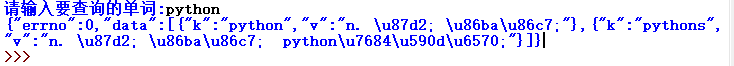1、Get方法
这里包含一个爬取百度图片,并保存本地的小爬虫……(包含关于Get方法补充的细节)
#Authors:xiaobei
import urllib.request
import urllib.parse
url = 'http://baidu.com/index.html'
url_2 = 'http://file02.16sucai.com/d/file/2014/0704/e53c868ee9e8e7b28c424b56afe2066d.jpg'
# 假如参数有很多
name = 'Jane'
age = '18'
sex = '女'
height = '180'
data = {
'name':name,
'age':age,
'sex':sex,
'height':height,
}
# urlencode提供参数封装和url标准编码
query_string = urllib.parse.urlencode(data)
url = url + '?' + query_string # Get方式构建请求对象
print(url)
# 伪装自己的头部(简单防反爬)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.42 Safari/537.36'
}
# 构建Get请求对象
request = urllib.request.Request(url = url_2,headers = headers)
reponse = urllib.request.urlopen(url = request)
print(reponse.read(100))
urllib.request.urlretrieve(url_2,'baidu_image.jpg') # retrieve 检索,取回,获取 (将URL内容保存在文件制定文件路径中),可独立与urlopen()
## url 只能由特定的字符组成,如果出现其他字符 ,比如:¥、$、空格、中文等,就要对其编码
## ret = urllib.parse.quote(url) # 编码成标准url
## ret1 = urllib.parse.unquote(url_2) # 将标准url翻译成通俗格式
## print('ret',ret)
## print('ret1',ret1)
# reponse:urlopen()用法
##1. print(reponse.read(100).decode())
##2. print(reponse.readlines(5).decode())
##3. print(reponse.geturl())
##4. print(reponse.getheaders())
##5. print(reponse.getcode())
爬取图片如下:

2.Post方法
关于百度翻译返回内容的简单爬取(不作数据解析)
#Authors:xaiobei
import urllib.request
import urllib.parse
post_url = 'https://fanyi.baidu.com/sug'
word = input('请输入要查询的单词:')
# 构建Post表单
form_data = {
'kw':word,
}
# 处理post表单数据
form_data = urllib.parse.urlencode(form_data).encode()# 两次encode但意义不同
# 构建请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.42 Safari/537.36',
}
# 构建请求对象
request = urllib.request.Request(url = post_url,headers = headers)
# 发送请求数据
response = urllib.request.urlopen(request,data = form_data)# post提交需要参数data,data为字节型
print(response.read().decode())
运行效果如下: