一.特殊编码处理
存储集合数据的时候会采用压缩技术,以使用更少的内存存储更多的数据;如Hashes,Lists,Sets和Sorted Sets,当这些集合中数据小于一个给定的数量是,存储的数据会被一种非常节省内存的方式进行编码,使用这种编码理论上至少节约10倍以上的内存(平均节省5倍以上)。这是使用CPU换内存的编码,所以可以在redis.conf配置文件中更改阈值;超过这个值,就会转换成正常的散列表;
二.使用32位的redis
使用32位的redis,对于每一个key,将会有更少的内存,因为32为程序,指针占用的字节数更少;但是整个redis实例使用的内存将被限制在4G下;RDB和AOF文件是不分32位和64位的,所以你可以使用64位的redis恢复32位的RDB备份文件,相反亦然;
三.位级别和字 级别的操作
GETRANGE,SETRANGE,GETBIT,SETBIT使用这些命令,你可以把redis的字符串当做一个随机读取的(字节)数组;例如,可以把性别用1和0代表,存一个bit,这样1亿个用户只用了大约12M内存,也可以存储一个字节的信息;
四.尽可能使用散列表
小散列表所占的内存非常小,所以尽可能的将你的数据模型抽象到一个散列表里面;例如,把一个对象存储到redis中,有3种方法:
1)把用户号设置为key,把对象序列化,使用JSON.toJSONString()方法,用普通的key/value来存储:
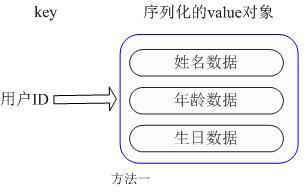
这种方式的缺点是,增加了序列化和反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发保护,引入CAS等复杂问题;
2)把用户号+对象的属性设置为key,存储多对key/value
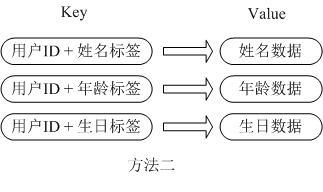
这种方式虽然没有了序列化的开销和并发问题,但是用户号重复的存储,浪费内存空间;
3)用hash能很好的解决这个问题
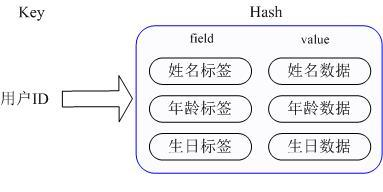
key是用用户的id,value是一个Map,这Map的key是成员的属性名,value是属性值,这样对象的修改和存取都可以直接修该内部map的key,不需要序列化,也不需要关心并发修改问题;