转自:https://www.sohu.com/a/292825608_467784
系统级性能优化通常包括两个阶段:性能剖析(performance profiling)和代码优化。性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码。代码优化的目标是针对具体性能问题而优化代码或编译选项,以改善软件性能。本篇主要讲性能分析中常用的工具——perf。
perf是一款Linux性能分析工具。Linux性能计数器是一个新的基于内核的子系统,它提供一个性能分析框架,比如硬件(CPU、PMU(Performance Monitoring Unit))功能和软件(软件计数器、tracepoint)功能。通过perf,应用程序可以利用PMU、tracepoint和内核中的计数器来进行性能统计。它不但可以分析制定应用程序的性能问题(per thread),也可以用来分析内核的性能问题。
总之perf是一款很牛逼的综合性分析工具,大到系统全局性性能,再小到进程线程级别,甚至到函数及汇编级别。
调优方向
可以从以下三种事件为调优方向:
- Hardware Event由PMU部件产生,在特定的条件下探测性能事件是否发生以及发生的次数。比如cache命中。
- Software Event是内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件。比如进程切换,tick数等。
- Tracepoint Event是内核中静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节(这些tracepint的对应的sysfs节点在/sys/kernel/debug/tracing/events目录下)。比如slab分配器的分配次数等。
perf 的使用
| 序号 | 命令 | 作用 |
| 1 | annotate | 解析perf record生成的perf.data文件,显示被注释的代码。 |
| 2 | archive | 根据数据文件记录的build-id,将所有被采样到的elf文件打包。利用此压缩包,可以再任何机器上分析数据文件中记录的采样数据。 |
| 3 | bench | perf中内置的benchmark,目前包括两套针对调度器和内存管理子系统的benchmark。 |
| 4 | buildid-cache | 管理perf的buildid缓存,每个elf文件都有一个独一无二的buildid。buildid被perf用来关联性能数据与elf文件。 |
| 5 | buildid-list | 列出数据文件中记录的所有buildid。 |
| 6 | diff | 对比两个数据文件的差异。能够给出每个符号(函数)在热点分析上的具体差异。 |
| 7 | evlist | 列出数据文件perf.data中所有性能事件。 |
| 8 | inject | 该工具读取perf record工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。 |
| 9 | kmem | 针对内核内存(slab)子系统进行追踪测量的工具 |
| 10 | kvm | 用来追踪测试运行在KVM虚拟机上的Guest OS。 |
| 11 | list | 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。 |
| 12 | lock | 分析内核中的锁信息,包括锁的争用情况,等待延迟等。 |
| 13 | mem | 内存存取情况 |
| 14 | record | 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析。 |
| 15 | report | 读取perf record创建的数据文件,并给出热点分析结果。 |
| 16 | sched | 针对调度器子系统的分析工具。 |
| 17 | 执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等。 | |
| 18 | stat | 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等。 |
| 19 | test | perf对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持perf的所有功能。 |
| 20 | timechart | 针对测试期间系统行为进行可视化的工具 |
| 21 | top | 类似于linux的top命令,对系统性能进行实时分析。 |
| 22 | trace | 关于syscall的工具。 |
| 23 | probe | 用于定义动态检查点。 |
全局性概况:
perf list查看当前系统支持的性能事件;
perf bench对系统性能进行摸底;
perf test对系统进行健全性测试;
perf stat对全局性能进行统计;
全局细节:
perf top可以实时查看当前系统进程函数占用率情况;
perf probe可以自定义动态事件;
特定功能分析:
perf kmem针对slab子系统性能分析;
perf kvm针对kvm虚拟化分析;
perf lock分析锁性能;
perf mem分析内存slab性能;
perf sched分析内核调度器性能;
perf trace记录系统调用轨迹;
最常用功能perf record,可以系统全局,也可以具体到某个进程,更甚具体到某一进程某一事件;可宏观,也可以很微观。
pref record记录信息到perf.data;
perf report生成报告;
perf diff对两个记录进行diff;
perf evlist列出记录的性能事件;
perf annotate显示perf.data函数代码;
perf archive将相关符号打包,方便在其它机器进行分析;
perf 将perf.data输出可读性文本;
可视化工具perf timechart
perf timechart record记录事件;
perf timechart生成output.svg文档;
火焰图
火焰图(Flame Graph)是由Linux性能优化大师Brendan Gregg发明的,和所有其他的trace和profiling方法不同的是,Flame Graph以一个全局的视野来看待时间分布,它从底部往顶部,列出所有可能的调用栈。其他的呈现方法,一般只能列出单一的调用栈或者非层次化的时间分布。
以典型的分析CPU时间花费到哪个函数的on-cpu火焰图为例来展开。CPU火焰图中的每一个方框是一个函数,方框的长度,代表了它的执行时间,所以越宽的函数,执行越久。火焰图的楼层每高一层,就是更深一级的函数被调用,最顶层的函数,是叶子函数。

火焰图的生成过程是:
- 先trace系统,获取系统的profiling数据
- 用脚本来绘制
脚本获取:git clone https://github.com/brendangregg/FlameGraph
下面通过实例来体验以下火焰图的生成过程:
#include<pthread.h>
func_d()
{
inti;
for(i= 0;i< 50000;i++);
}
func_a()
{
inti;
for(i= 0;i< 100000;i++);
func_d();
}
func_b()
{
inti;
for(i= 0;i< 200000;i++);
}
func_c()
{
inti;
for(i= 0;i< 300000;i++);
}
void* thread_fun(void* param)
{
while( 1) {
inti;
for(i= 0;i< 100000;i++);
func_a();
func_b();
func_c();
}
}
intmain(void)
{
pthread_ttid1,tid2;
intret;
ret=pthread_create(&tid1, NULL,thread_fun, NULL);
if(ret== -1){
...
}
ret=pthread_create(&tid2, NULL,thread_fun, NULL);
...
if(pthread_join(tid1, NULL)!= 0){
...
}
if(pthread_join(tid2, NULL)!= 0){
...
}
return0;
}
先用类似perf top分析出来CPU时间主要花费在哪里:
$ gcc test.c -pthread
$ ./a.out&
$ sudo perf top

perf top提示出来了fun_a()、fun_b()、fun_c(), fun_d(),thread_func()这些函数内部的代码是CPU消耗大户,但是它缺乏一个全局的视野,我们无法看出全局的调用栈,也弄不清楚这些函数之间的关系。火焰图则不然,我们用下面的命令可以生成火焰图(以root权限运行):
$ perf record -F 99 -a -g -- sleep 60
$ perf | ./stackcollapse-perf.pl > out.perf-folded
$ ./flamegraph.pl out.perf-folded > perf-kernel.svg
上述程序捕获系统的行为60秒钟,最后调用flamegraph.pl生成一个火焰图perf-kernel.svg,用看图片的工具就可以打开这个svg。
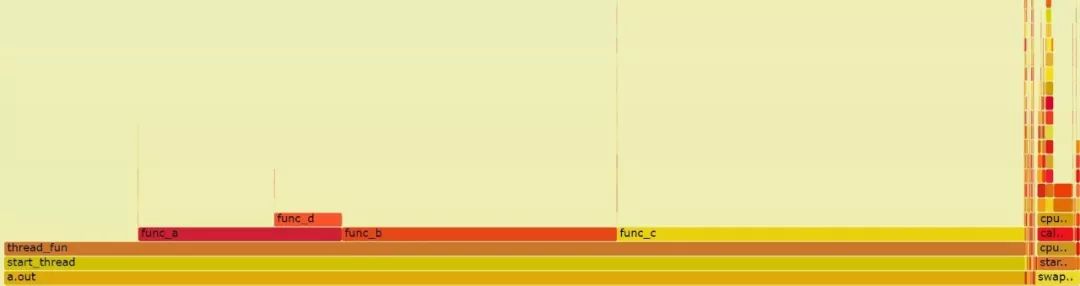
上述火焰图显示出了a.out中,thread_func()、func_a()、func_b()、fun_c()和func_d()的时间分布。
从上述火焰图可以看出,虽然thread_func()被两个线程调用,但是由于thread_func()之前的调用栈是一样的,所以2个线程的thread_func()调用是合并为同一个方框的。
除了on-cpu的火焰图以外,off-cpu的火焰图,对于分析系统堵在IO、SWAP、取得锁方面的帮助很大,有利于分析系统在运行的时候究竟在等待什么,系统资源之间的彼此伊伴。
比如,下面的火焰图显示,nginx的吞吐能力上不来的很多程度原因在于sem_wait()等待信号量。
关于火焰图的更多细节和更多种火焰图各自的功能,可以访问:
http://www.brendangregg.com/flamegraphs.html
本文转自公众号“人人都是极客”返回搜狐,查看更多