今天想停止spark集群,发现执行stop-all.sh的时候spark的相关进程都无法停止。提示:
no org.apache.spark.deploy.master.Master to stop
no org.apache.spark.deploy.worker.Worker to stop
上网查了一些资料,再翻看了一下stop-all.sh,stop-master.sh,stop-slaves.sh,spark-daemon.sh,spark-daemons.sh等脚本,发现很有可能是由于$SPARK_PID_DIR的一个环境变量导致。
我搭建的是Hadoop2.6.0+Spark1.1.0+Yarn的集群。Spark、Hadoop和Yarn的停止,都是通过一些xxx.pid文件来操作的。以spark的stop-master为例,其中停止语句如下:

再查看spark-daemon.sh中的操作:
$SPARK_PID_DIR中存放的pid文件中,就是要停止进程的pid。其中$SPARK_PID_DIR默认是在系统的/tmp目录:
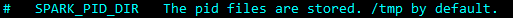
系统每隔一段时间就会清除/tmp目录下的内容。到/tmp下查看一下,果然没有相关进程的pid文件了。这才导致了stop-all.sh无法停止集群。
担心使用kill强制停止spark相关进程会破坏集群,因此考虑回复/tmp下的pid文件,再使用stop-all.sh来停止集群。
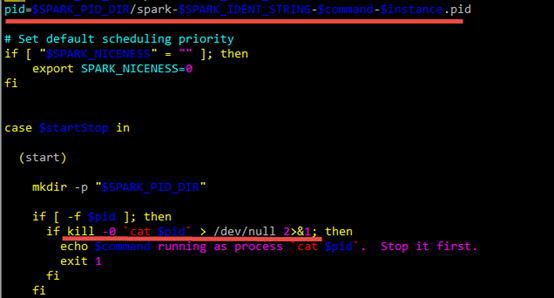
分析spark-daemon.sh脚本,看到pid文件命名规则如下:
pid=$SPARK_PID_DIR/spark-$SPARK_IDENT_STRING-$command-$instance.pid
其中
$SPARK_PID_DIR是/tmp
$SPARK_IDENT_STRING是登录用户$USER,我的集群中用户名是cdahdp
$command是调用spark-daemon.sh时的参数,有两个:
org.apache.spark.deploy.master.Master
org.apache.spark.deploy.worker.Worker
$instance也是调用spark-daemon.sh时的参数,我的集群中是1
因此pid文件名如下:
/tmp/spark-cdahdp-org.apache.spark.deploy.master.Master-1.pid
/tmp/spark-cdahdp-org.apache.spark.deploy.worker.Worker-1.pid
通过jps查看相关进程的pid:
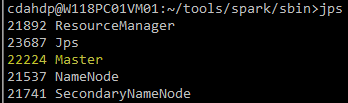
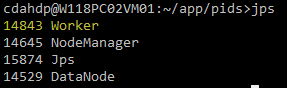
将pid保存到对应的pid文件即可。
之后调用spark的stop-all.sh,即可正常停止spark集群。
停止hadoop和yarn集群时,调用stop-all.sh,也会出现这个现象。其中NameNode,SecondaryNameNode,DataNode,NodeManager,ResourceManager等就是hadoop和yarn的相关进程,stop时由于找不到pid导致无法停止。分析方法同spark,对应pid文件名不同而已。
Hadoop的pid命名规则:
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pid
pid文件名:
/tmp/hadoop-cdahdp-namenode.pid
/tmp/hadoop-cdahdp-secondarynamenode.pid
/tmp/hadoop-cdahdp-datanode.pid
Yarn的pid命名规则:
pid=$YARN_PID_DIR/yarn-$YANR_IDENT_STRING-$command.pid
pid文件名:
/tmp/yarn-cdahdp-resourcemanager.pid
/tmp/yarn-cdahdp-nodemanager.pid
恢复这些pid文件即可使用stop-all.sh停止hadoop和yarn进程。

要根治这个问题,只需要在集群所有节点都设置$SPARK_PID_DIR, $HADOOP_PID_DIR和$YARN_PID_DIR即可。
修改hadoop-env.sh,增加:
export HADOOP_PID_DIR=/home/ap/cdahdp/app/pids
修改yarn-env.sh,增加:
export YARN_PID_DIR=/home/ap/cdahdp/app/pids
修改spark-env.sh,增加:
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
启动集群以后,查看/home/ap/cdahdp/app/pids目录,如下:
