1.转换的并行
转换的并行是改变复制的数量
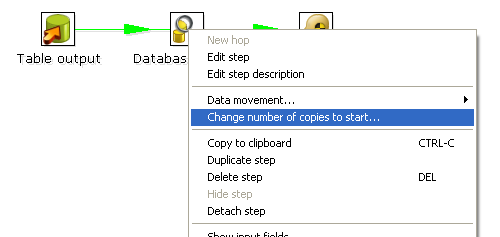

上面的转换相当于下面的:
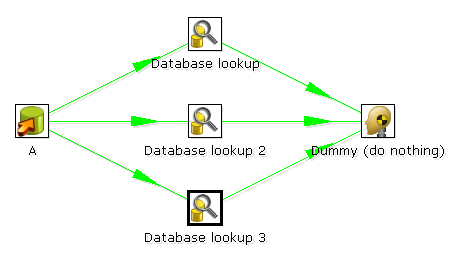
实际是把一个任务拆成三部分执行,相当于在一个数据库连接中做了三次查询,数据库连接的开销没有增加,但是有三个进程一起执行。
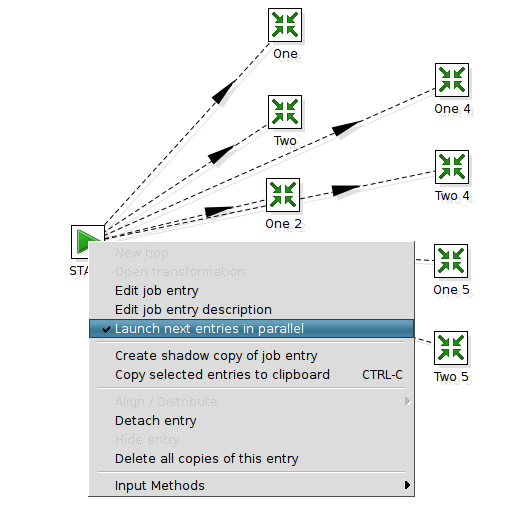
只需要在"START"设置即可。
建议:将job的条目都做成子job.(To do this, we suggest you wrap up the parallel work in a separate Job.)
注意,并行执行时,job条目不会按顺序执行,所以有依赖性的转换不能并行执行。
3.集群
集群就是使用多个服务器共同处理任务,某些情况下能加快处理速度。
关于集群的搭建请参考博客中《KETTLE集群搭建》一文。