数仓英文名叫做Data Warehouse,简称DW。数据仓库的目的是为了构建面向分析的集成化数据环境,为了企业提供决策支持。
数据仓库是存放数据的,企业的各种数据都往数仓中存,主要目的就是为了分析数据,后续基于这些数据产生可供分析挖掘的数据,或者企业所需要的数据。比如企业每年的年度各维度分析报表等。所以数仓可以理解为面向分析的存储系统
数仓是面向主题的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和时变的(Time-Variant )数据集合,用以支持管理决策。
面向主题
数仓是面向主题的,企业会因为各个不同的主题来将企业中各个领域中不同的数据加载到一起进行分析,比如说(用户、订单、商品等),而操作型数据是为了支撑各个不同的业务所创立。
集成性
数仓的数据源于不同的业务领域,不同的系统环境,将繁杂的数据进行统一集成整合,这也是数仓建立之初最复杂、最繁琐的一步(ETL)。因为要统一各个系统环境的数据中的数据格式,数据类型,数据内容所带来的一系列的数据问题。
非易失性
数仓的数据不同意传统的操作型数据,需要根据业务的需求时时的更新,变动以及能迅速的获取当前的最新数据。数仓的数据多数都源于历史数据,所以数仓的数据也大多数是用来做历史分析报表的,一般极少会对这些数据进行频繁的更新以及变动。
时变性
数仓的数据是保护历史中各个粒度的数据,数仓中的数据有可能是某个特定的日期、星期、月份的数据,数仓的数据主要目的是为分析企业过去的一段时间的业务经营情况,以发掘隐藏的经营模式,虽然说用户不能去修改历史的数据,但是数据不是一成不变的,数据会随着时间的推移不断的变化,所以数仓也需要随着时间不断的更新数据,以适应决策的需要。
数仓DW与数据库DB的区别
我们了解最多的操作型数据库如MySQL,SQLserver、oracle等一系列关系型数据库。被统称为OLTP(On-Line Transaction Processing)联机事务型处理系统,也可以称为面向交易型处理系统,它是针对具体业务在数据库联机的日常操作,通常对极少数据进行增删查改。用户最关心的是响应时间和数据的安全性、完整性以及并发支持的用户数量等。传统操作型数据作为数据采集收纳管理的主要手段,主要用于操作型处理。
数仓作为面向分析处理数据系统,被统称为OLAP(On-Line Analytical Processing)联机分析型处理系统,一般是针对某些主题的历史数据的分析与决策。首先得明确一个要点,数仓的出现并不是为了取代数据库而存在的。
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
换句话说数仓的出现是为了分析当数据库存在大量的数据时所衍生而出的产品。是为了进一步发掘数据资源,为了决策产生的。绝不是什么所谓的“大型数据库”
数仓的分层架构
按照数据流入流出的过程,数仓的分层架构大致可以分为三层,数据源,数据仓库,数据应用。
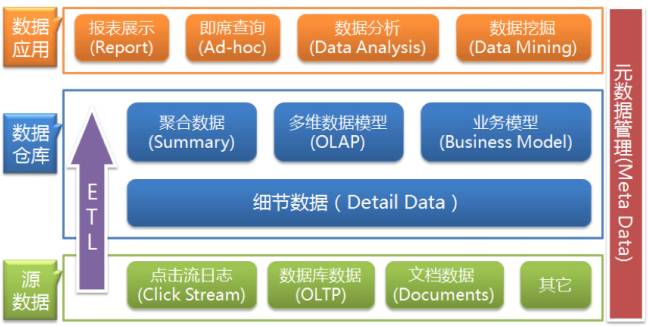
数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
- 源数据层(ODS):此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
- 数据仓库层(DW) :也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
- 数据应用层(DA或APP) :前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extra, 转化Transfer,装载Load)的过程,ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
为什么要对数据仓库分层?
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
元数据(Meta Date),主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。一般会通过元数据资料库(Metadata Repository)来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。元数据是数据仓库管理系统的重要组成部分,元数据管理是企业级数据仓库中的关键组件,贯穿数据仓库构建的整个过程,直接影响着数据仓库的构建、使用和维护。构建数据仓库的主要步骤之一是ETL。这时元数据将发挥重要的作用,它定义了源数据系统到数据仓库的映射、数据转换的规则、数据仓库的逻辑结构、数据更新的规则、数据导入历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据高效地构建数据仓库。用户在使用数据仓库时,通过元数据访问数据,明确数据项的含义以及定制报表。数据仓库的规模及其复杂性离不开正确的元数据管理,包括增加或移除外部数据源,改变数据清洗方法,控制出错的查询以及安排备份等。
元数据可分为技术元数据和业务元数据。技术元数据为开发和管理数据仓库的IT人员使用,它描述了与数据仓库开发、管理和维护相关的数据,包括数据源信息、数据转换描述、数据仓库模型、数据清洗与更新规则、数据映射和访问权限等。而业务元数据为管理层和业务分析人员服务,从业务角度描述数据,包括商务术语、数据仓库中有什么数据、数据的位置和数据的可用性等,帮助业务人员更好地理解数据仓库中哪些数据是可用的以及如何使用。由上可见,元数据不仅定义了数据仓库中数据的模式、来源、抽取和转换规则等,而且是整个数据仓库系统运行的基础,元数据把数据仓库系统中各个松散的组件联系起来,组成了一个有机的整体。
Hive
一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射成一张张数据表,并提供类SQL查询功能。其本质是将SQL语句转换为MapReduce的任务进行计算,底层是由HDFS进行存储,说白了可以理解为Hive是一个将SQL转换为MapReduce的工具,进一步甚至可以讲,Hive就是一个MapReduce的客户端。
为什么采用Hive?
- 采用类SQL语法去操作数据,提供快速开发的能力。
- 避免了去写MapReduce,减少开发人员的学习成本。
- 功能扩展很方便。
Hive架构
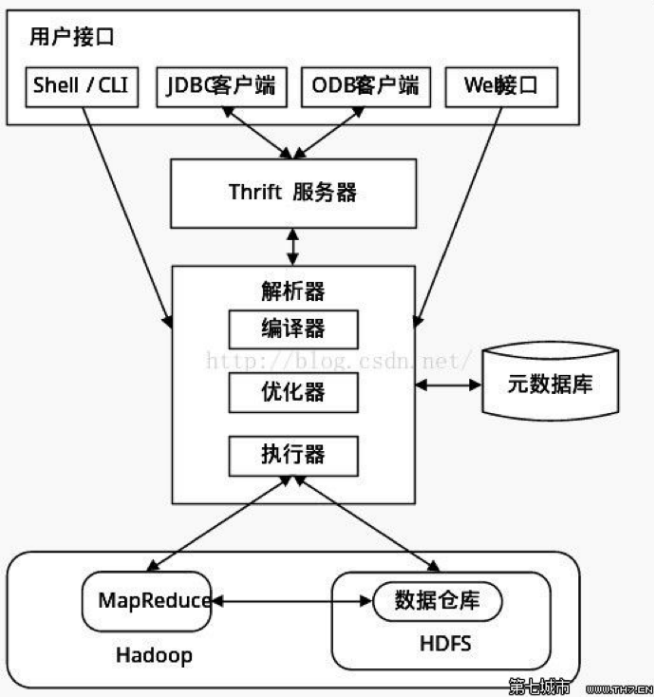
- 用户接口: 包括CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
- 元数据存储: 通常是存储在关系数据库如mysql/derby中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器、执行器: 完成HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS 中,并在随后有MapReduce 调用执行。
Hive与Hadoop之间的关系
Hive通过HDFS存储数据,通过MapReduce操作数据。
Hive与传统数据库的区别
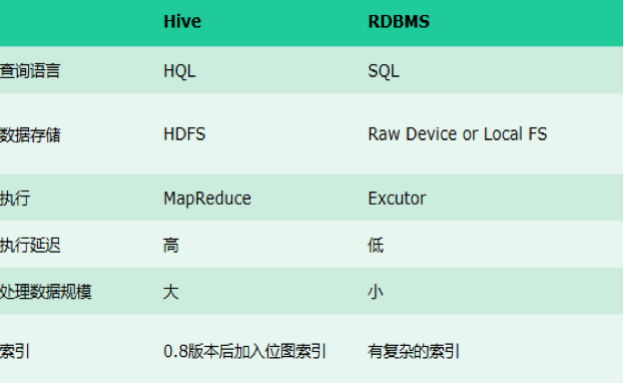
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
Hive的安装
我们选用的Hive版本是2.1.1,下载地址为:http://archive.apache.org/dist/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz 下载完成后将安装包上传到我们三台机器的/export/software目录中去。
第一步:解压安装包到/export/servers目录中

第二步:安装MySQL环境(前面文章有详细描述,不在赘述)
第三步:修改Hive配置文件
修改hive-env.sh
1 cd /export/servers/apache-hive-2.1.1-bin/conf 2 3 cp hive-env.sh.template hive-env.sh
#修改配置文件内容
1 HADOOP_HOME=/export/servers/hadoop-2.7.5 2 export HIVE_CONF_DIR=/export/servers/apache-hive-2.1.1-bin/conf
修改hive-site.xml
1 cd /export/servers/apache-hive-2.1.1-bin/conf 2 vim hive-site.xml


1 <?xml version="1.0" encoding="UTF-8" standalone="no"?> 2 3 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 4 <configuration> 5 <property> 6 <name>javax.jdo.option.ConnectionUserName</name> 7 <value>root</value> 8 </property> 9 <property> 10 <name>javax.jdo.option.ConnectionPassword</name> 11 <value>123456</value> 12 </property> 13 <property> 14 <name>javax.jdo.option.ConnectionURL</name> 15 <value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> 16 </property> 17 <property> 18 <name>javax.jdo.option.ConnectionDriverName</name> 19 <value>com.mysql.jdbc.Driver</value> 20 </property> 21 <property> 22 <name>hive.metastore.schema.verification</name> 23 <value>false</value> 24 </property> 25 <property> 26 <name>datanucleus.schema.autoCreateAll</name> 27 <value>true</value> 28 </property> 29 <property> 30 <name>hive.server2.thrift.bind.host</name> 31 <value>node03</value> 32 </property> 33 </configuration>
第四步:添加MySQL的连接驱动包到hive的lib目录下
hive使用mysql作为元数据存储,必然需要连接mysql数据库,所以我们添加一个mysql的连接驱动包到hive的安装目录下,然后就可以准备启动hive了将我们准备好的mysql-connector-java-5.1.38.jar 这个jar包直接上传到/export/servers/apache-hive-2.1.1-bin/lib 这个目录下即可
第五步:配置hive的环境变量
1 vim /etc/profile #添加hive环境变量
1 export HIVE_HOME=/export/servers/apache-hive-2.1.1-bin 2 export PATH=:$HIVE_HOME/bin:$PATH
至此我们就全部安装完Hive了。
Hive的三种交互方式
第一种交互方式:bin/hive
1 cd /export/servers/apache-hive-2.1.1-bin/ 2 bin/hive
第二种交互方式:使用SQL脚本和SQL语句进行交互。不进入hive客户端,直接执行SQL语句与脚本
1 cd /export/servers/apache-hive-2.1.1-bin 2 bin/hive -e "create database if not exists mytest;"
或者我们可以将我们的hql语句写成一个sql脚本然后执行
1 cd /export/servers 2 vim hive.sql
1 create database if not exists mytest; 2 use mytest; 3 create table stu(id int,name string);
第三种交互方式:通过hive -f 来执行我们的sql脚本
1 bin/hive -f /export/servers/hive.sql
Hive的基本操作
hive的大多数操作类似于我们的传统数据库,这里就不在画蛇添足了,相信大家比我都还熟悉。这里讲一些不同。
1.插入数据:虽然可以使用我们SQL中的Insert语句,但是那种方式是走MapReduce的不是很推荐,官方比较推荐的方式是
1 --加载系统本地数据到指定表 2 load data local inpath '/export/servers/hivedatas/student.csv' into table student; 3 --加载数据并覆盖现有数据 4 load data local inpath '/export/servers/hivedatas/student.csv' overwrite into table student; 5 --加载HDFS数据到指定表 6 load data inpath '/hivedatas/techer.csv' into table teacher;
7 --加载数据到多个分区表中
8 load data local inpath '/export/servers/hivedatas/score.csv' into table score2 partition(year='2018',month='06',day='01');
2.数据库相关
1 --创建数据库到指定位置 2 create database myhive2 location '/myhive2'; 3 --创建数据库并标记键值对信息 4 create database foo with dbproperties ('owner'='sky9408251', 'date'='20190120'); 5 --查看数据库的键值对信息 6 describe database extended foo; 7 --修改数据库的键值对信息: 8 alter database foo set dbproperties ('owner'='sky9408251'); 9 --查看数据库更多详细信息 10 desc database extended myhive2;
3.数据表相关
1 create [external] table [if not exists] table_name ( 2 col_name data_type [comment '字段描述信息'] 3 col_name data_type [comment '字段描述信息']) 4 [comment '表的描述信息'] 5 [partitioned by (col_name data_type,...)] 6 [clustered by (col_name,col_name,...)] 7 [sorted by (col_name [asc|desc],...) into num_buckets buckets] 8 [row format delimited fields terminated by '分隔符']
9 [storted as ....]
10 [location '指定表的路径']
4.排序分组相关
1 --分区排序(DISTRIBUTE BY) 2 select * from score distribute by s_id sort by s_score; 3 --分区加分组排序CLUSTER BY(distribute by 与sort by相同时用CLUSTER --BY)以下两种写法意义相同 4 select * from score cluster by s_id; 5 select * from score distribute by s_id sort by s_id;
Hive Shell参数
1 bin/hive [-hiveconf x=y]* [<-i filename>]* [<-f filename>|<-e query-string>] [-S]
1、 -i 从文件初始化HQL。
2、 -e从命令行执行指定的HQL
3、 -f 执行HQL脚本
4、 -v 输出执行的HQL语句到控制台
5、 -p connect to Hive Server on port number
6、 -hiveconf x=y Use this to set hive/hadoop configuration variables. 设置hive运行时候的参数配置
Hive参数配置方式
开发Hive应用时,不可避免地需要设定Hive的参数。设定Hive的参数可以调优HQL代码的执行效率,或帮助定位问题。
对于一般参数,有以下三种设定方式:
-
- 配置文件
- 命令行参数
- 参数声明
配置文件 :Hive的配置文件包括
-
- 用户自定义配置文件:$HIVE_CONF_DIR/hive-site.xml
- 默认配置文件: $HIVE_CONF_DIR/hive-default.xml
另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。
配置文件的设定对本机启动的所有Hive进程都有效。
命令行参数: 启动Hive(客户端或Server方式)时,可以在命令行添加-hiveconf param=value来设定参数,例如:
1 bin/hive -hiveconf hive.root.logger=INFO,console
1 set mapred.reduce.tasks=100;
这一设定的作用域也是session级的。
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在Session建立以前已经完成了。
参数声明 > 命令行参数 > 配置文件参数(hive)