看到一篇很好看的博客,分享给大家:https://www.cnblogs.com/xufengnian/p/10788195.html#_labelTop
博客界面清爽,简洁明了,排版很喜欢。进入正题,XPath语法。博主写的很详细,直接引用吧。
语法:


# 1.选取节点 ''' / 如果是在最前面,代表从根节点选取,否则选择某节点下的某个节点.只查询子一辈的节点 /html 查询到一个结果 /div 查询到0个结果,因为根节点以下只有一个html子节点 /html/body 查询到1个结果 // 查询所有子孙节点 //head/script //div . 选取当前节点 .. 选取当前节点的父节点 @ 选取属性 //div[@id] 选择所有带有id属性的div元素 <div id="sidebar" class="sidebar" data-lg-tj-track-code="index_navigation" data-lg-tj-track-type="1"> ''' # 2.谓语 ''' 谓语是用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。 //body/div[1] body下的第一个div元素 //body/div[last()] body下的最后一个div元素 //body/div[position()<3] body下的位置小于3的元素 //div[@id] div下带id属性的元素 <div id="sidebar" class="sidebar" data-lg-tj-track-code="index_navigation" data-lg-tj-track-type="1"> //input[@id="serverTime"] input下id="serverTime"的元素 模糊匹配 //div[contains(@class,'f1')] div的class属性带有f1的 通配符 * //body/* body下面所有的元素 //div[@*] 只要有用属性的div元素 //div[@id='footer'] //div 带有id='footer'属性的div下的所有div元素 //div[@class='job_bt'] //dd[@class='job-advantage'] 运算符 //div[@class='job_detail'] and @id='job_tent' //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 也可以百度搜索XPath语法 .//a/text() 当前标签下所有a标签的文字内容 //tr[position()>1 and position()<11] 位置大于1小于11 ''' # 需要注意的知识点 ''' 1./和//的区别:/代表子节点,//代表子孙节点,//用的比较多 2.contains有时候某个属性中包含了多个值,那么使用contains函数 //div[contains(@class,'lg')] 3.谓语中的下标是从1开始的,不是从0开始的 '''
演示:
还是以一个小说章节的链接演示吧,格式比较整齐https://www.qianqianxsw.com/0/1/
选取节点部分
1. "/" -- 表示从根节点选取
HTML的结构

html是根节点,有且只有一个,所以result = 1

根节点只有html,不存在div节点,所以找不到,result为空

结构图可以看到html下面有子节点head和子节点body,所以/html/body可以找到一个,因此result = 1。同理/html/head也是有一个的。

2. “//” -- 查询所有子孙节点
HTML结构
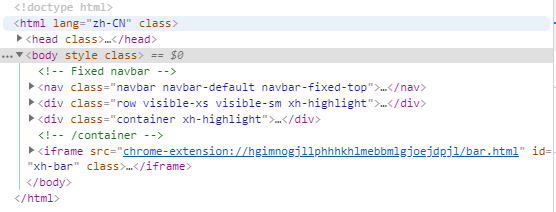
可以看到body节点下有两个div节点,都可以找到,另外,使用/html/body/div也是可以找到的,不过这种是从根节点开始,而//body/div是搜索所有节点,意思是只要是body/div结构的都可以找到。现在这种情况/html/body/div是等价的,但是也会有不同的情况。//body/div是包含/html/body/div的,即/html/body/div是//body/div的子集。

//div搜到了45个结果,这个就很能说明问题了,//body/div就是//div的一个子集,//body/div有个限制条件是body标签下的div节点,而//div是所有的div节点。

3. "." -- 选取当前节点,这个不多讲,和路径里面的"."差不多,当前位置
4. “..” -- 选取父节点,这个也不多讲,和路径里面的".."差不多,上层目录
5. "@" -- 选取属性
之前看到//body/div搜索到了2个div标签,现在加了个限制条件,搜索//body/div节点并且class属性为"container"的节点,如此,满足条件的只剩下一个了。

如果要获取属性的值的话,那么就不加后面的“=”,可以看到已经把两个div标签下的class属性的值提取出来了。

如果要获取带class的属性的div标签下的内容,可以用[@class]

谓语部分
1. "[1]" -- 这种格式的是表示第几个
搜索结果为1,body标签下的第一个div节点,如果是//body/div[2]表示body标签下第二个div节点

2. "[last()]" -- 最后一个元素

3. "[position()>1]"
html结构体

获取全部章节,先找class属性为"row"的div标签,取第三个节点//div[@class="row"][3],在找到li标签下面的a标签,就可以获取所有章节

过滤一部分章节,从第四章开始

双重过滤,取第四章到第六章。

4. 模糊匹配
div属性中带有ro字串的,比如row中就包含ro。

就先演示到这里吧,差不多了。