上一篇文章介绍了决策树的剪枝概念和意义以及几种常见的剪枝策略。由于剪枝策略或方法可以非常多,而且每一种在不同的应用场景下各有优劣,没有绝对的好。本篇文章继续讨论决策树的剪枝。
现在我们已经知道剪枝需要一个判断依据来决定对当前节点是否需要剪枝,可以定义一个损失函数(loss function)或者代价函数(cost function)来实现。假设树T的叶节点个数为|T|,t是某一叶节点,该节点覆盖Nt个样本,其中分类为k的样本点Ntk个,Ht(T)为叶节点t上的经验熵,这里不妨再啰嗦几句,根据前面有关决策树生成的介绍可知,信息熵是表征系统的混乱程度,熵越大越混乱,也就是越难判断样本分类。定义损失函数为,
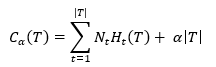 (1)
(1)
其中经验熵为,
 (2)
(2)
如果Ntk为0,则跳过这个分类。
将(1)中右端第一部分记为,
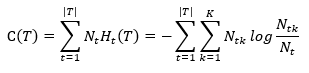
则(1)变成
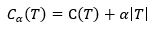 (3)
(3)
(3)式中,C(T)表示模型对训练数据的预测误差,即,误差使用混乱程度来表征,|T|表示模型复杂度,上一篇文章中讲到降低树的复杂度也是剪枝的原因,参数α 为控制因子,α 较小时,可以允许一定程度复杂的树,α 较大时,促使选择简单的树,否则损失函数会很大,α=1时,第二项就是模型的复杂度——叶节点个数。
可以看出,为了降低损失函数,要求我们尽量降低模型的复杂度和系统的信息熵。前面讲决策树生成的时候,考虑了信息增益(比)来对训练数据进行拟合,这里损失函数考虑了减小模型复杂度,决策树生成学习局部的模型,决策树剪枝学习整体的模型。
算法描述
输入:决策树T,参数α
输出:剪枝后的树Tα
步骤:
- 计算每个叶节点的经验熵
- 递归地从叶节点向上回溯,自下而上,对非叶节点而言,剪枝前后,整棵树的损失函数分别为Cα和Cα',如果 Cα' < Cα ,则进行剪枝,此非叶节点覆盖的样本中分类最多的那个分类作为剪枝后新的叶节点的分类。
- (取其他叶节点)继续执行步骤 2, 直到不能继续为止,得到损失函数最小的树Tα
ref
统计学习方法,李航
代码片段如下:
为了剪枝判断方便些,在节点类里面增加了几个辅助字段
public class Node { /// <summary> /// 节点唯一id /// </summary> public int id; /// <summary> /// 用于划分的属性名,叶节点为null /// </summary> public string Attr { get; set; } /// <summary> /// 节点分类,只有叶节点有分类值,内部节点为null /// </summary> public string Class { get; set; } /// <summary> /// 根据属性的取值划分子空间,叶节点为null /// key为属性值,value为对应的子树的根结点,表示子空间 /// </summary> public Dictionary<string, Node> Children { get; set; } /// <summary> /// 父节点,根节点的父节点为null /// </summary> public Node parent { get; set; } /// <summary> /// 对应父节点中Children的key值,父节点的划分属性对应的值 /// </summary> public string attrVal; /// <summary> /// 深度,根节点深度为0 /// </summary> public int deep; /// <summary> /// 每个分类的样本数量 /// </summary> public double[] classCount; /// <summary> /// 节点覆盖的总样本数 = classCount.Sum() /// </summary> public double count; }
决策树也增加了几个字段
public class DTree { /// <summary> /// 所有的分类值 /// </summary> private string[] _classes; private int _maxDeep; /// <summary> /// 最大深度,根节点深度为0 /// </summary> public int MaxDeep { get { return _maxDeep; } } ... // 其他字段和成员方法 }
决策树的构造就不给出来了,主要是生成时注意节点对象所覆盖的样本点数量,样本各分类数量,以及节点id等。
然后决策树中剪枝的方法如下
public class DTree {
... // 其他字段和成员函数 /// <summary> /// 剪枝 /// </summary> public void Prune() { var tuple = GetPrecNodes(_maxDeep); var leaves = GetInitLeaves(); var deep = _maxDeep; // 递归深度 var unPrunedCount = 0; // 某轮未被剪枝的数量 while(deep > 0) { var nodes = GetPrecNodes(deep); foreach (var node in nodes) { // 考察内部节点 if (node.Children != null && node.Children.Count > 0) { // 判断是否需要剪枝 var preLoss = GetLoss(leaves); var fakeLeaves = GetPrunedLeaves(leaves, node); var postLoss = GetLoss(fakeLeaves); if (postLoss < preLoss) { // 需要剪枝,则进行剪枝 node.parent.Children[node.attrVal] = fakeLeaves[fakeLeaves.Count - 1]; leaves = fakeLeaves; // 更新叶节点 } else { unPrunedCount++; } } } if(deep == _maxDeep) // 当前深度与最大深度保持同步,则需要检查是否需要修改最大深度 { if(unPrunedCount == 0) // 本轮被考察节点全部被剪枝,则修改最大深度 { _maxDeep--; } } deep--; } } /// <summary> /// 获取剪枝后的叶节点列表 /// </summary> /// <param name="leaves">剪枝前叶节点列表</param> /// <param name="node">被剪枝的节点</param> /// <returns></returns> private List<Node> GetPrunedLeaves(List<Node> leaves, Node node) { var dict = node.Children.ToDictionary(c => c.Value.id, c => c.Value); var list = leaves.Where(l => !dict.ContainsKey(l.id)).ToList(); // 添加剪枝后的新叶节点 var leaf = new Node() { id = node.id }; leaf.parent = node.parent; leaf.deep = node.deep; leaf.Attr = node.Attr; leaf.count = node.count; leaf.classCount = node.classCount; int maxIdx = 0; double maxCount = node.classCount[0]; for(int i = 0; i < node.classCount.Length; i++) { if(maxCount < node.classCount[i]) { maxIdx = i; maxCount = node.classCount[i]; } } leaf.Class = _classes[maxIdx]; list.Add(leaf); return list; } /// <summary> /// 获取损失函数 /// </summary> /// <param name="leaves"></param> /// <returns></returns> private double GetLoss(List<Node> leaves, double alpha = 1) { double sum = 0; foreach(var leaf in leaves) { double entropy = 0; foreach(var c in leaf.classCount) { entropy -= c / leaf.count * Math.Log(c / leaf.count, 2); } sum += entropy * leaf.count; } return sum + leaves.Count * alpha; } /// <summary> /// 获取指定深度的前驱节点列表,即,节点深度为指定深度减1的节点列表 /// </summary> /// <returns></returns> private List<Node> GetPrecNodes(int deep) { var list = new List<Node>(); // 结果列表 // var dest = deep - 1; // bfs 遍历即可 var queue = new Queue<Node>(); queue.Enqueue(_root); while(queue.Count > 0) { var node = queue.Dequeue(); if (node.deep == dest) list.Add(node); else if(node.deep < dest) { if (node.Children != null) { foreach (var n in node.Children) { queue.Enqueue(n.Value); } } } //if (node.Children == null || node.Children.Count == 0) // leaves.Add(node); } return list; } /// <summary> /// 获取初始的叶节点列表 /// </summary> /// <returns></returns> private List<Node> GetInitLeaves() { // bfs 遍历即可 var queue = new Queue<Node>(); queue.Enqueue(_root); var leaves = new List<Node>(); while (queue.Count > 0) { var node = queue.Dequeue(); if (node.Children == null || node.Children.Count == 0) leaves.Add(node); } return leaves; } }
(代码仅帮助理解剪枝策略,不保证能正确运行)