hadoop、spark、flink、kafka、zookeeper安装参照本博客部署安装
组件版本选择
hadoop2.7.5
spark-2.4.8-bin-hadoop2.7
flink-1.13.1-bin-scala_2.11
kafka_2.13-2.6.2
zookeeper-3.6.3
maven安装(版本>=3.3.1)
官网下载maven:http://maven.apache.org/download.cgi,这里下载apache-maven-3.8.4-bin.tar.gz
# cd /opt
解压
# tar -zxvf apache-maven-3.8.4-bin.tar.gz
配置环境变量
# vim /etc/profile
添加
export MAVEN_HOME=/opt/apache-maven-3.8.3
export PATH=$MAVEN_HOME/bin
检查版本
# mvn -v
Hudi安装
# cd /home/hadoop/app
# git clone https://github.com/apache/hudi
# cd hudi
修改各组件版本
# vim pom.xml
<flink.version>1.13.1</flink.version>
<hadoop.version>2.7.5</hadoop.version>
<spark2.version>2.4.8</spark2.version>
编译
# mvn clean package -DskipTests
编译成功
进入hudi
# cd /home/hadoop/app/hudi/hudi-cli/
# ./hudi-cli.sh
flink cdc编译安装
# cd /home/hadoop/app
# git clone https://github.com/ververica/flink-cdc-connectors
# cd flink-cdc-connectors
修改配置文件pom.xml
# vim pom.xml
<flink.version>1.13.1</flink.version>
编译安装
# mvn clean install -DskipTests
flink集群添加cdc jar
将jar包放入flink集群
mysql
# cd /home/hadoop/app/flink-cdc-connectors/flink-sql-connector-mysql-cdc/target
# cp flink-sql-connector-mysql-cdc-2.2-SNAPSHOT.jar /home/hadoop/app/flink/lib/
pg
# cd /home/hadoop/app/flink-cdc-connectors/flink-sql-connector-postgres-cdc/target
# cp flink-sql-connector-postgres-cdc-2.2-SNAPSHOT.jar /home/hadoop/app/flink/lib/
kafka
# cd /home/hadoop/app/flink-cdc-connectors/flink-format-changelog-json/target
# cp flink-format-changelog-json-2.2-SNAPSHOT.jar /home/hadoop/app/flink/lib/
重启flink集群(master节点)
# cd /home/hadoop/app/flink/bin/
# ./stop-cluster.sh
# ./start-cluster.sh
flink cdc测试
mysql sink
Flink SQL>SET execution.checkpointing.interval = 3s;
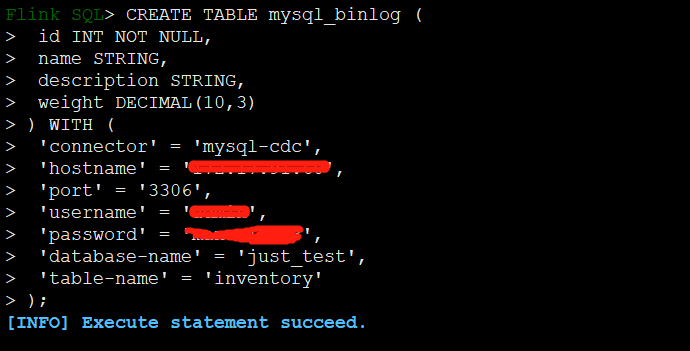
Flink SQL>CREATE TABLE mysql_binlog (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'xxx',
'password' = 'xxxx',
'database-name' = 'just_test',
'table-name' = 'inventory'
);
Flink SQL>select id,name,description,weight from mysql_binlog;
报错:[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: The primary key is necessary when enable 'Key: 'scan.incremental.snapshot.enabled' , default: true (fallback keys: [])' to 'true'
解决:mysql端ID为主键,flink client端建表未指定主键,需要添加主键
CREATE TABLE mysql_binlog (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3),
primary key(id) not enforced
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'xxx',
'password' = 'xxxx',
'database-name' = 'just_test',
'table-name' = 'inventory'
);
Flink SQL>select id,name,description,weight from mysql_binlog;
报错:Exception in thread "main" org.apache.flink.table.client.SqlClientException: Unexpected exception. This is a bug. Please consider filing an issue.
at org.apache.flink.table.client.SqlClient.startClient(SqlClient.java:201)
at org.apache.flink.table.client.SqlClient.main(SqlClient.java:161)
Caused by: java.lang.NoClassDefFoundError: com/fasterxml/jackson/databind/ObjectMapper
解决:copy的jar包路径错误,不是/home/hadoop/app/flink-cdc-connectors/flink-connector-mysql-cdc/target而应该是/home/hadoop/app/flink-cdc-connectors/flink-sql-connector-mysql-cdc/target,要删掉flink/lib下的jar包重新copy
Flink SQL>select id,name,description,weight from mysql_binlog;
报错:[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.runtime.client.JobSubmissionException: Failed to submit JobGraph
解决:flink任务只能在active NameNode上提交
Flink SQL>select id,name,description,weight from mysql_binlog;
报错:[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'mysql-cdc' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.
解决:flink各个节点都要把mysql-cdc jar添加进去