以前比较两个List数据,筛选出所需要的数据时候,一直套两层for循环来执行。用到去重(Distinct)的时候,这两个需求其实都是一样的,都是需要比较两个集合,查看了下它的源码,里面确实有值得借鉴的地方。
先附上源码一直我调试的代码,大部分地方加上了注释
1 class Program 2 { 3 static void Main(string[] args) 4 { 5 //初始化集合 6 List<Point> points = new List<Point>() 7 { 8 new Point() {X=1,Y=2}, 9 new Point() {X=7,Y=2}, 10 new Point() {X=2,Y=2}, 11 new Point() {X=2,Y=3}, 12 new Point() {X=3,Y=2}, 13 new Point() {X=4,Y=2}, 14 new Point() {X=5,Y=2}, 15 new Point() {X=6,Y=3}, 16 new Point() {X=2,Y=3} 17 }; 18 var distinctPoints = DistinctIterator(points, new PointCompare()).ToList(); 19 Console.Read(); 20 } 21 22 //调用Distinct 方法 内部调的这个方法 抽取出来了 23 static IEnumerable<TSource> DistinctIterator<TSource>(IEnumerable<TSource> source, IEqualityComparer<TSource> comparer) 24 { 25 Set<TSource> set = new Set<TSource>(comparer); 26 foreach (TSource element in source) 27 if (set.Add(element)) 28 //若返回true则添加到集合中 29 yield return element; 30 } 31 } 32 33 struct Point 34 { 35 public int X { get; set; } 36 37 public int Y { get; set; } 38 } 39 40 class PointCompare : IEqualityComparer<Point> 41 { 42 43 44 public bool Equals(Point x, Point y) 45 { 46 return x.X == y.X && x.Y == y.Y; 47 //return false; 48 } 49 50 public int GetHashCode(Point obj) 51 { 52 // return 1; 53 return obj.X.GetHashCode() ^ obj.Y.GetHashCode(); 54 } 55 } 56 57 internal class Set<TElement> 58 { 59 int[] buckets; 60 Slot[] slots; 61 int count; 62 int freeList; 63 IEqualityComparer<TElement> comparer; 64 65 public Set() : this(null) { } 66 67 //初始化 68 public Set(IEqualityComparer<TElement> comparer) 69 { 70 //若comparer为null则string、int...基元类型 71 if (comparer == null) comparer = EqualityComparer<TElement>.Default; 72 this.comparer = comparer; 73 //大小为7 74 buckets = new int[7]; 75 //大小为7 76 slots = new Slot[7]; 77 freeList = -1; 78 } 79 80 // If value is not in set, add it and return true; otherwise return false 81 public bool Add(TElement value) 82 { 83 //若Find返回true则代表已重复,则不会添加到集合中 84 return !Find(value, true); 85 } 86 87 // Check whether value is in set 88 //没用到 89 public bool Contains(TElement value) 90 { 91 return Find(value, false); 92 } 93 94 // If value is in set, remove it and return true; otherwise return false 95 //没用到 96 public bool Remove(TElement value) 97 { 98 int hashCode = InternalGetHashCode(value); 99 int bucket = hashCode % buckets.Length; 100 int last = -1; 101 for (int i = buckets[bucket] - 1; i >= 0; last = i, i = slots[i].next) 102 { 103 if (slots[i].hashCode == hashCode && comparer.Equals(slots[i].value, value)) 104 { 105 if (last < 0) 106 { 107 buckets[bucket] = slots[i].next + 1; 108 } 109 else 110 { 111 slots[last].next = slots[i].next; 112 } 113 slots[i].hashCode = -1; 114 slots[i].value = default(TElement); 115 slots[i].next = freeList; 116 freeList = i; 117 return true; 118 } 119 } 120 return false; 121 } 122 123 bool Find(TElement value, bool add) 124 { 125 //调用comparer的GetHashCode 126 int hashCode = InternalGetHashCode(value); 127 //根据hash值取余运算 查找相同结果的数据 比较hash值以及调用IEqualityComparer.Equals方法,若相同 则代表存在相同数据 128 for (int i = buckets[hashCode % buckets.Length] - 1; i >= 0; i = slots[i].next) 129 { 130 if (slots[i].hashCode == hashCode && comparer.Equals(slots[i].value, value)) return true; 131 } 132 if (add) 133 { 134 int index; 135 //没用到。。。 136 if (freeList >= 0) 137 { 138 index = freeList; 139 freeList = slots[index].next; 140 } 141 else 142 { 143 //当循环数量大于slots.Length值(初始7)时则会扩充slots,buckets的数量,以及重置对应hash值的取余 144 if (count == slots.Length) Resize(); 145 index = count; 146 count++; 147 } 148 //hash取余 149 int bucket = hashCode % buckets.Length; 150 //设置hash值 151 slots[index].hashCode = hashCode; 152 //指向当前的元素 153 slots[index].value = value; 154 //指向相同hash取余的上一个元素索引* 有了这个才能够在判断是否重复的地方减少比较量 155 slots[index].next = buckets[bucket] - 1; 156 //指向最近的相同元素 157 buckets[bucket] = index + 1; 158 } 159 return false; 160 } 161 162 void Resize() 163 { 164 //不理解要+1 保证奇数? 165 int newSize = checked(count * 2 + 1); 166 int[] newBuckets = new int[newSize]; 167 Slot[] newSlots = new Slot[newSize]; 168 Array.Copy(slots, 0, newSlots, 0, count); 169 for (int i = 0; i < count; i++) 170 { 171 int bucket = newSlots[i].hashCode % newSize; 172 newSlots[i].next = newBuckets[bucket] - 1; 173 newBuckets[bucket] = i + 1; 174 } 175 buckets = newBuckets; 176 slots = newSlots; 177 } 178 179 internal int InternalGetHashCode(TElement value) 180 { 181 //[....] DevDivBugs 171937. work around comparer implementations that throw when passed null 182 return (value == null) ? 0 : comparer.GetHashCode(value) & 0x7FFFFFFF; 183 } 184 185 internal struct Slot 186 { 187 //value的hash值 188 internal int hashCode; 189 //元素 190 internal TElement value; 191 //指向下一个元素索引 192 internal int next; 193 } 194 }
着重说说它去重的思路,代码可以拷出来调试一步一步走,会对下面的更能理解
他用到了hash环的思路,初始大小是7,图随便画的,丑陋还请海涵
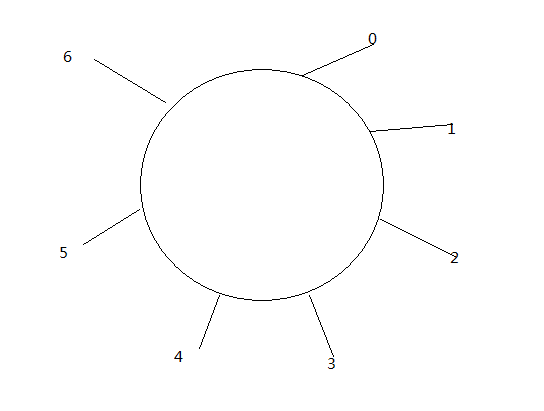
1.第一个Point元素hash值取余为3
solts[0]=当前元素 next=-1 hash=3
buckets[3]=1 指向第一个元素索引+1 其实也是当前的count数
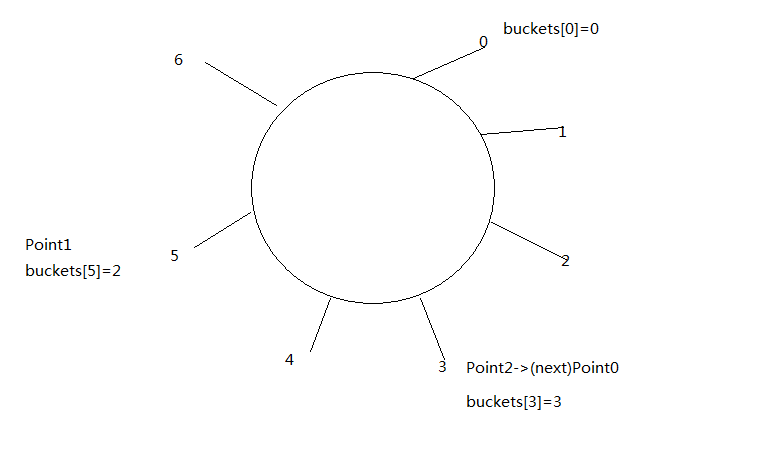
2.第二个Point元素hash值取余为5
solts[1]=当前元素 next=-1 hash=5
buckets[5]=2 指向第二个元素索引+1
....
3.假设第三个Point元素hash值为10,取余为3
会对相同取余结果值的元素比较,目前来说也就是第一步的Point元素 比较对应的hash值以及调用Equals方法 返回false(上面两部也会比较,但因为没有元素所以未强调)
则solts[2]=当前元素 next=0(这样子在第128行进行比较的时候就产生了一个类似链表性质) hash=10
buckets[3]=3 指向第三个元素索引+1
4.假设第四个Point元素跟第一个元素相同 也就是hash也为3
同样也会执行第128行 根据 buckets[3] 得到对应的第一个元素为3-1=2 取solts[2] 得到第三步的元素,进行比较, 很显然两个元素不相同,根据对应的next也就是0得到第一个元素solts[0]进行比较 返回true也就是存在相同元素,则去掉当前重复项。
很显然你会发现第二个元素没有进行比较,这样子就会较少数据的比较次数。
当元素越来越多的时候 144行的时候就会执行他的Resize方法,会将大小*2+1(为啥要+1?),对应的hash取余结果重写来计算
你会发现Distinct里面对GetHashCode依赖特别大,我发现很多人实现IEqualityComparer<T>接口时不会关注他的GetHashCode方法(只是返回了一个特定的int值),而只是实现了里面的Equals方法,通过上面的解释你会发现这样子其实比我们用两次for循环开销很大,所以强烈建议重写他的GetHashCode方法。
强调一点,当两个元素的相同时,那他的hashcode肯定也是相同的
希望这样的思路能在大家的coding中有所帮助