转载自:https://www.cnblogs.com/lixinjie/p/a-reactive-streams-on-jvm-is-reactor.html
响应式编程
作为响应式编程方向上的第一步,微软在.NET生态系统中创建了Rx库(Reactive Extensions)。RxJava是在JVM上对它的实现。
响应式编程是一个异步编程范式,通常出现在面向对象的语言中,作为观察者模式的一个扩展。
它关注数据的流动、变化的传播。这意味着可以轻易地使用编程语言表示静态(如数组)或动态(如事件发射源)数据流。
响应式流
随着时间的推移,一个专门为Java的标准化出现了。它是一个规范,定义了一些接口和交互规则,用于JVM平台上的响应式库。
它就是响应式流(Reactive Streams),它的这些接口已经被集成到Java 9里,在java.util.concurrent.Flow这个父类里。
响应式流和迭代器较相似,不过迭代器是基于“拉”(pull)的,而响应式流是基于“推”(push)的。
迭代器的使用其实是命令式编程,因为由开发者决定什么时候调用next()获取下一个元素。
在响应式流中,与上面等价的是发布者-订阅者。但当有新的可用元素时,是由发布者推给订阅者的。这个“推”就是响应式的关键所在。
另外,对被推过来元素的操作也是以声明的方式进行的,程序员只需表达做什么就行了,不需要管怎么做。
发布者使用onNext方法向订阅者推送新元素,使用onError方法告知一个错误,使用onComplete方法告知已经结束。
可见,错误处理和完成(结束)也是以一个良好的方式被处理。错误和结束都可以终止序列。
这种方式非常灵活。这种模式支持0个(没有)元素/1个元素/n(多)个元素(包括无限序列,如果滴答的钟表)这些情况。
Reactor粉墨登场
Reactor是第四代响应式库,是一个响应式编程范式的实现,用于在JVM平台上基于响应式流规范构建非阻塞异步应用。
它极大地实现了JVM上响应式流的规范(http://www.reactive-streams.org/)。
它是一个完全非阻塞响应式编程的基石,带有高效需求管理(以管理“后压”的形式)。
它直接集成Java函数式API,特别是CompletableFuture,Stream和Duration。
它支持使用reactor-netty工程实现非阻塞跨进程通信,适合微服务架构,支持HTTP(包括Websockets),TCP和UDP。
注:Reactor要求Java 8+
讲了这么多,是不是要首先思考下,为什么我们需要这样一个异步的响应式库?
阻塞就是浪费
现代的应用能达到非常多的并发用户,即使现代硬件的能力被持续改进,现代软件的性能仍然是一个关键的关注点。
大体上有两种方式可以改进一个程序的性能:
1、并行化,使用更多的线程和更多的硬件资源
2、提高效率,在当前资源用量的情况下寻求更高效率
通常,Java开发者使用阻塞代码来写程序。这种实践性很好,直到遇到性能瓶颈。
此时会引入额外线程,运行相似的阻塞代码。但是这种扩展方法在资源利用方面会引起争论和导致并发问题。
更糟糕的是,阻塞浪费资源。如果你仔细看,一旦一个程序涉及到一些延迟(特别是I/O,像数据库请求或网络调用),资源就被浪费,因为线程现在是空闲的,在等待数据。
所以并行化方式不是银弹。我们有必要让硬件发挥完全的力量,但是关于资源浪费的影响和原因也是非常复杂的。
异步性来营救
前面提到的第二种方式是寻求更高效率,可以作为资源浪费问题的一个解决方案。
通过写异步非阻塞代码,你能让执行切换到其它活动的任务,使用相同的底层资源,稍后再回到当前的处理上。
但是如何产生异步代码到JVM上呢?Java提供两种异步编程模型:
1、Callbacks,异步方法没有返回值,但是会带一个回调,当结果可用时回调会被调用。
2、Futures,异步方法立即返回一个Future<T>,异步处理过程就是计算一个T值,使用Future对象包装了对它的访问。这个值不是立即可用的,该对象可以被轮询来查看T值是否可用。
这两种技术都足够好吗?并不是对每种情况都是的,两种方式都有局限性。
回调比较难于组合在一起,很快就会导致代码难以阅读和维护(众所周知的“回调地狱”)。
看个回调示例,展示一个用户的前5个最爱,如果没有的话就推荐5个给他:
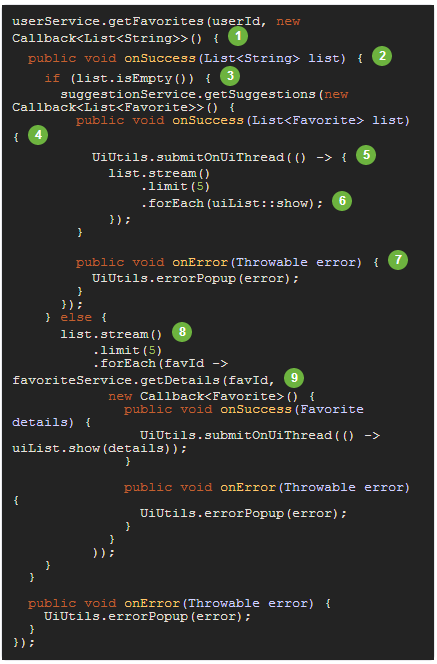
这么简单的功能需要如此多的代码,而且嵌套很多、且难懂。
下面是等价的用Reactor的示例:
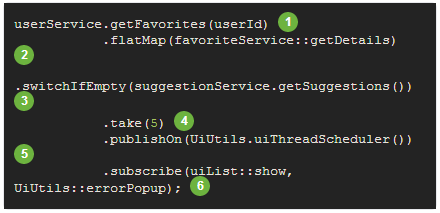
从代码的数量、写法上是不是清爽了很多。
与回调相比,Futures稍微好一点,但是仍然在组合方面做得不好。组合多个Futures对象到一起是可行的但是并不容易。
Future也有其它问题,很容易因为调用了get()方法造成了另一个阻塞。
另外,它不支持延迟计算,缺乏对多个值的支持,缺乏高级错误处理。
从命令式到响应式编程
像Reactor这样的响应式库的目标就是解决在JVM上“传统”异步方式的弊端,同时也关注一些额外方面:
可组合性和可读性
数据作为流,被丰富的操作符操作
什么都不会发生,直到你订阅
后压,消费者通知生产者发射的速率太快了
高级别而不是高数值抽象
可组合性和可读性
可组合性,其实就是编排多个异步任务的能力,使前一个任务的结果作为后续任务的输入,或以fork-join(分叉-合并)的方式执行若干个任务,或在更高的级别重复利用这些异步任务。
任务编排的能力和代码的可读性和可维护性紧密地耦合在一起。随着异步处理在数量和复杂度上的增加,组合和阅读代码变得更加困难。
就像我们看到的,回调模型虽然简单,但是当回调里嵌套回调,达到多层时就会变成回调地狱。
Reactor提供丰富的组合选项,使嵌套级别最小,让代码的组织结构能反映出在进行什么样的抽象处理,且通常保持在同级别上。
装配线类比
你可以认为响应式应用处理数据就像通过一个装配(生产)线。Reactor既是传送带又是工作站。
原材料从一个源(原始发布者)持续不断地获取,以一个完成的产品被推送给消费者(订阅者)结束。
原材料可以经过许多不同的转换,如其它的中间步骤,或者是一个更大装配线的一部分。
如果在某个地方出现一个小故障或阻塞了,出问题的工作站可以向上游发出通知来限制原材料的流动(速率)。
操作符
在Reactor里,操作符就是装配线类比中的工作站。每一个操作符都向一个发布者添加某些行为,把上一步的发布者包装到一个新的实例里。整个链就是这样被链接起来的。
所以数据一开始从第一个发布者出来,然后沿着链往下游移动,且被每一个链接转换。最后,一个订阅者结束了这个处理。
响应式流规范并没有明确规定操作符,不过Reactor就提供了丰富的操作符,它们涉及到很多方面,从简单的转换、过滤到复杂的编排、错误处理。
只要不订阅,就什么都不发生
当你写一个发布者链时,默认,数据是不会开始进入链中的。相反,你只是创建了异步处理的一个抽象描述。
通过订阅这个行为(动作),才把发布者和订阅者连接起来,然后才会触发数据在链里流动。
这是在内部实现好的,通过来自于订阅者的request信号往上游传播,一路逆流而上直到最开始的发布者那里。
Reactor核心特性
Reactor引入可组合响应式的类型,实现了发布者接口,但也提供了丰富的操作符,就是Flux和Mono。
Flux,流动,表示0到N个元素。
Mono,单个,表示0或1个元素。
它们之间的不同主要在语义上,表示异步处理的粗略基数。
如一个http请求只会产生一个响应,把它表示为Mono<HttpResponse>显然更有意义,且它只提供相对于0/1这样上下文的操作符,因为此时count操作显然没有太大意义。
操作符可以改变处理的最大基数,也会切换到相关类型上。如count操作符虽然存在于Flux<T>上,但它的返回值却是一个Mono<Long>。
Flux<T>
一个Flux<T>是一个标准的Publisher<T>,表示一个异步序列,可以发射0到N个元素,可以通过一个完成信号或错误信号终止。
就像在响应式流规范里那样,这3种类型的信号转化为对一个下游订阅者的onNext,onComplete,onError3个方法的调用。
这3个方法也可以理解为事件/回调,且它们都是可选的。
如没有onNext但有onComplete,表示一个空的有限序列。既没有onNext也没有onComplete,表示一个空的无限序列(没有什么实际用途,可用于测试)。
无限序列也没有必要是空的,如Flux.interval(Duration)产生一个Flux<Long> ,它是无限的,从钟表里发射出的规则的“嘀嗒”。
Mono<T>
一个Mono<T>是一个特殊的Publisher<T>,最多发射一个元素,可以使用onComplete信号或onError信号来终止。
它提供的操作符只是Flux提供的一个子集,同样,一些操作符(如把Mono和Publisher结合起来)可以把它切换到一个Flux。
如Mono#concatWith(Publisher)返回一个Flux,然而Mono#then(Mono)返回的是另一个Mono。
Mono可以用于表示没有返回值的异步处理(与Runnable相似),用Mono<Void>表示。
创建Flux或Mono,并订阅它们
最容易的方式就是使用它们各自的工厂方法:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
当谈到订阅时,可以使用Java 8的lambda表达式,订阅方法有多种不同的变体,带有不同的回调。
下面是方法签名:
//订阅并触发序列
subscribe();
//可以对每一个产生的值进行处理
subscribe(Consumer<? super T> consumer);
//还可以响应一个错误
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
//还可以在成功结束后执行一些代码
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
//还可以对Subscription执行一些操作
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
使用Disposable取消订阅
这些基于lambda的订阅方法都返回一个Disposable类型,通过调用它的dispose()来取消这个订阅。
对于Flux和Mono,取消就是一个信号,表明源应该停止生产元素。然而,不保证立即生效,一些源可能生产元素非常快,以致于还没有收到取消信号就已经生产完了。