参考博文:https://blog.csdn.net/qq_41035588/article/details/90514824
首先安装一个Hadoop-Eclipse-Plugin 方便来对于hdfs进行管理
参考地址:http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
配置好Hadoop-Ecllipse-Plugin之后
建立一个txt文档,里面的内容如下:
1 买家id 商品id 收藏日期 2 10181 1000481 2010-04-04 16:54:31 3 20001 1001597 2010-04-07 15:07:52 4 20001 1001560 2010-04-07 15:08:27 5 20042 1001368 2010-04-08 08:20:30 6 20067 1002061 2010-04-08 16:45:33 7 20056 1003289 2010-04-12 10:50:55 8 20056 1003290 2010-04-12 11:57:35 9 20056 1003292 2010-04-12 12:05:29 10 20054 1002420 2010-04-14 15:24:12 11 20055 1001679 2010-04-14 19:46:04 12 20054 1010675 2010-04-14 15:23:53 13 20054 1002429 2010-04-14 17:52:45 14 20076 1002427 2010-04-14 19:35:39 15 20054 1003326 2010-04-20 12:54:44 16 20056 1002420 2010-04-15 11:24:49 17 20064 1002422 2010-04-15 11:35:54 18 20056 1003066 2010-04-15 11:43:01 19 20056 1003055 2010-04-15 11:43:06 20 20056 1010183 2010-04-15 11:45:24 21 20056 1002422 2010-04-15 11:45:49 22 20056 1003100 2010-04-15 11:45:54 23 20056 1003094 2010-04-15 11:45:57 24 20056 1003064 2010-04-15 11:46:04 25 20056 1010178 2010-04-15 16:15:20 26 20076 1003101 2010-04-15 16:37:27 27 20076 1003103 2010-04-15 16:37:05 28 20076 1003100 2010-04-15 16:37:18 29 20076 1003066 2010-04-15 16:37:31 30 20054 1003103 2010-04-15 16:40:14 31 20054 1003100 2010-04-15 16:40:16
然后建立一个java项目
然后把所有的包都导进去,重点是mapreduce,common,yarn,hdfs的包
然后再输入代码:
1 package mapreduce; 2 3 import java.io.IOException; 4 import java.util.StringTokenizer; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 13 14 15 public class WordCount { 16 17 public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{ 18 //第一个object表示输入key的类型,第二个text表示输入value的类型;第三个text表示输出建的类型; 19 //第四个INtWritable表示输出值的类型 20 21 public static final IntWritable one = new IntWritable(1); 22 public static Text word = new Text(); 23 @Override 24 protected void map(Object key, Text value, Context context) 25 //key value是输入的key value context是记录输入的key,value 26 throws IOException, InterruptedException { 27 StringTokenizer tokenizer = new StringTokenizer(value.toString(), " "); 28 //StringTokenizer是Java的工具包中的一个类,用于将字符串进行拆分 29 word.set(tokenizer.nextToken()); 30 //返回当前位置到下一个分隔符之间的字符串 31 context.write(word, one); 32 //讲word存到容器中计一个数 33 } 34 } 35 public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ 36 //输入键类型,输入值类型 输出建类型,输出值类型 37 private IntWritable result = new IntWritable(); 38 @Override 39 protected void reduce(Text key, Iterable<IntWritable> values, Context context) 40 throws IOException, InterruptedException { 41 int sum = 0; 42 for (IntWritable value : values) { 43 sum += value.get(); 44 } 45 result.set(sum); 46 context.write(key, result); 47 } 48 } 49 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 50 Job job = Job.getInstance(); 51 job.setJobName("WordCount"); 52 job.setJarByClass(WordCount.class); 53 job.setMapperClass(doMapper.class); 54 job.setReducerClass(doReducer.class); 55 job.setOutputKeyClass(Text.class); 56 job.setOutputValueClass(IntWritable.class); 57 Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1"); 58 Path out = new Path("hdfs://localhost:9000/mymapreduce1/out"); 59 FileInputFormat.addInputPath(job, in); 60 FileOutputFormat.setOutputPath(job, out); 61 System.exit(job.waitForCompletion(true) ? 0 : 1); 62 } 63 }
然后运行之后查看左边的菜单:
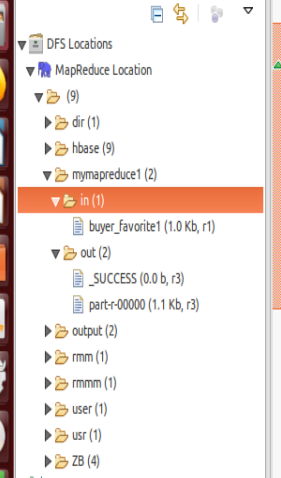
双击part-r-00000就有返回的值了

最重要的问题就是分隔的问题
- StringTokenizer tokenizer = new StringTokenizer(value.toString()," ");
这个是根据tab键来进行分割,但是我们复制粘贴后就是空格所以要换成空格