华盛顿大学 machine learnign :classification week 3 笔记
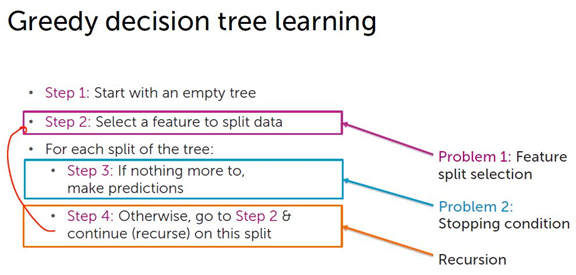
第二步:

注:
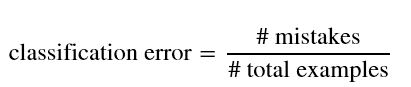
其中 ,mistake 的计算方法:
给定一个节点的数据集M,对每个特征hi(x),根据特征hi(x)将节点的数据集M分类。
统计哪个类别占多数,记为多数类。
所有不在多数类里的数据都作为误判mistakes
classification error = (left_mistakes + right_mistakes) / num_data_points
第三步:建树
考虑到防止过拟合:

1. early stopping:
停止条件:

建树过程:
def decision_tree_create(data, features, target, current_depth = 0,
max_depth = 10, min_node_size=1,
min_error_reduction=0.0):
remaining_features = features[:]
target_values = data[target]
# Stopping condition 1: All nodes are of the same type.
if intermediate_node_num_mistakes(target_values) == 0:
return create_leaf(target_values)
# Stopping condition 2: No more features to split on.
if remaining_features == []:
return create_leaf(target_values)
# Early stopping condition 1: Reached max depth limit.
if current_depth >= max_depth:
return create_leaf(target_values)
# Early stopping condition 2: Reached the minimum node size.
if reached_minimum_node_size(data, min_node_size):
return create_leaf(target_values)
# Find the best splitting feature and split on the best feature.
splitting_feature = best_splitting_feature(data, features, target)
left_split = data[data[splitting_feature] == 0]
right_split = data[data[splitting_feature] == 1]
# calculate error
error_before_split = intermediate_node_num_mistakes(target_values) / float(len(data))
left_mistakes = intermediate_node_num_mistakes(left_split[target])
right_mistakes = intermediate_node_num_mistakes(right_split[target])
error_after_split = (left_mistakes + right_mistakes) / float(len(data))
# Early stopping condition 3: Minimum error reduction
if error_before_split - error_after_split < min_error_reduction:
return create_leaf(target_values)
remaining_features.remove(splitting_feature)
# Repeat (recurse) on left and right subtrees
left_tree = decision_tree_create(left_split, remaining_features, target,
current_depth + 1, max_depth, min_node_size, min_error_reduction)
right_tree = decision_tree_create(right_split, remaining_features, target,
current_depth + 1, max_depth, min_node_size, min_error_reduction)
return create_node(splitting_feature, left_tree, right_tree)
2. pruning
Total cost C(T) = Error(T) + λ L(T)

用建好的树预测数据:

def classify(tree, input): # if the node is a leaf node. if tree['is_leaf']: return tree['prediction'] else: # split on feature. split_feature_value = input[tree['splitting_feature']] if split_feature_value == 0: return classify(tree['left'], input) else: return classify(tree['right'], input)