JMeter自身带有Master-Slave压测框架,对于并发量不是很高的压力情况下(比如tps低于5000),该方案是可行的,并且使用起来非常方便,只要在配置文件或者命令行工具的参数做一些补充,即可以实现分布式压测,具体请参见JMeter官网操作步骤或者UncleYong的文章
但JMeter的Master-Slave有诸多的缺陷:
1.Master机器的瓶颈,JMeter通过RMI的方式来实现Master-Slave的通信,所有的信息最终都会汇总到主机上,一旦slave机器数量增多,并且slave上的并发数上去,Master的压力就会很大
2.无法模拟不同区域内的压测,这个在如今的互联网下的压测有非常大的缺陷,现在日活高的App,基本都是跨地区跨机房部署,所以用户终端到机房这段链路也很重要,但现在的JMeter框架分布式框架实现不了这样的压测
3.带宽的问题,由于我们是局域网环境,往往出口就是一个,这种情况下tps很高并且输入输出不小的情况下,出口的带宽也可能会成为比较大的瓶颈
4.JMeter官方推荐使用非GUI的方式来实现压测,但这样就看不到被压测对象状态,有可能系统以及压垮了还在继续压,没法做到实时监控
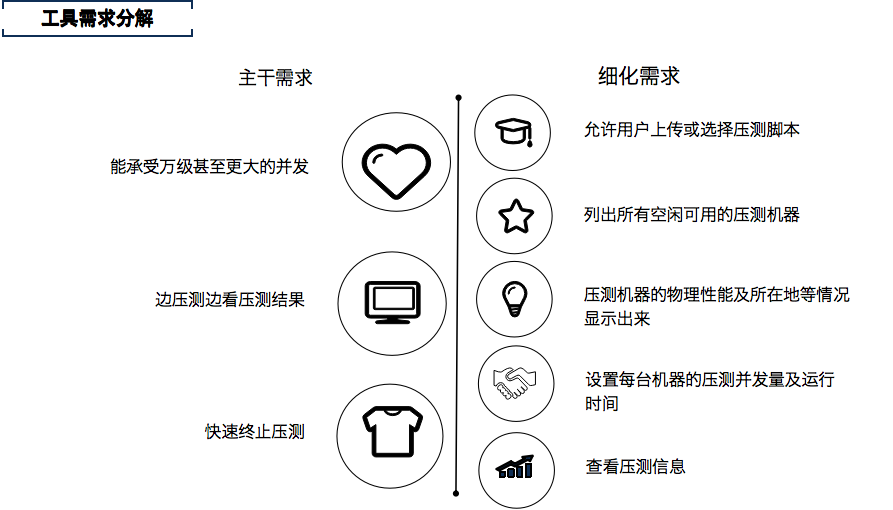
所以基于这些问题,我们希望能够实现真正意义上分布式压测工具或者平台,具备的主要功能要求如下:
1.真正的基于互联网的分布式压测,满足市面上绝大部分App的压测要求(日活大几百万)
2.可以实时监控,查询压测状态(压测数据包括tps,error%,响应时间,以及压测机本身)
3.可以快速终止压测,通过#2,一旦发现压测异常如压测达到阈值,那么就可以手动(一键式)或者自动终止压测,避免压垮压测对象
另外还有一些细化的需求,所以整体需求功能如下
技术突破:
JMeter从3.2版本起,新增了InfluxDB的监听器,该监听器支持使用InfluxDB HTTP API并通过异步HTTP调用将度量标准直接推送到数据库,而无需任何额外的数据库配置,再通过influxDB和Grafana的集成,就能实时监控压测状态,核心模块调用逻辑如下

基于上面核心模块,再来实现整个业务平台,这里有两种实现方式,一个是通过Jenkins pipeline来实现压测任务调度及执行,还有一个是通过自建平台(如spring boot框架)来实现。
基于Jenkins pipeline来实现分布式压测如下:
通过pipeline上的Groovy脚本来撰写脚本并且集成类似于ftp plugin,jemeter plugin等插件来串联压测脚本的上传(目标压测机),执行,生成报告等,并通过在JMeter脚本中集成InfluxDB,influxDB集成Grafana,实现实时监控压测状态,并且一旦压测异常,也可以通过pipeline脚本来实现一键式终止压测。这种方式实现起来比较方便,能达到压测效果。但对于功能的扩展,以及压测平台包括插件出bug后的定位等等都不太理想。毕竟脚本语言的组织以及工具的支持不像Java或者Python等有那么多的框架/工具可以支持,需要写很多功能,并且一旦功能多起来,结构就会显得异常臃肿,所以我这边抛弃了这种实现方式,但注意,这种方式是可以实现分布式压测的,并且也能比较快速的能够把分布式压测搭建起来。
基于Spring boot框架来实现压测平台的整合,这种方式是是比较值得推荐的,整体实现方式难度适中,且功能容易扩展。这里我重点说一下我的实现方式
整体框架如下:
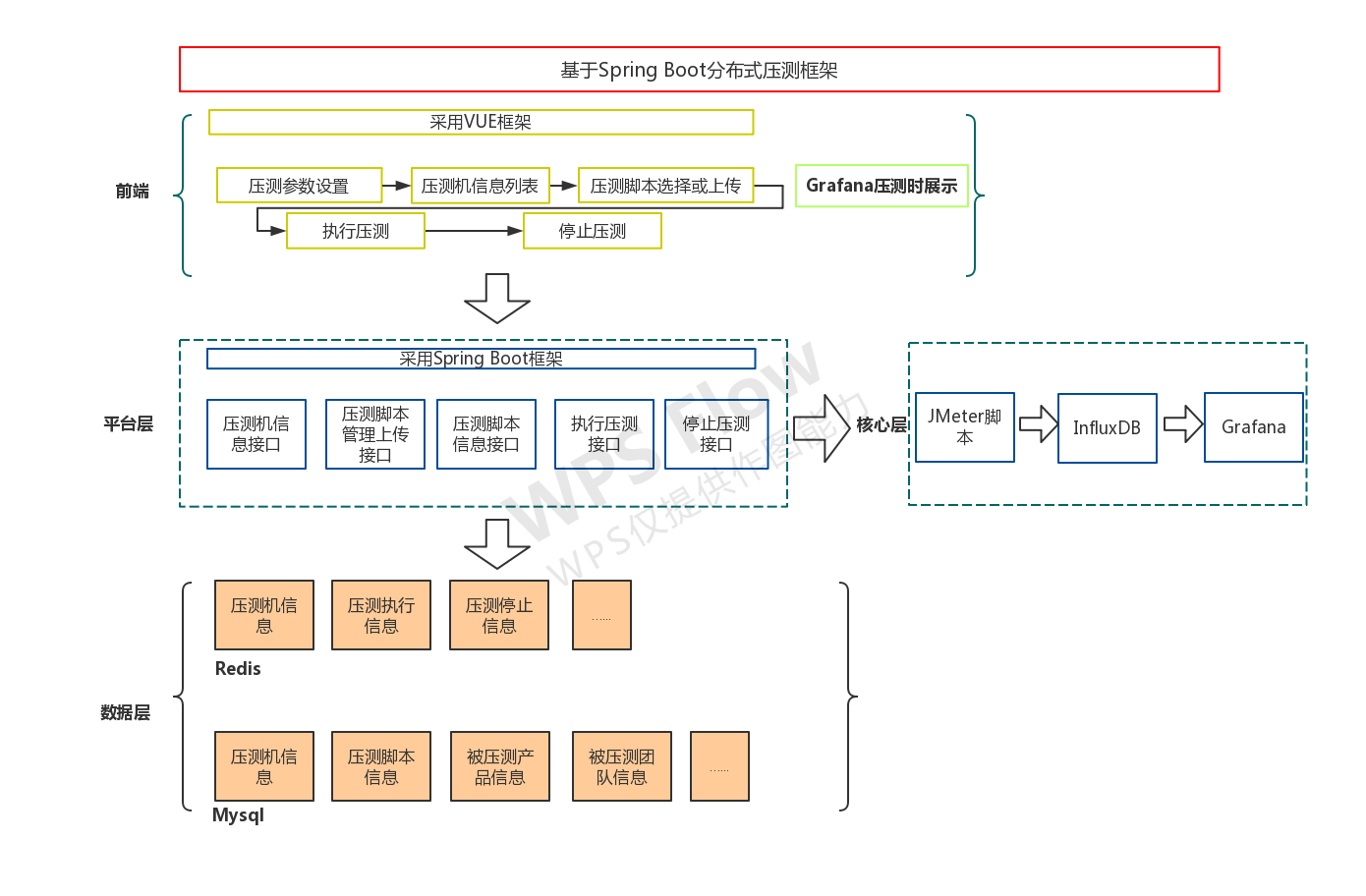
整体思路就是:
1. 安装配置好influxDB,并创建相关等数据库,可以参考uncleyong的文章
2. 安装配置好Grafana,并下载JMeter 模板,我比较喜欢这个:https://grafana.com/grafana/dashboards/5496,但上面有不少模板可以选择,可以使用jmeter去search
3. 在JMeter脚本中打通InfluxDB,通过添加InfluxDB等监听器来实现脚本
4. 通过Spring Boot来串联整个压测平台,把压测机信息、压测脚本管理、压测执行、压测终止等接口暴露给前端
5. 通过Redis来缓存热点数据,比如压测机信息,还有压测执行结果等,mysql来做整体数据等存储
6. Spring Boot和压测机之间等打通,推荐使用JSch - Java Secure Channel来实现
7. 分布式执行中会涉及到异步和同步等问题,比如分配到10台机器去执行,这个需要异步下达指令,但需要等所有机器执行完后才汇总压测结果,可以通过@Async + CountDownLatch来实现