前言:在集成Slickflow.NET 引擎组件过程中,引擎组件需要将用户,角色等资源数据读取进来,供引擎内部调用;而企业客户都是有自己的组织架构模型,在引入模块化架构设计后,引擎组件的集成性更加友好便捷。
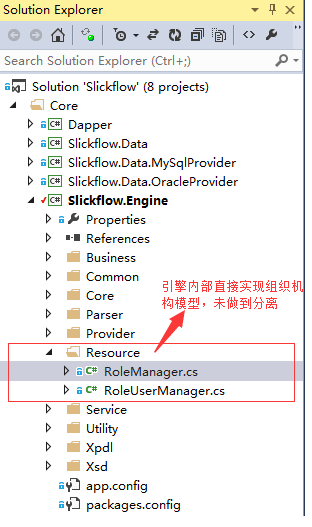
1. 未采用模块化设计之前的项目结构
在引擎内部,创建了Resource的目录,用于组织机构模型数据的处理,而且仅作了用户和角色相关的数据读取,未涉及到组织机构模型;比如部门和员工等信息。这样当用户集成自己的组织架构模型时候,就要扩展此部分代码,对引擎内部的统一性造成一定影响,不便于用户的后期版本升级。
2. 采用模块化设计之后的项目结构
新增加了Slickflow.Module项目,用于统一定义所有的模块化接口,包含组织机构模型接口。后期可能新增加的模型有权限模型,数据对接模型等。在Slickflow.Module项目里面主要申明标准接口和实体的定义。实体用于引擎组件内部使用,假如企业客户所使用的实体属性字段不同,需要做实体之间的转换。
添加Slickflow.Module项目之后,也就是要对标准接口和实体进行实现,比如Slickflow.Module.Resource项目就是对组织机构模型的具体实现,每个企业客户关于自有的组织机构模型业务代码,就可以添加到这里。用户不用关注引擎内部,而直接在该项目中修改增加代码即可。这样做到了组织机构模型跟引擎内部逻辑的分离。

3. 模块化架构设计原则
为何要进行模块化设计? 在引擎组件集成过程中,引擎内部功能虽然比较稳定,但是组织架构等模块却容易引起变化,如何方便用户修改扩展通常带来一定的困扰。而采用模块化架构设计后,问题被分离出来,首先定义好标准化的接口和实体,然后客户自己实现自有的模块项目就可以。这样保证了系统在整体性上的稳定。
1) 始终分离容易变化的部分
个体功能的多样性是一种自然存在的法则,不能强求用户的意志,而要从系统上做到包容。包容的方式就是将变化的部分分离出来,让用户自己去实现各种特性,从而达到对业务集成的满意度。
2) 保持核心功能的稳定性
在分离变化的部分后,引擎提供的核心功能会更加稳定,模块化的组件会被按照依赖注入的方式被引入到引擎组件内部,外部的模块和引擎内部做到了一种合理的交流交互。
3) 方便核心功能的后期升级
引擎版本会不断升级,模块的标准化接口也会不断升级。在采用模块化架构设计后,用户会关注两个升级指标,一个是引擎核心功能,一个是标准化的模块定义。职责上的分离,将会帮助客户认识系统核心和外部模块的边界,保持对引擎组件的熟悉。
4. 总结
Slickflow项目组致力于良好的软件架构设计,模块化架构设计和实践是我们在设计引擎组件过程中的原创思路,其目的是让用户始终能够升级和扩展工作流系统,保持整个系统的稳定性。欢迎读者继续关注和使用Slickflow.NET 引擎组件。
