本篇笔记主要说一下Spark到底是个什么东西,了解一下它的基本组成部分,了解一下基本的概念,为之后的学习做铺垫。过于细节的东西并不深究。在实际的操作过程中,才能够更加深刻的理解其内涵。
1、什么是Spark?
Spark是由美国加州伯克利大学的AMP实验室开发的,一款基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。 说白了就是搞数据计算分析的框架,过于细节的东西在学习过程中再去体会,一口吃不成胖子,反而会噎死人。
2、Spark的内置模块
来看一下Spark内置哪些模块:
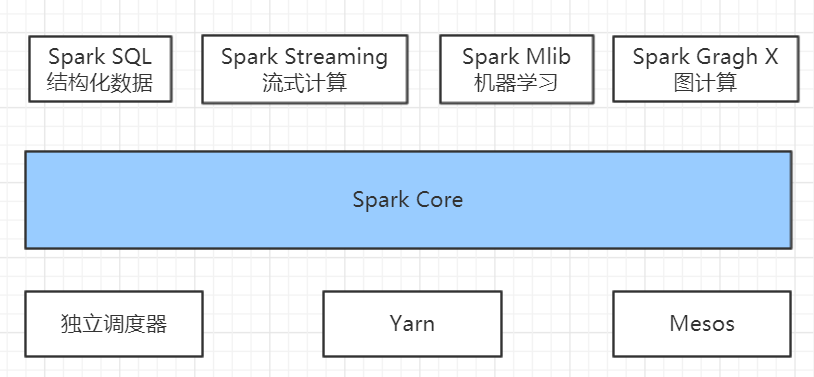
一个个来解释一下,语言过于官方,挑一些能看懂的看,其他的,用着用着就懂了:
-
Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
-
Spark SQL: Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
-
Spark Streaming: Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
-
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
-
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。 如果是Spark节点单独使用一台机器的话,那么就用它的独立调度器负责资源的调度;如果是混搭的集群,那么还是统一用Yarn比较合适,以防出现争夺资源的情况。
3、Spark的特点
Hadoop虽然已成为大数据技术的事实标准,但其本身还存在诸多缺陷,最主要的缺陷是其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。
回顾Hadoop的工作流程,可以发现Hadoop存在如下一些缺点:
- 表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程;
- 磁盘I/O开销大。MapReduce的计算是基于磁盘的,每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘中,I/O开销较大;
- 延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到I/O开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
Spark主要具有如下优点:
-
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
-
Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
-
Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop很多。Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了I/O开销。
注意咯,Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
4、Spark的重要角色
4.1 Master 和 Worker
搭建spark集群的时候我们就已经设置好了master节点和worker节点,一个集群有多个master节点和多个worker节点。
master节点常驻master守护进程,负责管理worker节点,我们从master节点提交应用。
worker节点常驻worker守护进程,与master节点通信,并且管理executor进程。
一台机器可以同时作为master和worker节点(举个例子:你有三台机器,你可以选择一台设置为master节点,然后剩下两台设为worker节点,也可以把三台都设为worker节点,这种情况下,有一个机器既是master节点又是worker节点)
1)Master
它是Spark特有资源调度系统的Leader,掌管着整个集群的资源信息,类似于Yarn中的ResourceManager,它的主要功能是:
- 监听Worker是否正常工作;
- Master对Worker、Application等的管理,具体包括接收Worker的注册,并且管理所有 的Worker;接收client提交的Application,调度等待的Application并向Worker提交。
2)Worker
它是Spark特有资源调度系统的slave,有多个。每个salve掌管着各自所在节点的资源信息,类似于Yarn框架中的NodeManager,它的主要功能是:
- 通过RegisterWorker注册到Master;
- 定时发送心跳信息给Master,告诉它 “我还活着”;
- 根据Master发送的Application配置进程环境,并启动ExcutorBackend(这是一个执行Task的临时进程)
4.2 Driver 和 Executor
上面所说的master和worker,不论有没有任务要被执行,这两个角色始终都是存在的,下边要说的driver和executor跟它俩不一样了。没必要一直起着,它们是伴随着提交的任务来的。当我们写好代码,打成jar包,提交到集群上运行,才会出现这两个东西。
1)Driver(驱动器)
Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果驱动器程序终止,那么Spark应用也就结束了。相当于ApplicationMaster,当前任务的老大。它主要负责:
-
把用户程序转为作业(JOB)
-
跟踪Executor的运行状况
-
为执行器节点调度任务
-
UI展示应用运行状况
2)Executor(执行器)
Spark Executor是一个工作节点,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责:
-
负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器进程;
-
通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。这个先暂时不看,后边学习了再说。
总结:Master和Worker是Spark的守护进程,也就是说Spark正常运行所必须的进程。Driver和Executor是临时程序,当有具体任务提交到Spark集群的时候才会开启的程序。
参考资料:
[1] 李海波. 大数据技术之Spark