华盛顿大学 machine learning regression 第六周笔记。
普通的回归方法是基于training set的整体性进行训练的,如果训练数据集
具有明显的分段性,那么普通的回归方法预测效果可能不佳。
考虑 knn(k邻近法)的解决思路:
给定一个 training set, 对于查询的实例,在training set中找到与这个实例
最邻近的k个实例,然后再根据k个最邻近点做预测。
得到k个邻近点后,如何输出预测结果?
对这k个临近点加权。
查询点q, 得到k个最邻近点后,输出预测结果yq为:

加权值如何得到?
考虑到离查询点q越近,权值越大。一个简单的方法是取权值为距离的倒数。
另一个方法是使用核函数(kernel).
Gaussian Kernel:

取加权为:
![]()
以上是使用 knn方法的思路。如果不特定选出k个最邻近点,而是综合考虑所有的点呢?
Kernel regression:

一个重要问题:带宽 lambda如何选择?
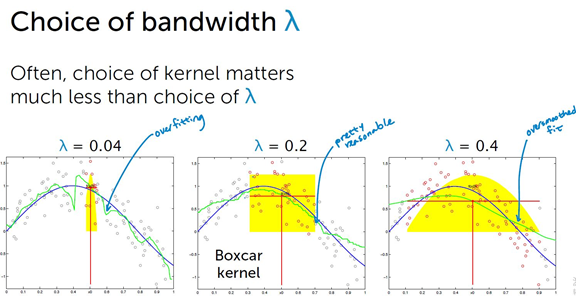
使用 cross validation(交叉验证) 选择 lambda.