我们向一个HTTP的服务器发送HTTP的请求后,服务器会返回可能一个HTML页面(当然也可以是其他的资源),我们可以利用返回的HTML页面,在其中寻找其他的Url,例如我们可以这样在浏览器上查看一下HTML页面:
右键——>查看源代码
出现的页面大致如下:

我们可以看到,一个HTML的页面内容是想当多的,如果我们使用之前查找字符串的方法一行一行查找的话,效率是想当低下的。同时我们可以看到,大多数的Url例如
href=http://news.baidu.com是以href=开头的,以及例如
src="https://ss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/img/logo/logo_white_81d09391.png"以src开头。因此我们可以使用另一种手段达到比较高效的查找——正则表达式
C语言处理正则表达式常用的函数有regcomp()、regexec()、regfree()和regerror(),一般分为三个步骤,如下所示:
C语言中使用正则表达式一般分为三步:
编译正则表达式 regcomp()
匹配正则表达式 regexec()
释放正则表达式 regfree()
下边是对三个函数的详细解释
1、int regcomp (regex_t *compiled, const char *pattern, int cflags)
为了提高效率,在将一个字符串与正则表达式进行比较之前,首先要用regcomp()函数对它进行编译,将其转化为regex_t结构,这个函数把指定的正则表达式pattern编译成一种特定的数据格式compiled,这样可以使匹配更有效。函数regexec 会使用这个数据在目标文本串中进行模式匹配。执行成功返回0。
参数说明:
①regex_t 是一个结构体数据类型,用来存放编译后的正则表达式,它的成员re_nsub 用来存储正则表达式中的子正则表达式的个数,子正则表达式就是用圆括号包起来的部分表达式。
②pattern 是指向我们写好的正则表达式的指针。
③cflags 有如下4个值或者是它们或运算(|)后的值:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果。
REG_NEWLINE 识别换行符,这样’$’就可以从行尾开始匹配,’^’就可以从行的开头开始匹配。
2. int regexec (regex_t *compiled, char *string, size_t nmatch, regmatch_t matchptr [], int eflags)
当我们编译好正则表达式后,就可以用regexec 匹配我们的目标文本串了,如果在编译正则表达式的时候没有指定cflags的参数为REG_NEWLINE,则默认情况下是忽略换行符的,也就是把整个文本串当作一个字符串处理。执行成功返回0。
regmatch_t 是一个结构体数据类型,在regex.h中定义:
typedef struct
{
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
成员rm_so 存放匹配文本串在目标串中的开始位置,rm_eo 存放结束位置。通常我们以数组的形式定义一组这样的结构。因为往往我们的正则表达式中还包含子正则表达式。数组0单元存放主正则表达式位置,后边的单元依次存放子正则表达式位置。
参数说明:
①compiled 是已经用regcomp函数编译好的正则表达式。
②string 是目标文本串。
③nmatch 是regmatch_t结构体数组的长度。
④matchptr regmatch_t类型的结构体数组,存放匹配文本串的位置信息。
⑤eflags 有两个值
REG_NOTBOL 按我的理解是如果指定了这个值,那么’^’就不会从我们的目标串开始匹配。总之我到现在还不是很明白这个参数的意义;
REG_NOTEOL 和上边那个作用差不多,不过这个指定结束end of line。
3. void regfree (regex_t *compiled)
当我们使用完编译好的正则表达式后,或者要重新编译其他正则表达式的时候,我们可以用这个函数清空compiled指向的regex_t结构体的内容,请记住,如果是重新编译的话,一定要先清空regex_t结构体。
4. size_t regerror (int errcode, regex_t *compiled, char *buffer, size_t length)
当执行regcomp 或者regexec 产生错误的时候,就可以调用这个函数而返回一个包含错误信息的字符串。
参数说明:
①errcode 是由regcomp 和 regexec 函数返回的错误代号。
②compiled 是已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
③buffer 指向用来存放错误信息的字符串的内存空间。
④length 指明buffer的长度,如果这个错误信息的长度大于这个值,则regerror 函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。所以我们可以用如下的方法先得到错误字符串的长度。
size_t length = regerror (errcode, compiled, NULL, 0);
该爬虫里所使用正则表达式字符串如下:
static const char * HREF_PATTERN = "href="\s*\([^ >"]*\)\s*"";在一个模块中还有一个是下面这样的:
static const char * IMG_PATTERN = "<img [^>]*src="\s*\([^ >"]*\)\s*"";说说第一个,第二个差不多。
href="\s*\([^ >"]*\)\s*"里面很多的‘’是用来转义的,因为本身字符串在双括号里面,s表示一个空格,*表示1个或者多个匹配,当前的意思是一个或者多个空格是正常的字符,而且这里前后都有,\(前面一个表示转义,这个的意思是后面带一个(括号,子正则表达式就是用圆括号包起来的部分表达式,[^ >”],在方括号中的^,应该是不包含的意思,就是不包含>和引号,因为我们所使用的这句字符所匹配的字符串查找出来的主正则表达式应该是下面这样的:
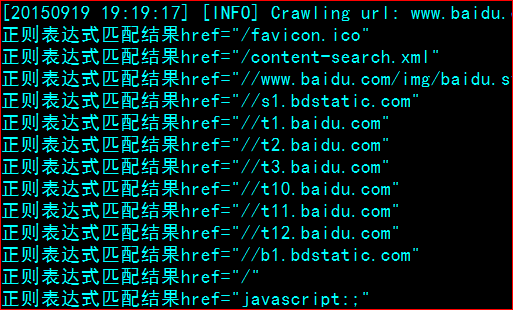
而我们要的url其实不含href=“”这样的字符,所以应该去掉,借用子正则表达式来处理
该爬虫里面使用了下面的处理来获取url
while (regexec(re, p, nmatch, matchptr, 0) != REG_NOMATCH)//匹配所有能够匹配的
{//这样操作可以去掉href,matchptr[1]是子正则表达式,matchptr[0]是主正则表达式,我们要的是子正则表达式的部分
len = (matchptr[1].rm_eo - matchptr[1].rm_so);//长度
p = p + matchptr[1].rm_so;
char *tmp = (char *)calloc(len+1, 1);
strncpy(tmp, p, len);
tmp[len] = '�';
// printf("正则表达式匹配结果%s
", tmp);
p = p + len + (matchptr[0].rm_eo - matchptr[1].rm_eo);//更新下要匹配的字符串
……
……
……我们要的是不含引号的子正则表达式,所以应该是matchptr[1],matchptr[1].rm_eo 是开头, matchptr[1].rm_so结尾
其实这样的操作不能获取HTML页面的所有Url,因为还存在很多其他的情况,例如:
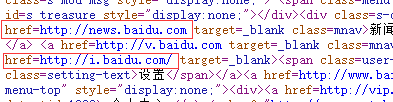
不是所有的href后面都有双引号,还有其他很多的情况。所以说这个爬虫的功能是相当单一的。
保存页面只实现了保存HTML和图片,分别用两个动态模块实现。
在使用正则表达式获取了原始Url后,就使用下面的语句,调用动态模块实现保存:
for (i = 0; i < (int)modules_post_html.size(); i++)
{
SPIDER_LOG(SPIDER_LEVEL_WARN, "保存文件");
modules_post_html[i]->handle(resp);//此模块就是保存文件的
}
下面看看两个模块
savehtml.cpp
#include "dso.h"
#include "socket.h"
#include <fcntl.h>
#include <stdlib.h>
#include "spider.h"
static int handler(void * data)
{
SPIDER_LOG(SPIDER_LEVEL_WARN, "保存HTML文件");
Response *r = (Response *)data;
//确认类型
if (strstr(r->header->content_type, "text/html") == NULL)
return MODULE_ERR;
char *fn = url2fn(r->url);
int fd = -1;
if ((fd = open(fn, O_WRONLY|O_CREAT|O_TRUNC, 0666)) < 0) //以fn为文件名
{
return MODULE_ERR;
}
int left = r->body_len;
int n = -1;
while (left) //一直写直到写完
{
if ((n = write(fd, r->body, left)) < 0)
{
// error
close(fd);
unlink(fn);//unlink()会删除参数pathname指定的文件
free(fn);
return MODULE_ERR;
}
else
{
left -= n;
}
}
close(fd);
free(fn);
SPIDER_LOG(SPIDER_LEVEL_WARN, "保存HTML文件完成");
return MODULE_OK;
}
static void init(Module *mod)
{
SPIDER_ADD_MODULE_POST_HTML(mod);
}
//这里的模块名称和最后生成的.so的名称,已经在加载的时候使用的那个名称一定要相同
Module savehtml =
{
STANDARD_MODULE_STUFF,
init,
handler
};
在确认类型之后便是使用write函数写入文件
saveimage.cpp
#include "dso.h"
#include "socket.h"
#include "url.h"
#include <fcntl.h>
#include <stdlib.h>
#include "spider.h"
// 解析src的正则表达式
static const char * IMG_PATTERN = "<img [^>]*src="\s*\([^ >"]*\)\s*"";
static int handler(void * data)
{
Response *r = (Response *)data;
const size_t nmatch = 2;
regmatch_t matchptr[nmatch];
int len;
regex_t re;
if (strstr(r->header->content_type, "text/html") != NULL)//找到text/html这个类型
{
SPIDER_LOG(SPIDER_LEVEL_WARN, "saveimage正则匹配");
if (regcomp(&re, IMG_PATTERN, 0) != 0)
{//正则表达式编译错误
return MODULE_ERR;
}
char *p = r->body;
while (regexec(&re, p, nmatch, matchptr, 0) != REG_NOMATCH)
{
len = (matchptr[1].rm_eo - matchptr[1].rm_so);
p = p + matchptr[1].rm_so;
char *tmp = (char *)calloc(len+1, 1);
strncpy(tmp, p, len);
tmp[len] = '�';
p = p + len + (matchptr[0].rm_eo - matchptr[1].rm_eo);
char *url = attach_domain(tmp, r->url->domain);//attach_domain在url.cpp
//printf("加上域名后的Url%s
", url);
if (url != NULL)
{
Surl * surl = (Surl *)malloc(sizeof(Surl));
surl->level = r->url->level;
surl->type = TYPE_IMAGE;
// normalize url
if ((surl->url = url_normalized(url)) == NULL)
{
free(surl);
continue;
}
if (iscrawled(surl->url))
{ // if is crawled 已经抓取过
free(surl->url);
free(surl);
continue;
}
else
{
SPIDER_LOG(SPIDER_LEVEL_WARN, "%s加入原始队列",surl);
push_surlqueue(surl);
}
}
}
}
else if (strstr(r->header->content_type, "image") != NULL)
{
SPIDER_LOG(SPIDER_LEVEL_WARN, "保存二进制文件");
char *fn = url2fn(r->url);
int fd = -1;
if ((fd = open(fn, O_WRONLY|O_CREAT|O_TRUNC, 0666)) < 0)
{
return MODULE_ERR;
}
// save image
int left = r->body_len;
int n = -1;
while (left)
{
if ((n = write(fd, r->body, left)) < 0)
{
// error
close(fd);
unlink(fn);
free(fn);
return MODULE_ERR;
}
else
{
left -= n;
}
}
close(fd);
free(fn);
SPIDER_LOG(SPIDER_LEVEL_WARN, "保存二进制文件成功");
return MODULE_OK;
}
}
static void init(Module *mod)
{
SPIDER_ADD_MODULE_POST_HTML(mod);
}
Module saveimage = {
STANDARD_MODULE_STUFF,
init,
handler
};
这里还处理了另一种情况,以src开头的Url,然后匹配类型,写入文件
上面两个模块便是所谓的持久化器,因为将资源用文件的形式保存了下来。
下面还有另一函数
//加上域名
//参数为:正则表达式匹配到的结果,原来url的域名
char * attach_domain(char *url, const char *domain)
{
if (url == NULL)
return NULL;
//这里情况其实是比较复杂的
if (strncmp(url, "http", 4) == 0)//以http开头,表示已经有完整的域名了
{
return url;
}
else if(strncmp(url, "www", 3) == 0)
{
return url;
}
else if(strncmp(url, "//www", 5) == 0)
{
int j=0;
int len = strlen(url);
char *tmp1 = (char *)malloc(len+1);
for(j=2;j < len;j++)
{
tmp1[j-2] = url[j];
}
free(url);
SPIDER_LOG(SPIDER_LEVEL_DEBUG, "新组装的url:%s",tmp1);
return tmp1;
}
else if(*url == '/')//不是完整的url,补充域名,这里可能会出现一些错误的情况,可能多一个'/',或者原来是以www开头
{
int i;
int ulen = strlen(url);
int dlen = strlen(domain);
char *tmp = (char *)malloc(ulen+dlen+1);
for (i = 0; i < dlen; i++)
tmp[i] = domain[i];
for (i = 0; i < ulen; i++)
tmp[i+dlen] = url[i];
tmp[ulen+dlen] = '�';
free(url);
return tmp;
}
else//其他情况
{
//do nothing
free(url);
return NULL;
}
}因为HTML页面中的url情况是多样的,有些并没有完整的域名,这时我们需要帮其加上,有些还存在这种情况

这种出现两斜杠的情况我们这里也要处理一下,还有其他的情况,这里就没有实现了,可以自己扩展。
因为文件名不支持‘/’,所以不能直接使用url作为文件名,把斜杠替换成其他的字符即可,可以参考下面的函数
//生成url写到文件的文件名
char * url2fn(const Url * url)
{
int i = 0;
int l1 = strlen(url->domain);
int l2 = strlen(url->path);
char *fn = (char *)malloc(l1+l2+2);
for (i = 0; i < l1; i++)
fn[i] = url->domain[i];//写域名
fn[l1++] = '_';//在域名后面加上'_',所以下载的时候域名末尾都有个'_'
for (i = 0; i < l2; i++)
fn[l1+i] = (url->path[i] == '/' ? '_' : url->path[i]);//路径的'/'号换为'_'
fn[l1+l2] = '�';
return fn;
}