我们在做渗透的时候肯定会用上扫描器的,本人一般会用御剑,当然你也会喜欢别的工具。
很多时候,能否渗透成功其实还挺依赖与字典的,如果把后台给扫出来了,恰好还弱口令,那么岂不是美滋滋。
因此,有一个好的字典是至关重要的。当然了,大佬们渗透多年肯定已经收藏了很多好用的字典了,但是吧,很多时候一个asp的字典里还有aspx啊,php啊,jsp啊等等不相关的东西,
如果不相关的东西多了就会降低扫描的效率了,因此我们需要一个用来整理的工具,可以让我们肆无忌惮的到处收集字典,然后整合到自己的字典库中
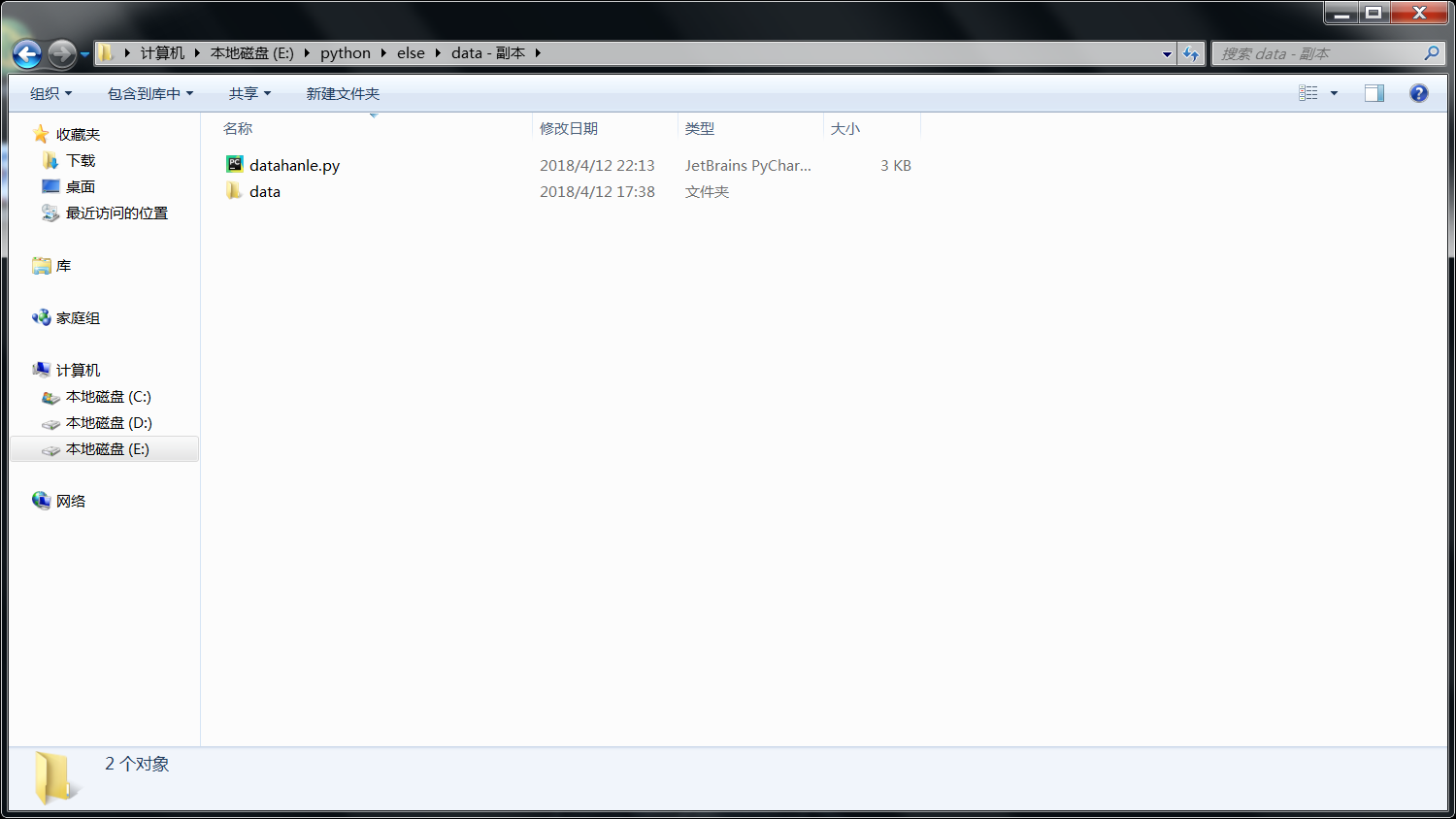
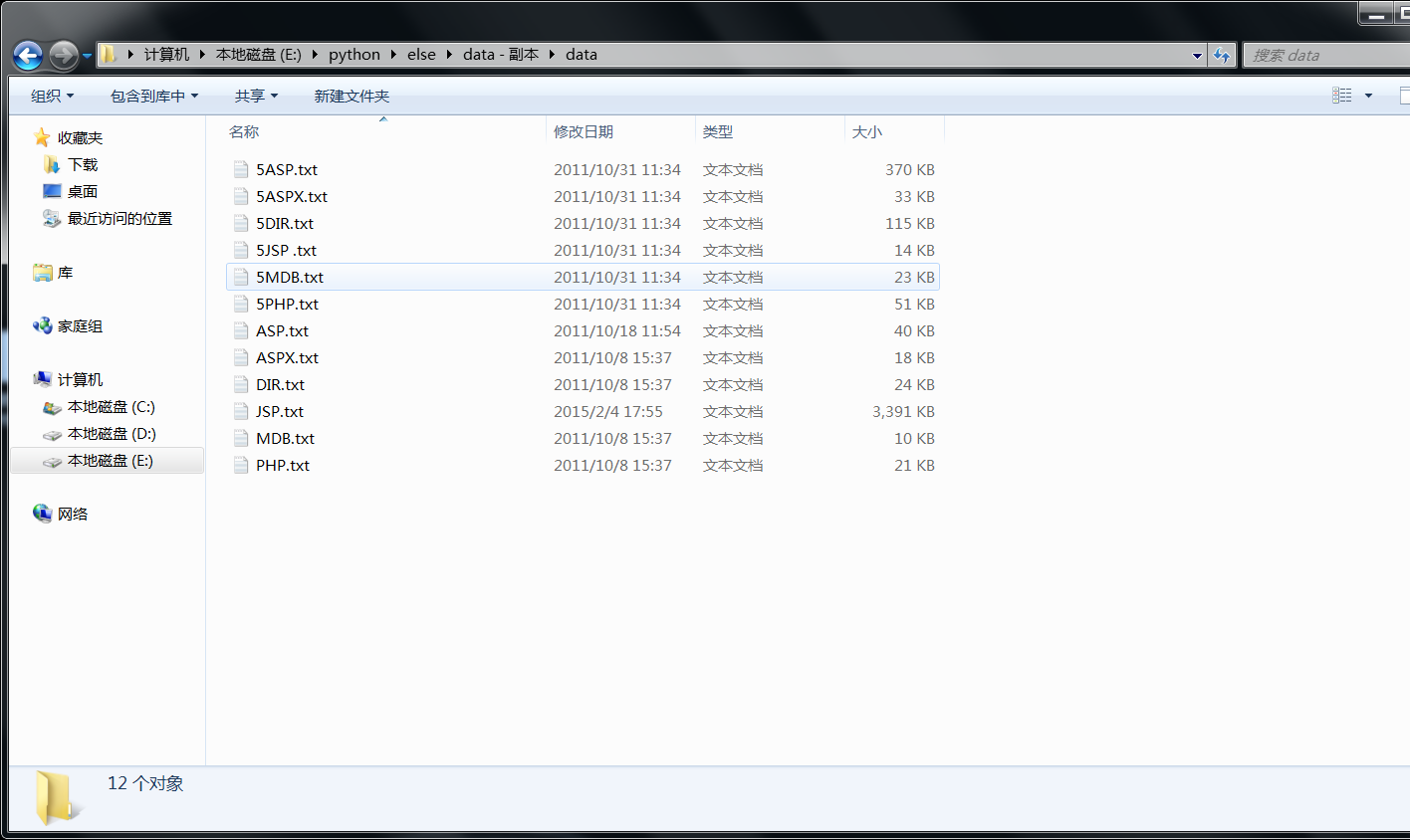

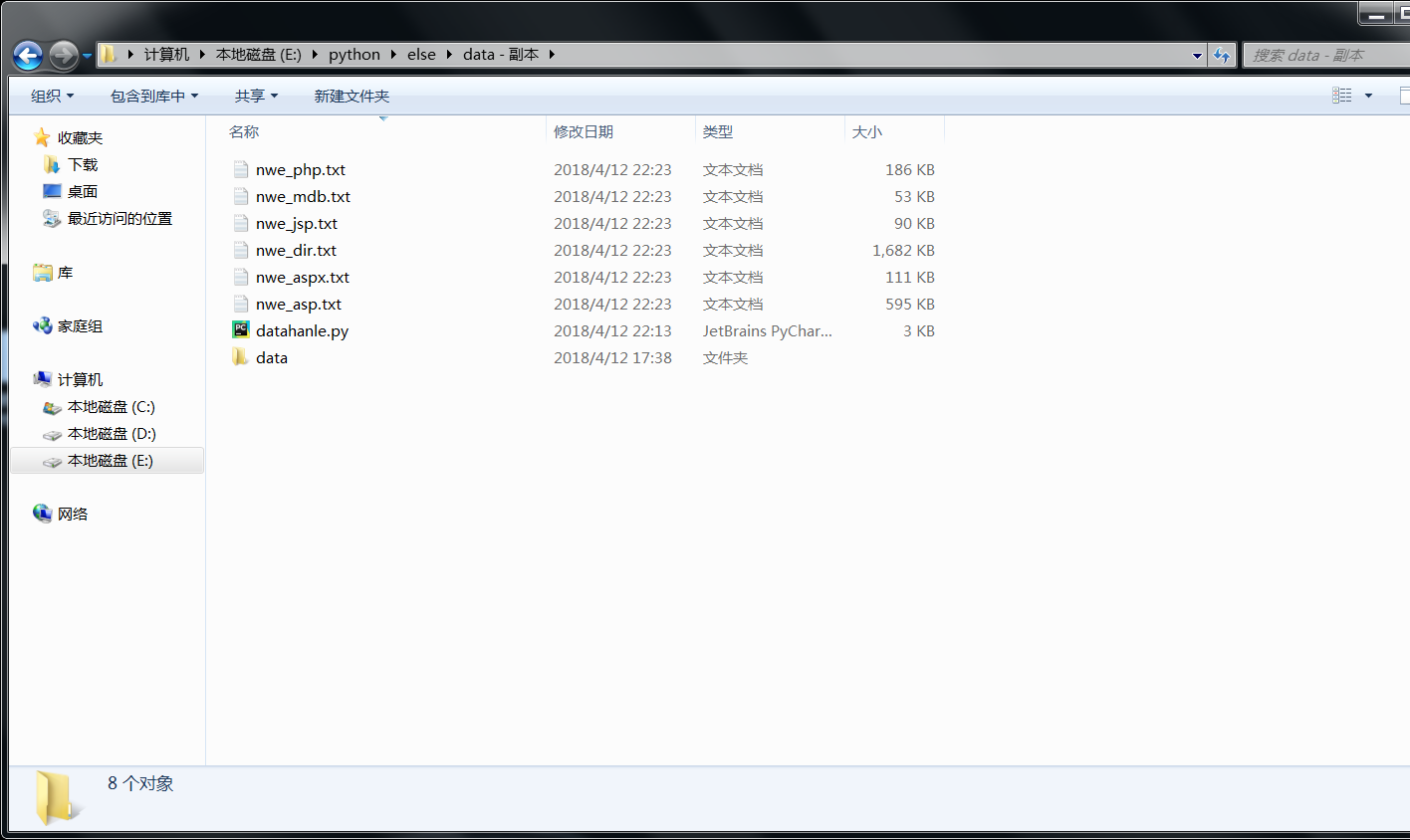
创建个data目录 把需要去重和分类的txt文件放到里面
请用python3.X执行
用法如下
python datahanle.py
#!/usr/bin/env python # -*- conding:utf-8 -*- import os,re data =[] asp = [] aspx = [] php = [] jsp = [] mdb = [] dirx = [] def file_name(): for files in os.walk("data"): #print(files[2]) #当前路径下文件 pass return files[2] def datas(dir): with open("%s"%dir,"r",encoding="gb18030") as f: for i in f.readlines(): data.append(i) dirs =file_name() for i in dirs: datas("data/%s"%(i)) print("一共有%s条路径"%(len(data))) data = list(set(data)) print("去重后一共还有%s条路径"%(len(data))) count_asp = 0 count_aspx = 0 count_jsp = 0 count_php = 0 count_dirx = 0 count_mdb = 0 data = sorted(data) #对列表排序 for i in data: #rule = re.compile(r".*?asp",re.I) res = re.search('.*?.asp',i,flags=re.I) if res == None: res = re.search('.*?.mdb', i, flags=re.I) if res == None: res = re.search('.*?.php', i, flags=re.I) if res == None: res = re.search('.*?.jsp', i, flags=re.I) if res == None: dirx.append(i) count_dirx +=1 else: jsp.append(i) count_jsp +=1 else: php.append(i) count_php +=1 else: mdb.append(i) count_mdb += 1 else: res = re.search('.*?.aspx', i, flags=re.I) if res == None: asp.append(i) count_asp+=1 else: aspx.append(i) count_aspx +=1 print("asp:%s aspx:%s php:%s jsp:%s dir:%s mdb:%s"%(count_asp,count_aspx,count_php,count_jsp,count_dirx,count_mdb)) with open('nwe_asp.txt','a',encoding='utf-8') as f: for i in asp: f.write(i) with open('nwe_aspx.txt','a',encoding='utf-8') as f: for i in aspx: f.write(i) with open('nwe_php.txt','a',encoding='utf-8') as f: for i in php: f.write(i) with open('nwe_jsp.txt','a',encoding='utf-8') as f: for i in jsp: f.write(i) with open('nwe_mdb.txt','a',encoding='utf-8') as f: for i in mdb: f.write(i) with open('nwe_dir.txt','a',encoding='utf-8') as f: for i in dirx: f.write(i)