Lab 1链接:https://pdos.csail.mit.edu/6.824/labs/lab-1.html
Part I: Map/Reduce input and output
Part I需要补充两个关键功能:为map函数分解输出的功能和为reduce函数收集输入的功能,这两个功能对应的函数分别在common_map.go的doMap()函数和common_reduce.go的doRedce()函数。
本人首先梳理程序运行流程,其次补充代码,最后测试结果。
程序运行流程简述如下:
- Sequential首先获取Master对象的指针,然后利用函数闭包运行Master.run()。
- Master.run()会依次运行mapPhase和reducePhase。
- 在mapPhase中,doMap会依次处理每一个输入文件;在reducePhase中,doReduce会依次处理nReduce(论文中为R)个区域。
为实现doMap函数,需要实现以下功能:
- 读取inFile。
- 通过mapF函数,将inFile转换成key/value的切片形式。
- 将上一步得到的结果切割为nReduce个切片,并使用hash函数将结果分配到对应的切片中。
- 将上一步得到的结果转换为Json格式,并存储于文件中。
1 func doMap( 2 jobName string, // the name of the MapReduce job 3 mapTask int, // which map task this is 4 inFile string, 5 nReduce int, // the number of reduce task that will be run ("R" in the paper) 6 mapF func(filename string, contents string) []KeyValue, 7 ) { 8 // Your code here (Part I). 9 // read file 10 data, err := ioutil.ReadFile(inFile) 11 if err != nil{ 12 log.Fatal("common_map.doMap: fail to read the file. The error is ", err) 13 } 14 15 // transfer file 16 slice := mapF(inFile, string(data)) 17 18 // initialize reduceKv 19 var reduceKv [][]KeyValue 20 for i := 0; i < nReduce; i++{ 21 temp := make([]KeyValue, 0) 22 reduceKv = append(reduceKv, temp) 23 } 24 25 // get reduceKv 26 for _, s := range slice{ 27 index := ihash(s.Key) % nReduce 28 reduceKv[index] = append(reduceKv[index], s) 29 } 30 31 // get intermediate files 32 for i:= 0; i < nReduce; i++{ 33 file, err := os.Create(reduceName(jobName, mapTask, i)) 34 if err != nil{ 35 log.Fatal("common_map.doMap: fail to create the file. The error is ", err) 36 } 37 enc := json.NewEncoder(file) 38 for _, kv := range(reduceKv[i]){ 39 err := enc.Encode(&kv) 40 if err != nil{ 41 log.Fatal("common_map.doMap: fail to encode. The error is ", err) 42 } 43 } 44 file.Close() 45 } 46 }
为实现doReduce函数,需要实现如下功能:
- 读取文件中存储的key/value对,并对其进行排序。
- 将key值相同的value发送至用户定义的reduceF()中,reduceF()会返回一个新的value值。
- 将新的key/value对写入文件。
1 func doReduce( 2 jobName string, // the name of the whole MapReduce job 3 reduceTask int, // which reduce task this is 4 outFile string, // write the output here 5 nMap int, // the number of map tasks that were run ("M" in the paper) 6 reduceF func(key string, values []string) string, 7 ) { 8 // Your code here (Part I). 9 10 // get and decode file 11 var slices []KeyValue 12 for i := 0; i < nMap; i++{ 13 fileName := reduceName(jobName, i, reduceTask) 14 file, err := os.Open(fileName) 15 if err != nil{ 16 log.Fatal("common_reduce.doReduce: fail to open the file. The error is ", err) 17 } 18 dec := json.NewDecoder(file) 19 var kv KeyValue 20 for{ 21 err := dec.Decode(&kv) 22 if err != nil{ 23 break 24 } 25 slices = append(slices, kv) 26 } 27 file.Close() 28 } 29 30 sort.Sort(ByKey(slices)) 31 32 //return the reduced value for the key 33 var reducedValue []string 34 var outputValue []KeyValue 35 preKey := slices[0].Key 36 for i, kv := range slices{ 37 if kv.Key != preKey{ 38 outputValue = append(outputValue, KeyValue{preKey, reduceF(preKey, reducedValue)}) 39 reducedValue = make([]string,0) 40 } 41 reducedValue = append(reducedValue, kv.Value) 42 preKey = kv.Key 43 44 if i == (len(slices) - 1){ 45 outputValue = append(outputValue, KeyValue{preKey, reduceF(preKey, reducedValue)}) 46 } 47 } 48 49 //write and encode file 50 file, err := os.Create(outFile) 51 if err != nil{ 52 log.Fatal("common_reduce.doReduce: fail to create the file. The error is ", err) 53 } 54 defer file.Close() 55 56 enc := json.NewEncoder(file) 57 for _, kv := range outputValue{ 58 err := enc.Encode(&kv) 59 if err != nil{ 60 log.Fatal("common_reduce.doReduce: fail to encode. The error is ", err) 61 } 62 } 63 }
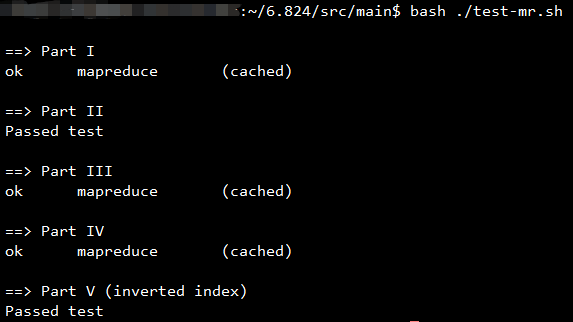
实验结果如下图所示:

Part II: Single-worker word count
Part II需要统计文档中每个单词出现的数目,需要实现的函数为wc.go中的mapF()和reduceF()函数。
mapF()函数需要将文件拆分为单词,并返回mapreduce.KeyValue的形式。reduceF()函数需要统计每一个Key对应的Value出现的数目,并以string的形式返回。
1 func mapF(filename string, contents string) []mapreduce.KeyValue { 2 // Your code here (Part II). 3 f := func(c rune) bool{ 4 return !unicode.IsLetter(c) 5 } 6 7 words := strings.FieldsFunc(contents, f) 8 var result []mapreduce.KeyValue 9 for _, word := range words{ 10 result = append(result, mapreduce.KeyValue{word,"1"}) 11 } 12 return result 13 } 14 15 func reduceF(key string, values []string) string { 16 // Your code here (Part II). 17 sum := 0 18 for _, value := range values{ 19 i, err := strconv.Atoi(value) 20 if err != nil{ 21 log.Fatal("wc.reduceF: fail to convert. The error is ", err) 22 } 23 sum += i 24 } 25 return strconv.Itoa(sum) 26 }
实验结果如下图所示:

Part III: Distributing MapReduce tasks&&Part IV: Handling worker failures
Part III和Part IV需要将顺序执行的MapReduce框架并行化并处理worker异常。
本人分别介绍worker和master的执行流程。
worker:RunWorker()首先被调用,该函数创建新Worker并通过call()函数向Master.Register()发送RPC。
master:
- 在master.go的Distributed()函数中,master通过startRPCServer()启动RPC服务器,然后利用函数闭包运行run()函数。
- 在run()函数中,master会依次运行schedule(mapPhase)和schedule(reducePhase)。
- 在schedule(phase)函数中,master会开启新协程运行forwardRegistrations()函数,然后运行Part III和Part IV需要实现的schedule.go中的schedule()函数。
- 在介绍worker的执行流程时,本人提到worker会向Master.Register()发送RPC。在Register()函数中,master会将新的worker添加至mr.workers中并告知forwardRegistrations()出现了新的worker。
- 在forwardRegistrations()函数中,master通过mr.workers的数目判断是否有新的worker。若有新的worker,master通过channel通知schedule.go的schedule()函数。
- 在schedule()函数中,master负责为worker分配task。
为实现master对worker的调度,需要在schedule()函数中实现如下功能。
- 通过sync.WaitGroup判断全部任务是否完成。
- 通过registerChan判断是否有新的worker。若有,开启新协程为此worker分配任务。
- 通过带有缓冲的channel输入任务序号,从channel中取出任务序号并分配给worker。若worker异常,则重新输入任务序号。
- 通过call()函数向worker发送RPC。
1 func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { 2 var ntasks int 3 var n_other int // number of inputs (for reduce) or outputs (for map) 4 switch phase { 5 case mapPhase: 6 ntasks = len(mapFiles) 7 n_other = nReduce 8 case reducePhase: 9 ntasks = nReduce 10 n_other = len(mapFiles) 11 } 12 13 fmt.Printf("Schedule: %v %v tasks (%d I/Os) ", ntasks, phase, n_other) 14 15 // All ntasks tasks have to be scheduled on workers. Once all tasks 16 // have completed successfully, schedule() should return. 17 // 18 // Your code here (Part III, Part IV). 19 // 20 var wg sync.WaitGroup 21 wg.Add(ntasks) 22 23 taskChan := make(chan int, ntasks) 24 for i := 0; i < ntasks; i++{ 25 taskChan <- i 26 } 27 28 go func(){ 29 for{ 30 ch := <- registerChan 31 go func(address string){ 32 for{ 33 index := <- taskChan 34 result := call(address, "Worker.DoTask", &DoTaskArgs{jobName, mapFiles[index], phase, index, n_other},new(struct{})) 35 if result{ 36 wg.Done() 37 fmt.Printf("Task %v has done ", index) 38 }else{ 39 taskChan <- index 40 } 41 } 42 }(ch) 43 } 44 }() 45 wg.Wait() 46 fmt.Printf("Schedule: %v done ", phase) 47 }
Part V: Inverted index generation (optional, does not count in grade)
Part V需要实现倒排索引,需要补充的函数为ii.go中的mapF()和reduceF()函数。
mapF()函数需要对输入文件中的单词进行分割,返回以单词为Key,以文件题目为Value的切片。
reduceF()函数需要对相同Key对应的全部Value去重并排序,统计Value的个数。
1 func mapF(document string, value string) (res []mapreduce.KeyValue) { 2 // Your code here (Part V). 3 f := func(c rune) bool{ 4 return !unicode.IsLetter(c) 5 } 6 words := strings.FieldsFunc(value, f) 7 var result []mapreduce.KeyValue 8 for _, word := range words{ 9 result = append(result, mapreduce.KeyValue{word, document}) 10 } 11 return result 12 } 13 14 func reduceF(key string, values []string) string { 15 // Your code here (Part V). 16 fileName := make(map[string]bool) 17 18 for _, value := range values{ 19 fileName[value] = true 20 } 21 22 num := 0 23 var documents []string 24 for key := range fileName{ 25 num += 1 26 documents = append(documents, key) 27 } 28 sort.Strings(documents) 29 30 var result string 31 for i, file := range documents{ 32 if i >= 1{ 33 result += "," 34 } 35 result += file 36 } 37 return strconv.Itoa(num) + " " + result 38 }
实验结果如下图所示:
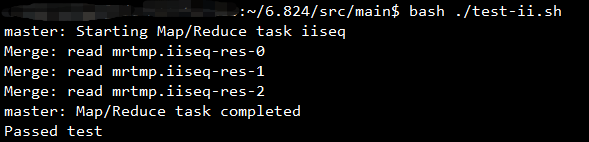
Running all tests