得到一个模型之后如何评价其性能?
- training error & generalization error & test error
- 如何理解generalization error(泛化误差)分为 noise 噪声、Variance 方差、 bias偏差
- 误差 和 模型复杂度 的关系
- 实际训练模型过程中该如何做
training error & generalization error & test error
(1)training error
模型在训练数据集上的误差。
(2)generalization error

Generalization, 一般化,泛化。
我们用训练数据集(training data)训练一个模型,而我们希望这个模型能实际应用于训练数据集之外的总体
数据,所以这个模型真实误差应该是所有可能的数据的集合上的误差,但这是无法实际计算的,我们能够用来学
习的训练数据集只是全部数据中的一个子集。
课程中的例子是房价估计,我们用已有的数据集训练一个模型用于房价预测,而除了已有的房屋出售数据之
外,还有许多没没统计进这个数据集的数据。我们希望能评估这个模型的真实预测效果,即求得用这个模型对所
有可能的房屋出售的数据集进行房价预测产生的误差,这个误差就是generalization error(泛化误差)。
(3)test error
因为generalization error无法真正计算(得不到所有可能的数据集合),所以可以用training dataset
之外的一个数据子集来近似估计generalization error,这就是test error。

test error是generalization error的近似,故而在算法中应注意Training /test split (训练/测试数据集分割比例),
训练数据太少,则模型预测效果差;测试数据太少,则测试数据集不具有普适性,test error不能较好的近似
generalization error。

Noise & Variance & Bias
(1)Noise

Irreducible: 不可减少的
周志华《机器学习》中是这么解释的:
泛化误差可分解为偏差、方差与噪声之和。
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同
样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了在当前任务上
任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
(2) bias & variance
一张图理解bias 和variance .
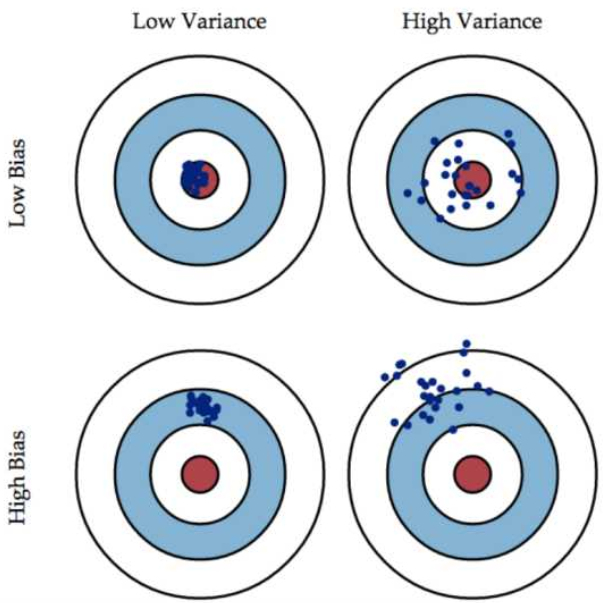
所以一个好的模型应该具有low bias & low variance。现在问题来了,鱼与熊掌可兼得吗?
复杂度较小的情况下:
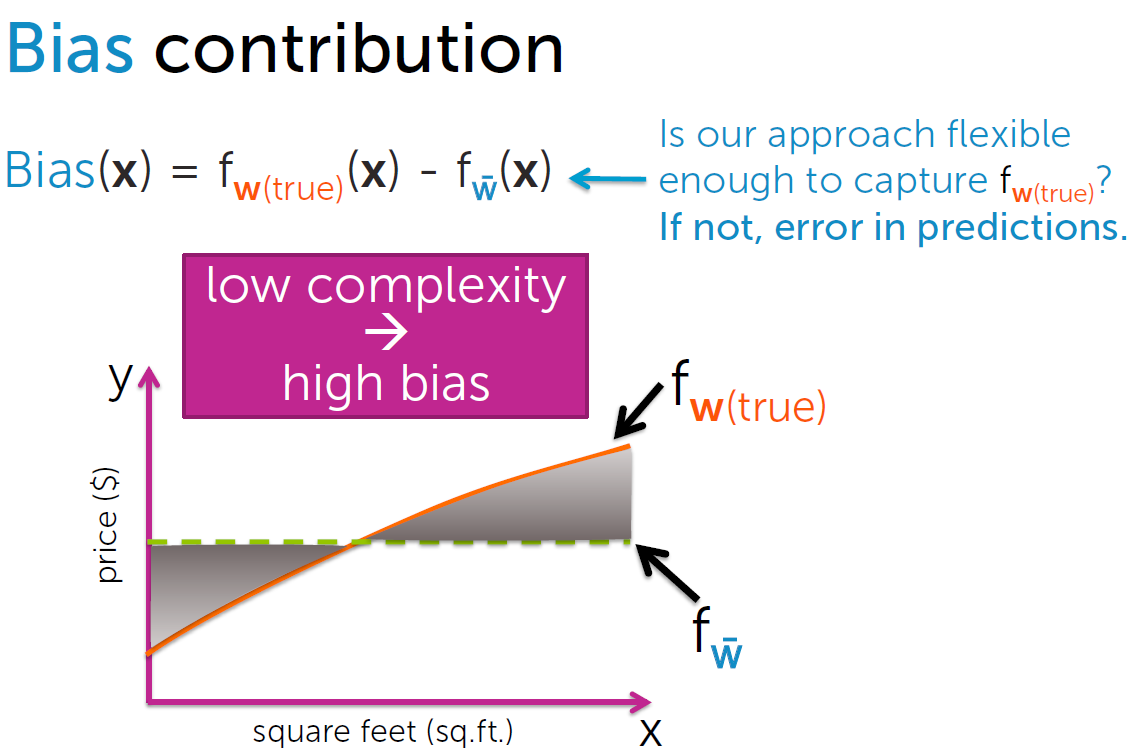
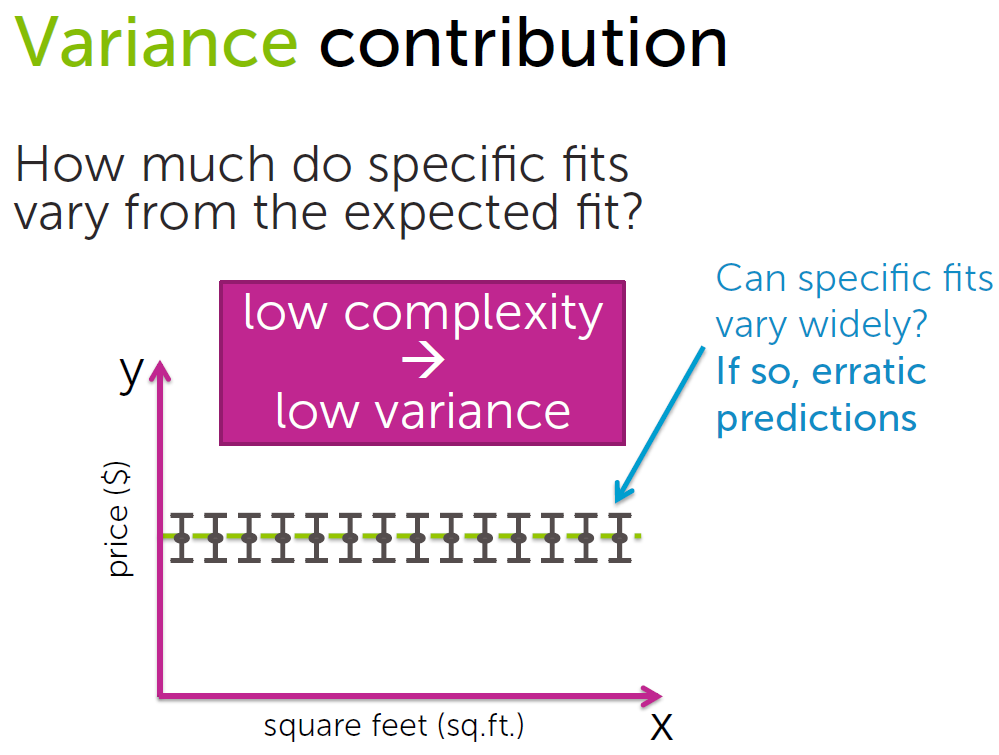
Low complexity –> high bias 、 low variance
利用training set训练模型的过程,就是不断逼近一个理想的”真实模型”的过程,复杂度较小时,模型对训练数
据集的拟合程度较低,模型预测值与真实值偏差较大,bias较大,同时由于拟合程度较低,模型普适性较好,应
用于不同的数据集预测结果之间差异不大,variance较小。
复杂度较大的情况下:

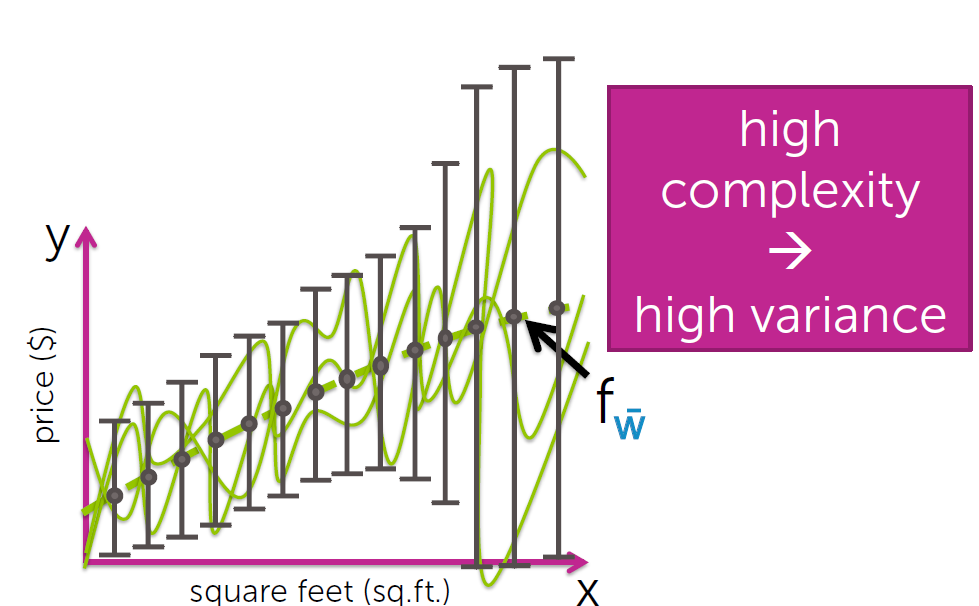
high complexity –> low bias 、 high variance
复杂度较大,模型对训练集拟合程度很高,bias很小,但模型拟合是针对训练集这个特定的数据集进行的,
而训练集只是真实数据的一个子集,得到的模型过于specific,包含了许多具体的,针对于训练集的特征。利用
这个模型对其他不同的数据集进行预测,预测结果会“飘忽不定(erratic)”,variance很大,模型对training set
拟合的很好,而用于预测时效果不佳误差很大,这种现象称为“过拟合”。

训练数据集对于模型拟合十分重要,考虑一个理想的情况,复杂度一定的条件下,假如我们拥有全部
可能的数据,即训练数据集无限大,此时variance就趋近于0(noise噪声为不为0;training error 和 bias要
考虑复杂度对拟合效果的影响),这种情况下就不需要bias-variance tradeoff(但显然这是不现实的)。
errors & complexity
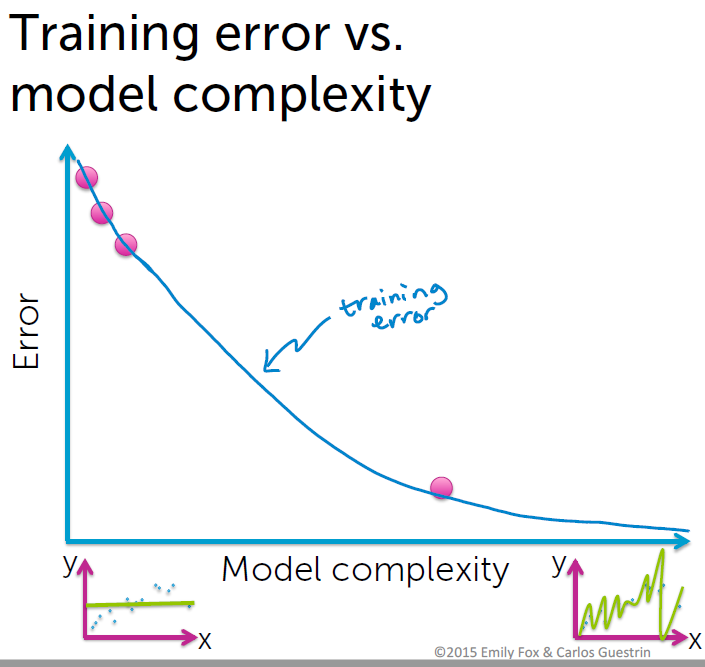

test error 图同generalization error。
Complexity 不是越大越好,要考虑到 bias-variance tradeoff,当complexity过小,欠拟合,complexity
过大,过拟合。
如何选择合适的复杂度
(1)根据 使test error最小 的原则确定复杂度,有什么问题?
如果根据test error最小确定复杂度,则之后评价模型的预测结果会过于乐观。复杂度根据测试数据决定,
这样测试数据就不能很好的代表总体数据了,test error不能较好的近似generalization error, 真实误差会大于
测试误差。
(2)常见可行方法?
再添加一个“test”数据集。
根据使validation error最小,确定复杂度。
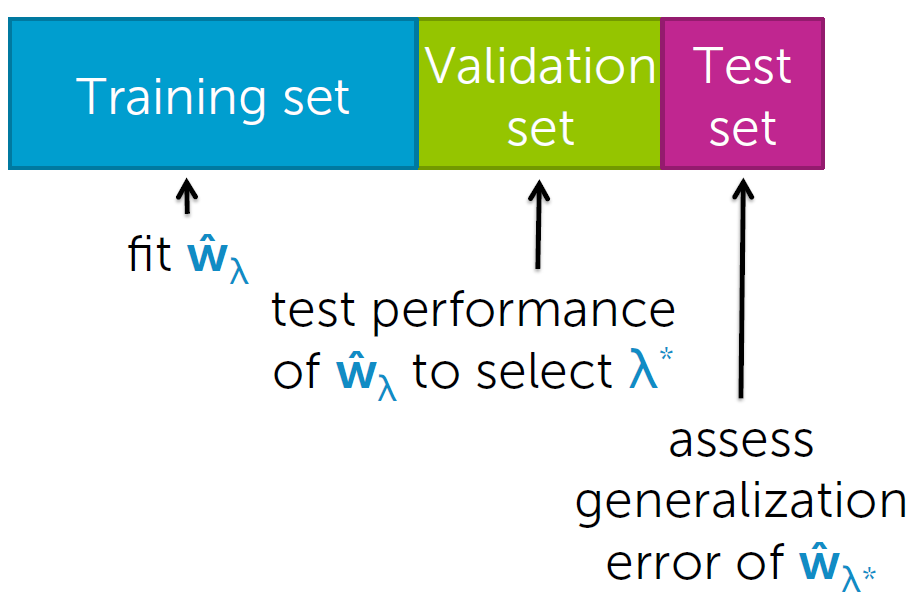
Training set 用于拟合模型,validation set 用于确定复杂度,test set 用于评价模型误差。