总的步骤是下载压缩包,解压,授予权限,修改配置文件,压缩修改后的文件发送到其他节点,其他节点解压,授予权限,修改配置文件,所有节点添加环境变量。
1.下载压缩包
去zookeeper的官网下载压缩包 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
2.解压
解压缩到/usr/local目录下,并重新命名,添加权限,后面如有解压缩到/usr/local/时都要添加权限。
sudo tar -zxf zookeeper-3.4.13.tar.gz -C /usr/local cd /usr/local/ sudo mv zookeeper-3.4.13/ zookeeper sudo chown -R hadoop:hadoop /usr/local/zookeeper
3.配置环境
进入zookeeper/conf的目录下,将zoo_sample.cfg样本配置文件复制一份出来并重命名为 zoo.cfg
cp zoo_sample.cfg zoo.cfg
设置内容,注意server.1开头的这几行,需要更改集群中其他节点的ip地址,或根据hosts映射文件改为主机名。如下所示,ip地址需要改,x需要改。
server.x= 192.168.0.1:2888:3888
日志目录和数据目录修改为
dataLogDir=/usr/local/zookeeper/logs
dataDir=/usr/local/zookeeper/data
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataLogDir=/usr/local/zookeeper/logs dataDir=/usr/local/zookeeper/data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # autopurge.snapRetainCount=500 autopurge.purgeInterval=24 server.1= 192.168.0.1:2888:3888 server.2= 192.168.0.4:2888:3888 server.3= 192.168.0.2:2888:3888 # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
在上面提到的dataDir目录下新建myid的文件,并将自己的x写入,一个数字。注意x和ip的对应关系。
4 在多节点配置
将修改后的zookeeper文件打包,并传输到其他的所有节点.
tar -zcf ~/zookeeper.tar.gz /usr/local/zookeeper scp ~/zookeeper.tar.gz slave3:~
ssh登陆到slave3
解压到/usr/local,添加权限,命令参考第二步
此时,修改/usr/local/zookeeper/data/myid文件并将里面的数字改为ip对应的server .x中的x
每个节点都要完成这里的操作。
5 添加环境变量
每个节点都要做本部分操作
sudo vim ~/.bashrc
将/usr/local/zookeeper/bin添加到环境变量
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin:/usr/local/zookeeper/bin
格式如上,如果以前有环境变量就在最后面添加冒号再添加环境变量,执行下面的命令使环境变量生效
source ~/.bashrc
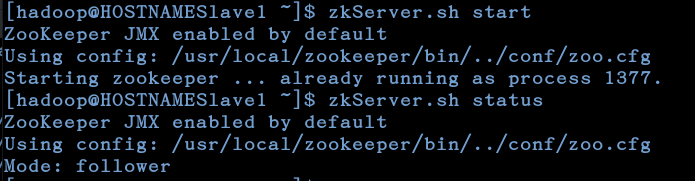
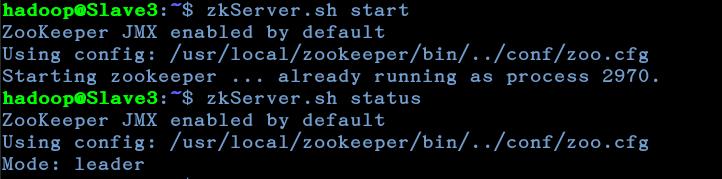
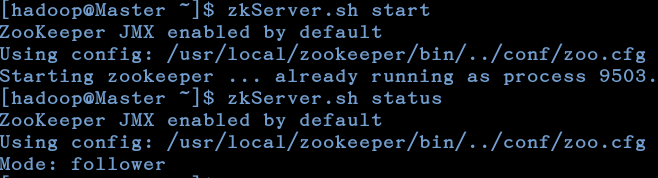
6.启动zookeeper
每个节点都要启动
zkServer.sh start
查看状态
zkServer.sh status
停止
zkServer.sh stop
查看日志
cat zookeeper.out
如图,必须得所有server都启动后才能查看启动的状态,一个leader和多个follower