HTTP(HyperText Transfer Protocol,超文本传输协议)基于TCP/IP通信协议来传递数据(HTML文件, 图片, 查询结果等),用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器。所有的WWW文件都必须遵守这个标准。HTTP使用统一资源标识符(URI, Uniform Resource Identifiers)来传输数据和建立连接。
HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
- 基本原理:
浏览器作为HTTP客户端,向HTTP服务端(即WEB服务器)发送所有请求。WEB服务器收到请求后,向客户端发送请求响应。
WEB服务器包括Apache服务器、IIS(Internet Information Services)服务器等。HTTP的默认端口号为80,也可改为8080或其它。
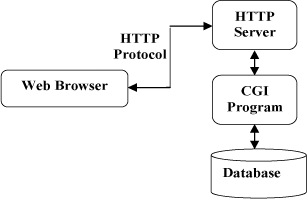
图 1 HTTP协议通信流程
- 三点注意事项:
·HTTP是无连接的:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后即断开连接——节省传输时间。
·HTTP是媒体独立的:只要客户端和服务器知道如何处理数据内容,任何类型的数据都可以通过HTTP发送。客户端和服务器指定适合的MIME-type内容类型。
·HTTP是无状态的:无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
- CGI(Common Gateway Interface)是HTTP服务器与其它机器上的程序进行“交谈”的一种工具,它使网页具有交互功能。
HTTP消息结构
- 客户端请求消息
客户端请求格式包括:请求行(request line)、请求头部(header)、空行和请求数据四个部分。如下图:

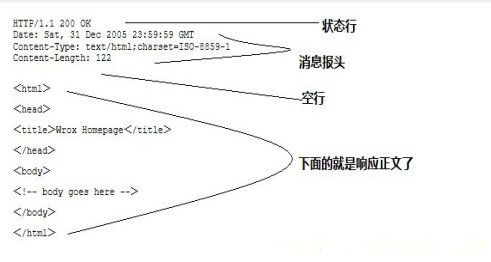
- 服务器响应消息
服务器响应也包括四个部分:状态行、消息报头、空行和响应正文。如下图:
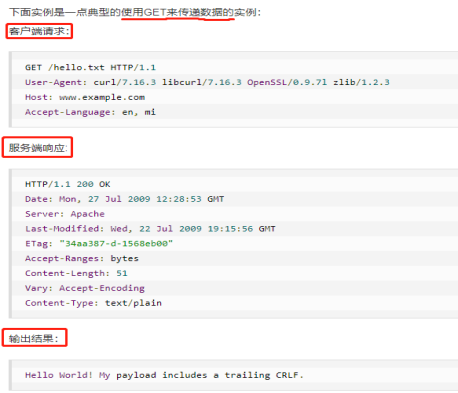
实例:
HTTP协议的8种请求类型/方法:
·OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法;也可以利用向Web服务器发送 ‘*’请求来测试服务器的性能。
·HEAD:类似于GET请求,只不过不返回响应体,即没有具体内容。可以获取包含在响应消息头中的元信息,即用于获取报头。
·GET:向特定的资源发出请求。请求指定的页面信息,并返回实体主体。
·POST:向指定资源提交数据进行处理请求(如提交表单或上传文件等)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
·PUT:向指定资源位置上传其最新内容。从客户端向服务器传送数据,以取代指定的文档的内容。
·DELETE:请求服务器删除Request-URL所标识的资源/指定页面。
·TRACE:回显服务器收到的请求,主要用于测试或诊断。
·CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
实际中常用的只有GET和POST,其它请求方式都可以通过这两种方式间接实现。
HTTP响应头信息
|
应答头 |
说明 |
|
Allow |
服务器支持哪些请求方法,如GET、POST等 |
|
Content-Encoding |
文档的编码方法。只有在解码之后才可以得到Content-Type头指定的内容类型。 利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE4、IE5才支持它。因此,Servlet应该通过查看Accept-Encoding头,即request.getHeader("Accept-Encoding")检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
|
Content-Length |
表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入byteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream())发送内容。 |
|
Content-Type |
表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
|
Date |
当前的GMT时间。可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
|
Expires |
应该在什么时候认为文档已经过期,从而不再缓存它。 |
|
Last-Modified |
文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
|
Location |
表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
|
Refresh |
表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。 |
|
Server |
服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
|
Set-Cookie |
设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。 |
|
WWW- Authenticate |
客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。 |
HTTP状态码/Status Code
当访问一个网页时,浏览器会向网页所在的服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头/server header,用以响应浏览器的请求。
常见的HTTP状态码:
·200 — 请求成功
·301 — 资源(网页等)被永久转移到其它URL
·404 — 请求的资源不存在
·500 — 内部服务器错误
状态码分类:
HTTP状态码由三个十进制数字组成,第一个数字定义了状态码的类型。共分为以下5种类型:
①1** — 信息,服务器收到请求,需要请求者继续执行操作
②2** — 成功,操作被成功接收并处理
③3** — 重定向,需要进一步的操作以完成请求
④4** — 客户端错误,请求包含语法错误或无法完成请求
⑤5** — 服务器错误,服务器在处理请求的过程中发生了错误
# 详细的HTTP状态码列表:
https://www.runoob.com/http/http-status-codes.html
URL和URI
·URI = Universal Resource Identifier, 统一资源标识符
·URL = Universal Resource Locator, 统一资源定位符
·URN = Universal Resource Name, 统一资源名称
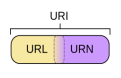
如上图,URI可以分为URL、URN、URL和URN的结合。URN像是一个人的名字,而URL就像一个人的地址。使URI成为URL的就是那个访问机制,如http:// 或者 ftp://,当然还有其它的。
下面两个是 URL:
ftp://ftp.is.co.za/rfc/rfc1808.txt
http://www.ietf.org/rfc/rfc2396.txt
下面两个只是URI,而不是URL:
tel:+1-816-555-1212
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
当替代web网址时,使用URI更准确,“URL”这个术语正在被弃用。我们经常使用的URI不是严格技术意义上的URL。例如:你需要的文件在files.hp.com. 这是URI,但不是URL—--系统可能会对很多协议和端口都做出正确的反应。访问http://files.hp.com 和ftp://files.hp.com.就可能得到完全不同的内容。