿到结果
print(info)
# {'stu1103': 'XiaoZe Maliya', 'stu1104': 'CangJingkong'}
# 方式三: 随机删除一个元素,并可以拿到结果
info.popitem()
print(info)
# {'stu1103': 'XiaoZe Maliya'}
c = {
'stu01': "tami",
1: 3,
2: 5
}







# 只能等遍历时,收集好对应的key或者是value,再做处理

##################### for 循环 #################
# 循环字典的key 和 value
# 注:以下方式一和方式二的区别:结果都是一样的,但是方式一比方式二高效很多,
# 因为方式一只是通过key,找到key和value,方式二是将字典转换为列表后,通过key,value找到对应的值
# 数据量不大还可以,数据量大的情况下非常占用资源费时间。
# 方式一:
for i in a:
print(i,a[i])
# stu03 zabbix
# stu01 nginx
# stu02 mysql
# 方式二:
for k,v in a.items():
print(k,v)
# stu03 zabbix
# stu01 nginx
# stu02 mysql
######################## keys #######################
# 加上keys后,会输出所有的key
for i in user_info.keys():
print(i)
"""
gender
name
age
"""
######################## values #######################
# 加上values后,会输出所有的value
for i in user_info.values():
print(i)
"""
Vmiss
Vsidaodeng
V30
"""
######################## items #######################
# 加上items 后,会输出所有的item
for k,v in user_info.items():
print(k,v)
"""
Kname Vsidaodeng
Kgender Vmiss
Kage V30
"""
##########################################################
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
# 获取字典的所有的key
print(user_info.keys())
# dict_keys(['age', 'gender', 'name'])
# 获取字典的所有的值
print(user_info.values())
# dict_values([30, 'M', 'sidaodeng'])
# 获取字典所有的键值对
print(user_info.items())
# dict_items([('age', 30), ('name', 'sidaodeng'), ('gender', 'M')])
################################ del 删除 ##################################################
# 删除字典中的某个键值对
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
del user_info['Kage'] # 指定key,可以直接进行删除
print(user_info,11110000000)
# {'Kname': 'Vsidaodeng', 'Kgender': 'Vmiss'} 11110000000
############################### clear 清空字典 ##########################################
# def clear(self): # real signature unknown; restored from __doc__
# 清除所有内容
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
user_info.clear()
print(user_info)
# {} # 返回一个空字典
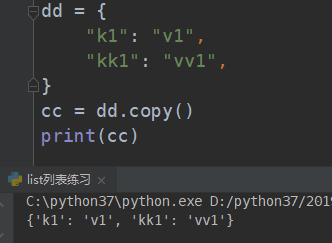
############################### copy 浅复制 ##########################################
# def copy(self): # real signature unknown; restored from __doc__
# 浅copy
举例:
# ##################### 静态方法:fromkeys #####################
# 初始化一个字典,并附一个临时的值,和浅copy 类似,只copy一层。
d = dict.fromkeys([6,7,8]) #根据序列,创建字典
d = dict.fromkeys([6,7,8],[100])
注:如果后面是引用类型,那么都是copy的门牌号
print(d)
# {8: None, 6: None, 7: None}
d = dict.fromkeys([6,7,8],"test")
print(d)
# {8: 'test', 6: 'test', 7: 'test'}
d = dict.fromkeys([6,7,8],[1,{"name":"alex"},444])
print(d)
# {8: [1, {'name': 'alex'}, 444], 6: [1, {'name': 'alex'}, 444], 7: [1, {'name': 'alex'}, 444]}
d[7][1]['name'] = "Jack wang"
print(d)
# {8: [1, {'name': 'Jack wang'}, 444], 6: [1, {'name': 'Jack wang'}, 444], 7: [1, {'name': 'Jack wang'}, 444]}
# ##################### get 方法 #####################
根据key获取值,key不存在时,并制定默认值为None
def get(self, *args, **kwargs): # real signature unknown
""" Return the value for key if key is in the dictionary, else default. """
pass

############################### get 获取值 ##########################################
# def get(self, k, d=None): # real signature unknown; restored from __doc__
# 根据key获取值,如果key不存在,可以指定一个默认值。d是默认值
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
aa = user_info.get('Kname') # 如果有这个值,就会打印出来value值
print(aa)
# Vsidaodeng
aa = user_info.get('Knameadasfad') # 如果没有这个kye,就会打印None,但是不会报错
print(aa)
# None
# get 添加默认值
aa = user_info.get('Kage','123') # 如果存在这个key,就会将对应的value打印出来
print(aa,1111)
# V30 1111
aa = user_info.get('Kage111','123') # 如果没有aeg111这个key,那么就会给一个默认值123
print(aa)
# 123
注:get是获取,不会改变原来的字典
# 通过索引也可以取,如果没有这个key,就会报错
# 所以,推荐使用,get("key") 来获取。
############################### in 是否存在 ##########################################
# 是检查字典中否有对应的key
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
aaaa = 'Kname' in user_info.keys()
print(aaaa)
# True
aaaa = 'Kname1231' in user_info.keys()
print(aaaa)
# False
############################### iteritems ##########################################
# def iteritems(self): # real signature unknown; restored from __doc__
# 项可迭代
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
# 先不说,后期补充
############################### pop 移除 ##########################################
# def pop(self, k, d=None): # real signature unknown; restored from __doc__
# 获取某个key,并在字典中移除掉
注:pop 出来的是一个value,不是k,v对。

user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
bb = user_info.pop('Kage')
print(bb)
# V30
print(user_info)
# {'Kgender': 'Vmiss', 'Kname': 'Vsidaodeng'}
#
############################### popitem 随机移除 ##########################################
# def popitem(self): # real signature unknown; restored from __doc__
返回一个二元组 ,
可以使用 k,v = d.popitem

# 获取并在字典中移除,随机移除。
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
bbbb = user_info.popitem()
print(bbbb)
"""
('Kage', 'V30')
('Kgender', 'Vmiss')
('Kname', 'Vsidaodeng')
"""
############################### setdefault 设置值 ##########################################
# def setdefault(self, k, d=None): # real signature unknown; restored from __doc__
# 设置值,但是如果已经存在,则不设置,并获取当前key对应的值
如果不存在,会进行添加,并获取已经添加的值
# 如果key不存在,则创建,如果存在,则返回已存在的值且不修改
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
############################### update 更新 ##########################################
# def update(self, E=None, **F): # known special case of dict.update
# 批量更新

# 已经存在的更新掉,不存在的则添加
方式二:
user_info = {
"Kname":"Vsidaodeng",
"Kage":"V30",
"Kgender":"Vmiss"
}
he = {
"a":1,
"b":2,
"c":3
}
user_info.update(he)
print(user_info)
# {'b': 2, 'Kgender': 'Vmiss', 'Kage': 'V30', 'a': 1, 'c': 3, 'Kname': 'Vsidaodeng'}
########################### update 添加 #############################################
he = {
"a":1,
"b":2,
"c":3
}
# 方式一:
he.update({"d":4})
print(he)
# {'b': 2, 'c': 3, 'd': 4, 'a': 1}
# 方式二:
he["e"]=5
# print(he)
# {'b': 2, 'c': 3, 'd': 4, 'a': 1}
举例说明:
ttt = (11,22,["alex",{"k1":"v1"}])
ttt[2][1]["k2"] = "v2" # 方式一等同于下面的方式二
ttt[2][1].update({"k2":"v2"}) # 方式二
print(ttt)
# (11, 22, ['alex', {'k2': 'v2', 'k1': 'v1'}])
字典dict 的key:
set 集合 的元素就可以看做key,set可以看做dict的简化版
hashable 可哈希才可以作为key,可以使用 hash() 测试
key 不允许重复
只要是将key用好了,就把字典用好了。