Hive架构
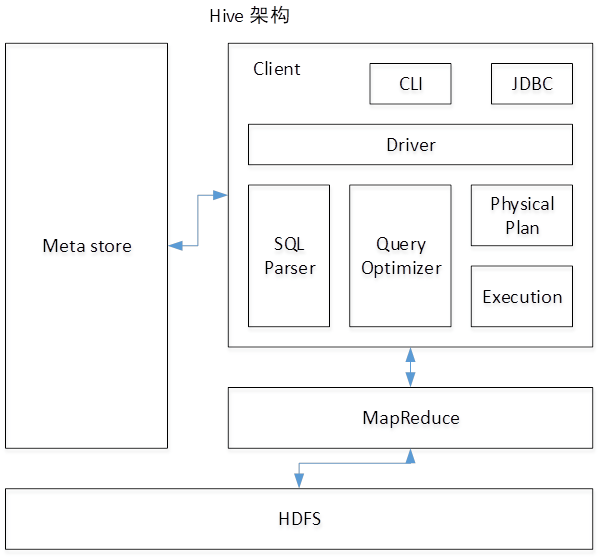
- 如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
- 1)用户接口:Client CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
- 2)元数据:Metastore 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等; 默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- 3)Hadoop 使用HDFS进行存储,使用MapReduce进行计算。
- 4)驱动器:Driver
- (1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- (2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
- (3)优化器(Query Optimizer):对逻辑执行计划进行优化。
- (4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。
创建表及将本地数据导入到HDFS
创建内部表
--创建内部表
CREATE TABLE article(sentence STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '
';
--从本地导入数据:相当于将path数据hadoop fs -put /hive/warehouse/badou.db/
LOAD DATA LOCAL INPATH '/home/badou/mr/code/The_Man_of_Property.txt'
INTO TABLE article;
--查询数据
select * from article limit 3;创建外部表
--外部表
-- hadoop fd -mkdir /data/ext
-- hadoop fd -cp /data/The_Man_of_Property.txt /data/ext
CREATE EXTERNAL TABLE article2 (sentence STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '
'
STORED AS TEXTFILE
LOCATION '/data/ext';在hive/warehouse/badou.db下没有外部表文件,但是可以在表中查询到数据
Wordcount用hive写法
SELECT word, count(1) as cnt
from (
SELECT
explode(split(sentence, ' '))
as word from article
) t
GROUP BY word
LIMIT 100;【注】运行hive前需要先将Hadoop及MySQL启动
爆款商品有哪些/top N 出现次数最多的商品
SELECT word, count(1) as cnt
from (
SELECT
explode(split(sentence, ' '))
as word from article
) t
GROUP BY word
ORDER BY cnt DESC
LIMIT 100;【注】ORDER BY 只会产生一个reduce任务
内部表&外部表
内部表:数据需要存储在Hive目录对应的文件夹下,即使HDFS上在其他路径下已经存在 外部表:可以直接调用HDFS上的数据
| 内部表 | 外部表 |
|---|---|
| 数据需要存储在Hive目录对应的文件夹下,即使HDFS上在其他路径下已经存在 | 可以直接调用HDFS上的数据 |
| create tabel name | create external table location 'hdfs_path' name(必须是文件夹路径) |
分区表partition
- 建表
CREATE TABLE art_dt(sentence STRING)
PARTITIONED BY(dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '
';- 从hive表中的数据插入到新表(分区表)中
--从hive表中的数据插入到新表(分区表)中
INSERT OVERWRITE TABLE art_dt PARTITION(dt='20180924')
SELECT * FROM article LIMIT 100;
INSERT OVERWRITE TABLE art_dt PARTITION(dt='20180925')
SELECT * FROM article LIMIT 100;
-- [root@master ~]# hadoop fs -ls /user/hive/warehouse/badou.db/art_dt
-- Found 1 items
-- 2018-09-24 08:45 /user/hive/warehouse/badou.db/art_dt/dt=20180924- 查看分区表列表
--查看分区表列表
SHOW PARTITIONS art_dt;
SELECT * FROM art_dt WHERE dt
BETWEEN '20180924' AND '20180925' LIMIT 10;- 业务应用场景--Partition 实际工作中如何产生,用在什么数据上?
-
每天都会产生用户浏览,点击,收藏,购买的记录。 按照天的方式去存储数据,按天做partition
-
app m pc
- logs/dt=20180924/type=app
- logs/dt=20180924/type=m
- logs/dt=20180924/type=pc
- 数据库中数据有用户的属性, 年龄, 性别, blog等 每天有新增的用户,修改信息 dt=20180924 和dt=20180924会造成大量信息冗余。这个时候应该用 OVERWRITE
- overwrite++ 7 每天做overwrite dt = 20180922,这天中的数据包含这天之前的所有用户信息.
当天之前所有的全量数据。 存7个分区,冗余七份,防止丢失数据。
分桶表Bucket
- 创建总表udata
-- 创建表udata
CREATE TABLE udata(
user_id STRING ,
item_id STRING ,
rating STRING ,
`timestamp` STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '
;
--导入数据
LOAD DATA LOCAL INPATH '/home/badou/data/u.data'
INTO TABLE udata;
--设置显示字段名(显示表头)
SET hive.cli.print.header=true;
select * from udata limit 50;- 创建分桶表
-- 创建分桶表
CREATE TABLE bucket_users
(
user_id STRING ,
item_id STRING ,
rating string,
`timestamp` string
)
CLUSTERED BY(user_id)
INTO 4 BUCKETS;- 设置bucket数量,否则不会生成4个分桶
SET hive.enforce.bucketing = true;- 插入数据,将之前建立好的udata表中数据插入到4个分桶中,此时会产生4个reduce
-- 插入数据,将之前建立好的udata表中数据插入到4个分桶中,此时会产生4个reduce
INSERT OVERWRITE TABLE bucket_users
SELECT
cast(user_id as INT) as user_id,
item_id,
rating,
`timestamp`
from udata;