学了下怎么用wordcloud。
以imet的数据集为例
https://www.kaggle.com/c/imet-2019-fgvc6
读取“train.csv”,”label.csv”文件,得到id2name[] (label的id和label名称对应) 和 attribute_count(label出现次数统计)两个dict。
import matplotlib.pyplot as plt import numpy as np import osimport csv lines=csv.reader(open("train.csv")) train_content = [] head_row =next(lines) for line in lines: train_content.append(line) attribute_ids = [] for line in train_content: attributes = line[1].split() for a in attributes: attribute_ids.append(a) lines=csv.reader(open("labels.csv")) attribute_content = [] head_row =next(lines) for line in lines: attribute_content.append(line) id2name = {} for line in attribute_content: if line[0] not in id2name: id2name.update({line[0]:line[1]})
def count_list(lt): d={} for i in lt: if (i in d.keys()): continue count = lt.count(i) d[i] = count return d attribute_count = count_list(attribute_ids)
对attribute_count进行排序,输出出现次数较多的标签(前十个)
sorted_attribute= sorted(attribute_count.items(),key = lambda item :item[1],reverse = True) for i in range(10): print (sorted_attribute[i][0],': ',id2name[sorted_attribute[i][0]]) print (sorted_attribute[i][1])
结果为

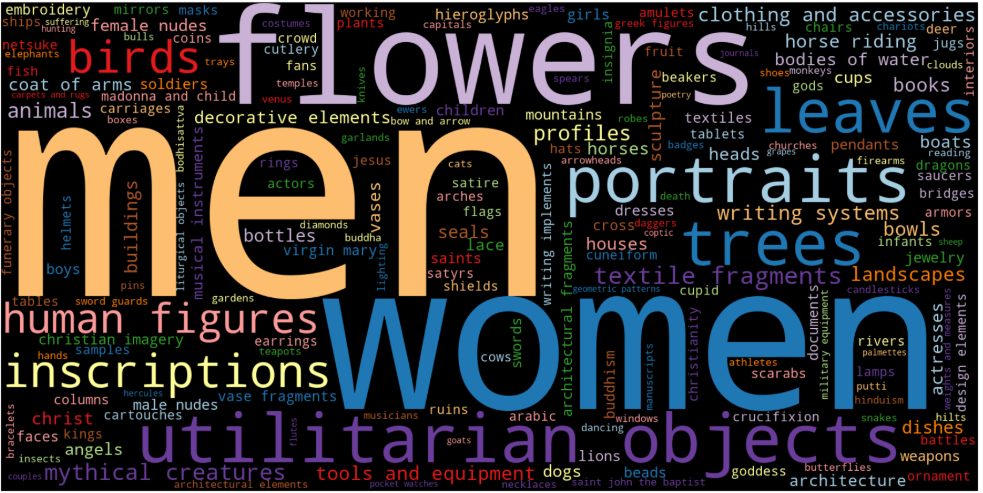
然而这样还不够直观,使用wordcloud可以更直观展示词频。
需要的python库
seaborn、wordcloud
准备好dict
culture_count_dict = {} tag_count_dict = {} for i in range(1103): idx = str(i) if (id2name[idx][0:5] == 'tag::'): tag_count_dict.update({id2name[idx][5:]:attribute_count[idx]}) else: culture_count_dict.update({id2name[idx][9:]:attribute_count[idx]})
wordcloud 生成图像
import seaborn as sns from wordcloud import WordCloud culture_cloud = WordCloud(background_color='Black', colormap='Paired', width=1600, height=800, random_state=123).generate_from_frequencies(culture_count_dict) tag_cloud = WordCloud(background_color='Black', colormap='Paired', width=1600, height=800, random_state=123).generate_from_frequencies(tag_count_dict) plt.figure(figsize=(24,24)) plt.subplot(211) plt.imshow(culture_cloud,interpolation='bilinear') plt.axis('off') plt.subplot(212) plt.imshow(tag_cloud, interpolation='bilinear') plt.axis('off') plt.tight_layout() plt.show()