第四次C博客作业
Q0.展示PTA总分
-
一维数组

-
二维数组

-
字符数组

Q1.本章学习总结
1.1 学习内容总结
- 数组中数据的查询
- 遍历查找法:顾名思义,将数组中的数据都遍历一遍,如果数组都遍历完了则说明没有找到数据,反之即找到了目标数据
- 二分查找法:注意使用的前提是数组中的元素有序排列!如果不是有序排列则需要在查找前将数组排序。二分查找具体操作为:将数组正中间的元素与查找的数据比较,两者相等即为找到了,否则将数组分为左右两个部分,如果中间的元素大于查找的数据,则进一步查找左半部分,否则进一步查找右半部分,重复以上过程。
/*遍历查找和二分查找的简单样例:输出目标数据在数组中的位置*/
int a[5] = { 1,2,3,4,5 };
输入要查找的数据
for i=0 to 4 do //遍历查找法
if 查找的数据等于数组中当前下标的元素 then
输出i并结束循环
end if
end for
int left = 0, right = 4; //二分查找法。左部开始为0,右部开始为数组长度减一
int mid;
while left的值小于right //循环条件,如果left>right则说明没有找到目标数据
mid = (left + right) / 2; //这句是关键
if 查找的数据等于数组中当前下标的元素 then
输出i并结束循环
else if 查找的数据大于中间元素 then //如果没有找到则将左部或右部折半
left = mid + 1;
else
right = mid - 1;
end if
end while
- 数组中数据的插入
- 一个思路是将插入的数据和数组中已有的数据做比较,记录下比插入的数据大的数组元素的下标,将数据插入到该位置,再将后面所有的元素后移动一位
- 也可以将数据直接插入到数组的末尾,再与前面的元素逐个进行比较、交换的操作
/*插入新数据到数组中的简单样例*/
int a[6] = { 1,2,3,4,5 };
输入要插入的新数据insert
for i=0 to 4 do //寻找第几个元素比插入的数据大
if 当前的元素大于插入的数据 then
储存当前i为index并结束循环
end if
end for
for i=5 to index do //将index后的元素全部右移1位
a[i] = a[i - 1];
end for
a[index] = insert; //再将要插入的数据传给记录的位置
a[5] = insert; //先插末尾再排序的方法
for i=5 to 0 do
if a[i]的值小于a[i-1]的值 then
交换a[i]和a[i-1]
end if
end for
- 数组中数据的删除
- 可以遍历数组,当数组当前元素等于要删除的数据时直接将后面的元素全部左移1位,将该元素覆盖掉,从而实现删除
- 或是再定义一个数组,用来储存原数组中要留下的元素
/*删除数组中的元素的简单样例*/
int a[5] = { 1,2,3,4,5 };
输入要删除的数据del
for i=0 to 4 do
if 当前的元素等于要删除的数据 then
储存当前i为index并结束循环
end if
end for
for i=index to 4 do //将index后的元素全部左移1位
a[i] = a[i + 1];
end for
int b[5]; //再定义一个数组的方法
定义数组b的下标j,长度k,初值均为0
for i=0 to n do
if a[i]的值不等于要删除的值 then
b[j++]=a[i];
k++;
end if
end for
- 数组的排序
- 选择法:对数组中固定的一个位置和后面的所有元素逐个进行比较,它每轮会将最小的数放到最前
- 冒泡法:数组按顺序对两个相邻的元素进行比较,它每轮会将最大的数放到最后
- 用一张图表示一下它们的区别(画的都是第一轮比较)

/*冒泡排序和选择排序的简单样例*/
输入数组长度n;
输入n个数组元素;
for i=0 to n do //选择法排序
for j=i+1 to n do
if a[i]的值比a[j]的值大
交换a[i]和a[j]
for i=1 to n do //冒泡法排序,这个循环控制冒泡的次数
for j=0 to n-i do
if a[j]的值大于a[j+1]
交换a[j]和a[j+1]
- 数组做枚举用法
- 说实话我并没有看懂这个是什么意思,百度到的也都是enum的枚举类型,只能按我个人的理解写了
- 个人感觉是将数组的元素都列举出来,之后直接使用的意思,这里我直接用2840题库中的查找星期题目来做例子吧
#include <stdio.h>
#include <string.h>
#define MAXS 80
int getindex(char* s);
int main()
{
int n;
char s[MAXS];
scanf("%s", s);
n = getindex(s);
if (n == -1) printf("wrong input!
");
else printf("%d
", n);
return 0;
}
int getindex(char* s)
{
const char week[7][10] = { "Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday" }; //将所有元素都枚举出来,赋予week[0]到week[6],例如在后面使用week[5]即代表字符串Friday
int i;
for (i = 0; i < 7; i++)
{
if (strcmp(week[i], s) == 0) //比较输入的字符串是否与week数组中的元素相同
return i;
}
return -1;
}
- 哈希数组
-
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
-
引用自哈希表的百度百科
- 根据上面的资料我们可以知道哈希数组是按照一个key值直接访问该位置储存的元素(我的推测)
- 目前我们做过的跟哈希数组有关的题目例子:有重复的数据,就是直接将数据元素作为下标,直接查找里面的内容
- 一般的方法我们选择按顺序储存输入的内容,再通过遍历的方式来判断有无重复,但在这题中如果这样写,又遇到输入100000个不同数的极端情况,那么我们的循环要走100000x100000遍,导致运行超时,所以我们选择直接将输入的数据作为下标,元素内容为该数字出现的次数,当输入的数字出现次数超过1时即有重复数据,结束循环。这样子写即使遇到最极端的情况,循环也只需要走100000遍,运行的效率大大提高了
#include<stdio.h>
int main()
{
int a[100001] = { 0 }; //初始化数字1-100000的出现次数均为0
int n;
int i;
int num;
scanf("%d", &n);
for (i = 0; i < n; i++)
{
scanf("%d", &num);
a[num]++;
if (a[num] > 1) //如果这个数字出现超过1次即有重复数据,直接结束循环
{
printf("YES");
break;
}
}
if (i >= n) //如果上面这个循环能走完就说明没有重复数据
printf("NO");
return 0;
}
1.2 本章学习体会
- 数组对前面部分的内容的综合性较强,要求对循环、分支等结构内容要有一定的熟练度
- 题目的难度又又又提升了,但还是不能ctrl c+v,也最好不要说什么“我看看答案,看懂了就可以直接复制过来了”之类的话,如果不动手写的话真的很容易就忘了
(大脑:我懂了 手:不你不懂) - 个人认为数组的概念和使用部分并不难理解,只要稍加练习和思考都能做出来
- 遇到小问题试着问一下同学/老师,有时候就是一点小错误反而找不出来,别人一下就能发现,但也不能啥问题都一股脑的都丢给别人,别人看着讲的累,自己听的也累
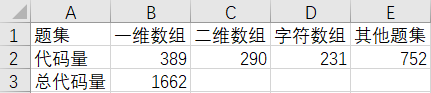
- 代码量统计(
题目太难了刷不上去了)
Q2.PTA实验作业
2.1 阅览室
2.1.1 伪代码
定义day记录要输入几天的数据
定义count记录当前为第几天
定义hour、minute、number、ch记录借书时间、书号、借出/归还
定义数组book行长1001,列长6,其中每列代表如下:0-S,1-E,2、4-借出去的时间,3、5-归还的时间
定义数组borrow、totaltime、avgtime记录每天借出去的书本数量、总阅读时间、平均阅读时间
输入总天数
for count=1 to day do
让book数组里的全部内容均为0
输入书号、借出/归还、小时、分钟
while 书号不为0 do
if 输入了S then
记录该书号S、借出的小时和分钟
end if
else if 输入了E且该书号之前有及记录过S then
记录该书号E、归还的小时和分钟
end if
if 该书号有同时记录S和E then
当天借书量+1
计算阅读时间加到当天总阅读时间内
清空该书号的S、E记录
end if
输入书号、借出/归还、小时、分钟
end while
if 该天的借书量不为0 then
计算平均阅读时间
end for
输出每天的借书量和平均阅读时间
return 0;
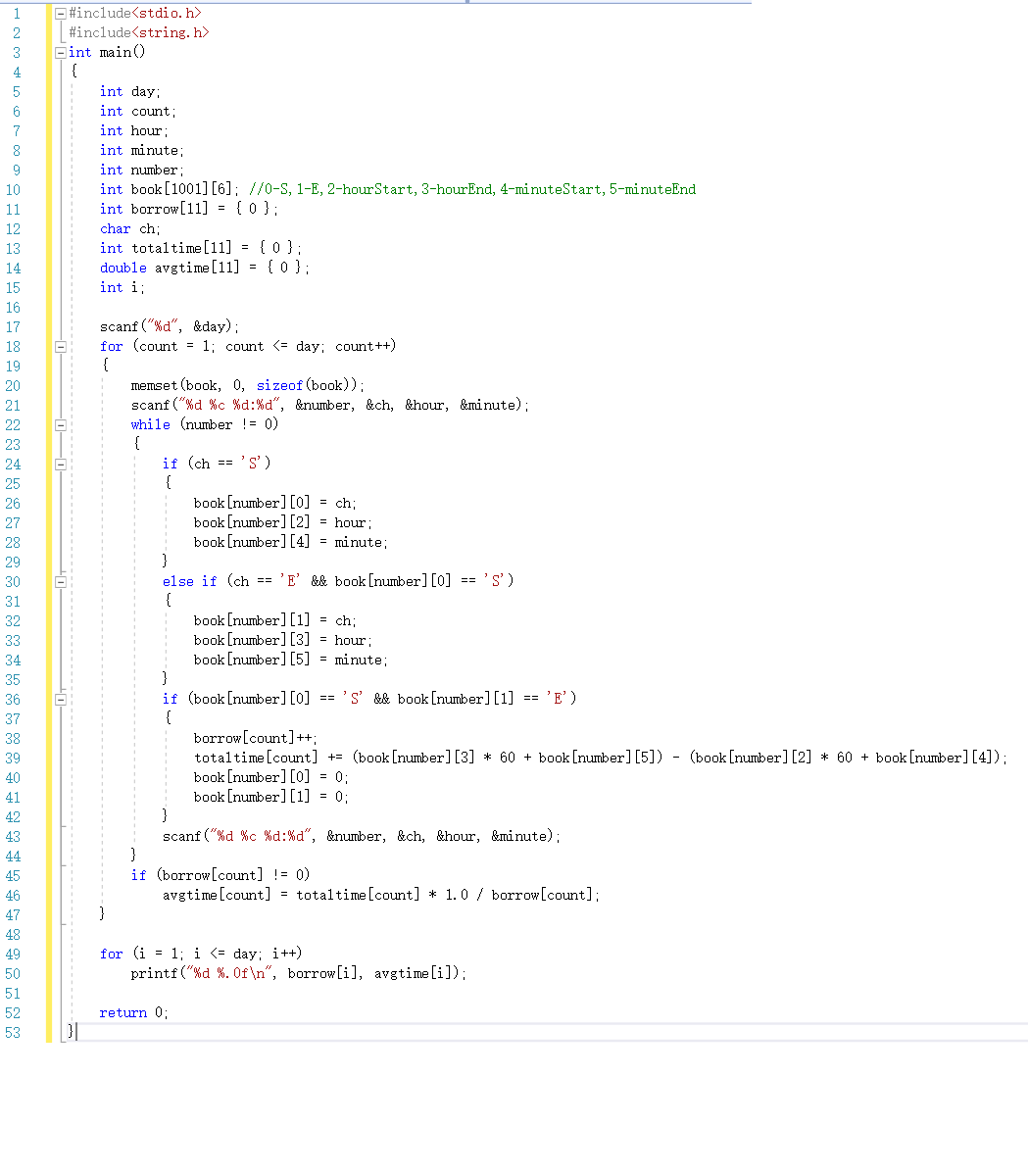
2.1.2 代码截图
2.1.3 造数据测试
| 输入数据 | 输出数据 | 备注 |
|---|---|---|
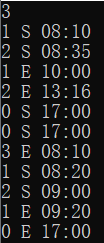 |
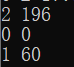 |
题目例子 |
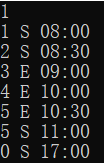 |
0 0 | 有连续S和连续E,有S和E全反 |
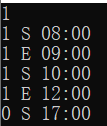 |
2 90 | 同一本书被借走多次 |
2.1.4 PTA提交列表及说明

- 第一个部分正确:连续S E和同一本书被借多次测试点未过,尝试在写入E的条件判断中加入前面要有读入过S
- 第二个部分正确:这两个测试点还是没有过,经测试后发现问题没有解决,在S E都读入计算时间后将该书号的S E都清空
- 答案正确:经过上面两次修正后成功通过
2.2 螺旋方阵
2.2.1 伪代码
定义number为要螺旋输出的数,初值为1
定于circle记录要转几圈才能输出完毕
定义数组a行长列长均为10
输入行数n
for circle=1 to (n + 1) / 2 do
for j=circle-1 to n-circle do
a[circle - 1][j] = number;
number加1
end for
for i=circle to n-circle do
a[i][n - circle] = number;
number加1
end for
for j=n-circle-1 to circle-1 do
a[n - circle][j] = number;
number加1
end for
for i=n-circle-1 to circle do
a[i][circle - 1] = number;
number加1
end for
end for
输出数组a
return 0;
2.2.2 代码截图

2.2.3 造数据测试
| 输入数据 | 输出数据 | 备注 |
|---|---|---|
| 5 | 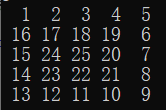 |
题目例子 |
| 1 | 1 | 最小n |
| 8 | 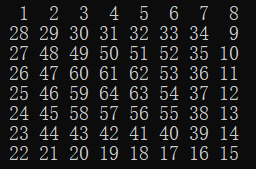 |
最大偶数n |
| 9 |  |
最大n |
2.2.4 PTA提交列表及说明

- 虽然这题提交列表是一遍过,但在2840题库中做这道题的时候做了很久,但在vs中一直有奇怪的错误,而我也不可能连测试样例都过不了就提交上PTA吧?改到正确且各种情况都测试了以后我才提交了PTA于是一遍过
- 一开始做的时候我完全没有想到利用转的圈数去做,直接右下左上的顺序一步步写循环,写的漏洞百出,只完成了最外圈往右和往下的输出,其他部分全部爆炸
- 然而我并没有死心,还是按照这个思路再次优化代码,优化到了第一圈完美输出,但第二圈开始又会将第一圈的内容覆盖掉
- 这时候我发现这个方法的问题,越到内圈越难写,变量太少,对i、j的循环的起始终止值很难控制,于是把所有代码删除,重新构思
- 又经过几次尝试后引入了变量circle,由转的圈数控制起始、终止值,思路开阔了许多,写的也很顺利,但同时也遇到了新问题,什么时候循环条件加等号,循环初值要等于多少,n、circle和i、j之间又有什么关系等等
- 写完后因为测试数据较少就将1到9都测试了一遍,很幸运偶数部分没有遇到问题,于是就提交PTA通过了
2.3 删除重复字符
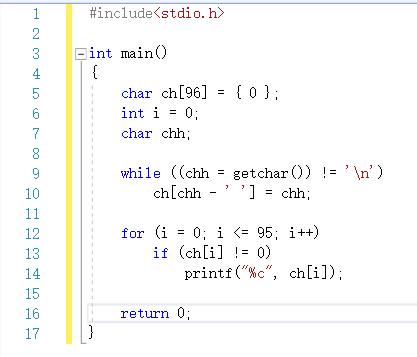
2.3.1 伪代码
定义字符型数组ch,长度为96,全部赋0
定义字符变量chh
while 读入字符chh不为回车时 do
ch[chh - ' '] = chh;
for i=0 to 95 do
if ch[i]的内容不为0 then
输出ch[i]
return 0;
2.3.2 代码截图
2.3.3 造数据测试
| 输入数据 | 输出数据 | 备注 |
|---|---|---|
| ad2f3adjfeainzzzv | 23adefijnvz | 题目例子 |
| (全部空格) | (一个空格) | 最长字符,全空格 |
| $!@REewt@@jdzoi23412 | !$1234@ERdeijotwz | |
| a | a | 最短字符串 |
2.3.4 PTA提交列表及说明

- 部分正确:一开始写的不是这个方法,用的是先读入数据再遍历删除排序的方法,但是这样写有空格的测试点又过不了,又突然灵光一现又有了新的方法
- 答案正确:因为我的代码不太一样,就说一下思路吧。
- 首先是ch的长度96,查阅课本后的ASCII码表,发现是从32到127,这样字符减去空格字符就是0~95了,而且这样读入已经是按ASCII码排好序的状态
- 然后是删除重复部分,并没有特意去写,这个字符减去32对应的下标的数组直接就赋值这个字符,再次遇到这个元素也只是再次赋值,不会有两个该元素
- 最后控制只输出不为�的数组元素就完成了题目的要求
Q3.代码阅读
-
题目说明:
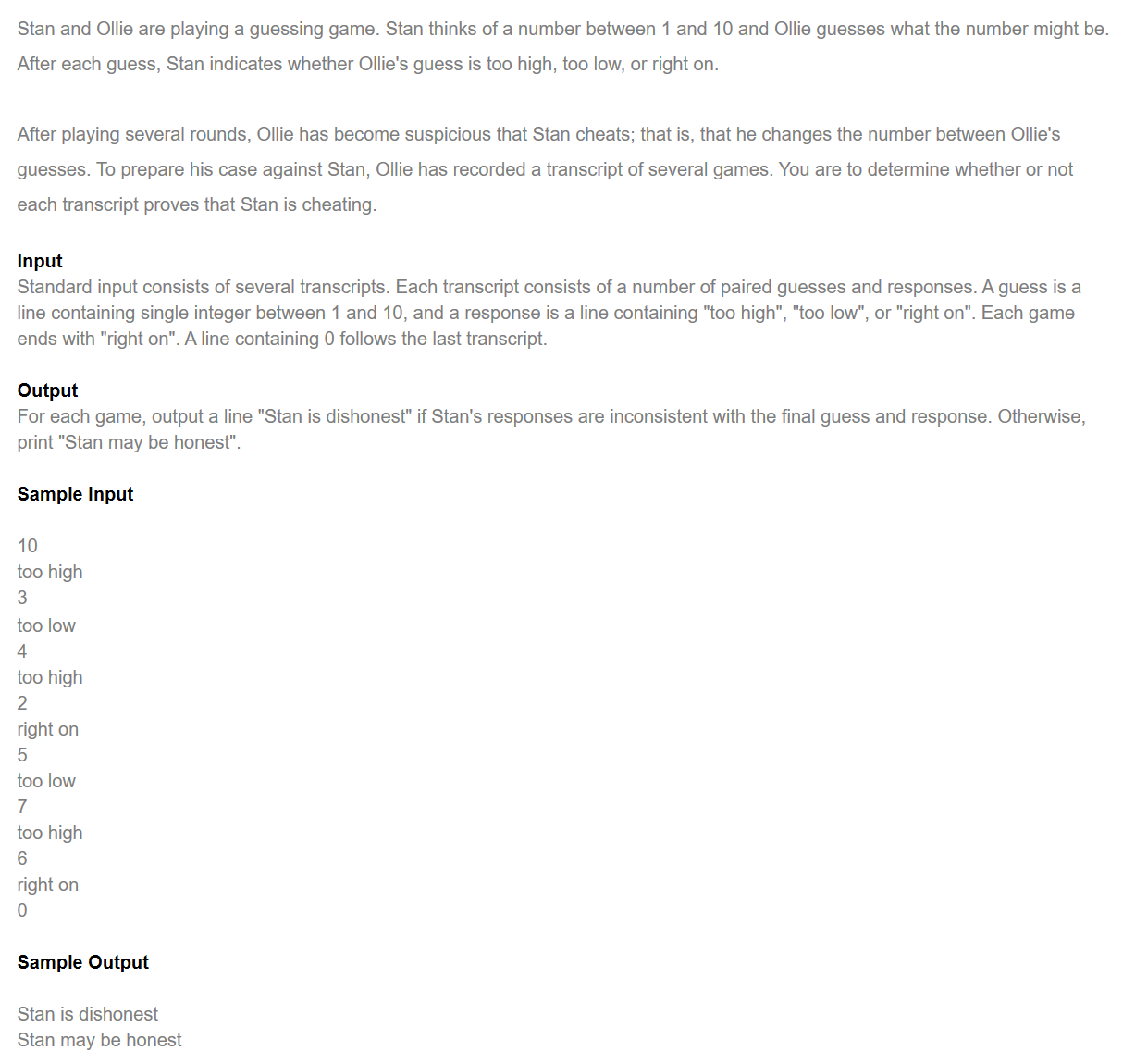
-
参考代码:
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string.h>
#include <limits.h>
using namespace std;
int main(void)
{
int n,begin = 0,end = INT_MAX;
int x;
char str[10];
while( cin >> n && n )
{
getchar();
begin = 0,end = INT_MAX;
while ( gets(str) && strcmp(str,"right on") )
{
if( strcmp(str,"too high") == 0 && n < end )
end = n;
else
if( strcmp(str,"too low") == 0 && n > begin )
begin = n;
cin >> n;
getchar();
}
if( n > begin && n < end )
printf("Stan may be honest
");
else
printf("Stan is dishonest
");
}
return 0;
}
- 代码阅读
- 这题比较简单,说一下题意,Stan和Ollie玩猜数游戏,Ollie猜一个数,Stan告诉她答案太大/太小/正确,但玩了几轮后Ollie发现不对劲,
觉得Stan肯定在耍老娘,他肯定是改过答案!我们要根据他们游戏的过程来判断Stan有没有作弊在耍Ollie - 每次输入right on就输出一次Stan是否诚实,之后输入0可以退出循环结束程序
- 虽然是C++的代码,但他似乎除了cin >> n以外也没有C++的代码了
- 代码很注意细节,每次读取完数字n后都会getchar()吸收换行符
- 外部循环条件是输入数字n,如果n不为0就进入循环;内部循环条件是输入字符串str,如果str不为right on就继续循环
- 内部循环将字符串str和too high(too low)作对比,如果输入的数字小于原来的最大数(大于原来的最小数)就更新尾部(头部)为n
- 输入right on后将最后读到的数和头部、尾部做比较,如果大于头部小于尾部,那么Stan可能是个诚实的孩子没有说谎,否则他就是不诚实的坏孩子
个人觉得这题完全可以改成用C编写,而且他引用了这么多头文件似乎也没怎么用到,还有个不知道干啥用的变量x
- 这题比较简单,说一下题意,Stan和Ollie玩猜数游戏,Ollie猜一个数,Stan告诉她答案太大/太小/正确,但玩了几轮后Ollie发现不对劲,