序列化的发展:
随着分布式架构、微服务架构的普及。服务与服务之间的通信成了最基本的需求。这个时候,我们不仅需要考虑通信的性能,也需要考虑到语言多元化问题。所以,对于序列化来说,如何去提升序列化性能以及解决跨语言问题,就成了重点解决的问题。
java本身提供的序列化存在两个问题:
1.序列化的数据比较大,传输效率低
2.其他语言无法识别和对接
以至于在后来的很长一段时间,基于XML格式编码的对象序列化机制成为主流,一方面解决了多语言兼容问题,另一方面比二进制更容易理解。以至于基于XML的SOAP协议及对应的WebService框架在很长一段时间内成为各个主流开发语言的必备的技术。
再后来,基于Json的简单文本格式编码的HTTP REST接口又基本上取代了复杂的WebService接口,成为分布式架构中远程通信的首要选择。但是Json序列化存储占用的空间大、性能低等问题,同时移动客户端应用需要更高效的传输数据来提升用户体验。
在这种情况下与语言无关并且高效的二进制编码协议就成为追求的热点技术之一。最先诞生的是开源二进制序列化框架--MessagePack。它比Protocol Buffers出现的还要早。
各种序列化技术
XML序列化框架介绍
XML序列化的好处在于可读性,方便阅读和调试。但是序列化以后的字节码文件比较大,而且效率不高,适用于对性能不高,而且QPS较低的企业级内部系统之间的数据交换的场景,同时XML又具有语言无关系,所以还可以用于异构系统之间的数据交换和协议。比如
WebService,就是采用XML格式对于数据进行序列化的。XML序列化/反序列化的实现方式有很多种,熟知的方式有XStream和java自带的序列化和反序列化两种。
JSON序列化框架
JSON是一种轻量级的数据交换格式,相对于XML来说,JSON的字节流更小,而且可读性也非常好。现在JSON数据格式在企业运用是最普遍的。
JSON序列化常用的开源工具:
-
Jackson(https://github.com/FasterXML/jackson)
-
阿里开源的FastJson(https://github.com/alibaba/fastjson)
-
Google的GSON(https://github.com/google/gson)
这几种json序列化工具中,Jackson与fastjson要比GSON的性能要好,但是Jackson、Gson的稳定性要比Fastjson好。而fastjson的优势在于提供的api简单易用。
Hessian序列化框架
Hessian是一个支持跨语言传输的二进制序列化协议,相对于java默认的序列化机制来说,Hessian具有更好地性能和易用性,而且支持多种不同的语言,实际上Dubbo采用的就是Hessian的序列化来实现的,只不过Dubbo对Hessian进行了重构,性能更高。
Avro序列化
Avro是一个数据序列系统,设计用于大批量数据交换的应用。由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)开发。特点:二进制序列化方式,可以便捷,快速的处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便的处理Avro数据。
- 定义Person.avsc文件
{
"namespace": "com.example.serialexample",
"type":"record",
"name":"Person",
"fields": [
{"name":"name","type":"string"},
{"name":"age","type":"int"}
]
}
- maven
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.8.2</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.2</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
maven install执行 就可以生成Person.java
Kryo序列化框架
链接:https://github.com/EsotericSoftware/kryo/blob/master/README.md
Kryo是一种非常成熟的序列化实现,已经在Hive、Storm)中使用的比较广泛,不过他不能跨语言。目前dubbo已经在2.6版本支持Kryo的序列化机制。它的性能要优于之前的Hessian2
Protobuf序列化框架
Protobuf是Google的一种数据交换格式,他独立于语言、独立于平台。Google提供了多种语言来实现,比如Java、C、Go、Python,每一种实现都包含了相应语言的编译器和库文件。
Protobuf是一个纯粹的表示层协议,可以和各种传输层协议一起使用。
protobuf使用比较广泛,主要是空间开销小和性能比较好,非常适合用于公司内部对性能要求高的RPC调用。
另外由于解析性能比较高,序列化以后数据量相对较少,所以也可以应用在独享的持久化场景中。
但是要使用Protobuf会相对来说麻烦一些,因为他有自己的语法,有自己的编译器,如果需要用到的话必须要去投入成本在这个技术的学习中。
Protobuf有个缺点就是传输的每一个类的结构都要生成相对应的proto文件,如果某个类发生修改,还要重新生成该类对应的proto文件。
Protobuf序列化的原理
protobuf的基本应用
使用protobuf开发的一般步骤:
1.配置开发环境,安装protocol compiler代码编译器
2.编写.proto文件,定义序列化对象的数据结构
3.基于编写的.proto文件,使用protocol compiler编译器生成对应的序列化/反序列化工具类。
4.基于自动生成的代码,编写自己的序列化应用
Protobuf案例演示
下载protobuf工具 地址:https://github.com/google/protobuf/releases
这里提供mac的安装方式:https://www.jianshu.com/p/67f64307d268
编写proto文件:
syntax="proto2";
package com.demo.serial;
option java_package = "com.demo.serial";
option java_outer_classname = "UserProtos";
message User{
required string name = 1;
required int32 age = 2; //这里是正数
// required sint32 age = 2; //这里是负数
}
数据类型:
string/bytes/bool/int32(4个字节)/int64/float/double/enum/message自定义类
修饰符
required 表示必填字段
optional 表示可选字段
repeated 可重复,表示集合
1,2,3,4需要在当前范围内是唯一的,表示顺序
生成实体类
【protoc --java_out=./ user.proto】
实现序列化
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.13.0</version>
</dependency>
protobuf序列化原理
我们可以把序列化以后的数据打印出来
public class TestProto {
public static void main(String[] args) {
UserProtos.User user = UserProtos.User.newBuilder().setAge(300).setName("zhangsan").build();
byte[] bytes = user.toByteArray();
for (byte bt : bytes) {
System.out.print(bt + " ");
}
}
}
//10 8 122 104 97 110 103 115 97 110 16 -84 2
这里可以看到,序列化出来的数字基本不理解,但是序列化以后的数据确实很小。
正常来说,要达到最小的序列化结果,一定会用到压缩的技术,而protobug里面用到了两种压缩算法,一种是varint,另一种是zigzag。
varint
第一种,我们现来看age=300这个数字是如何被压缩的
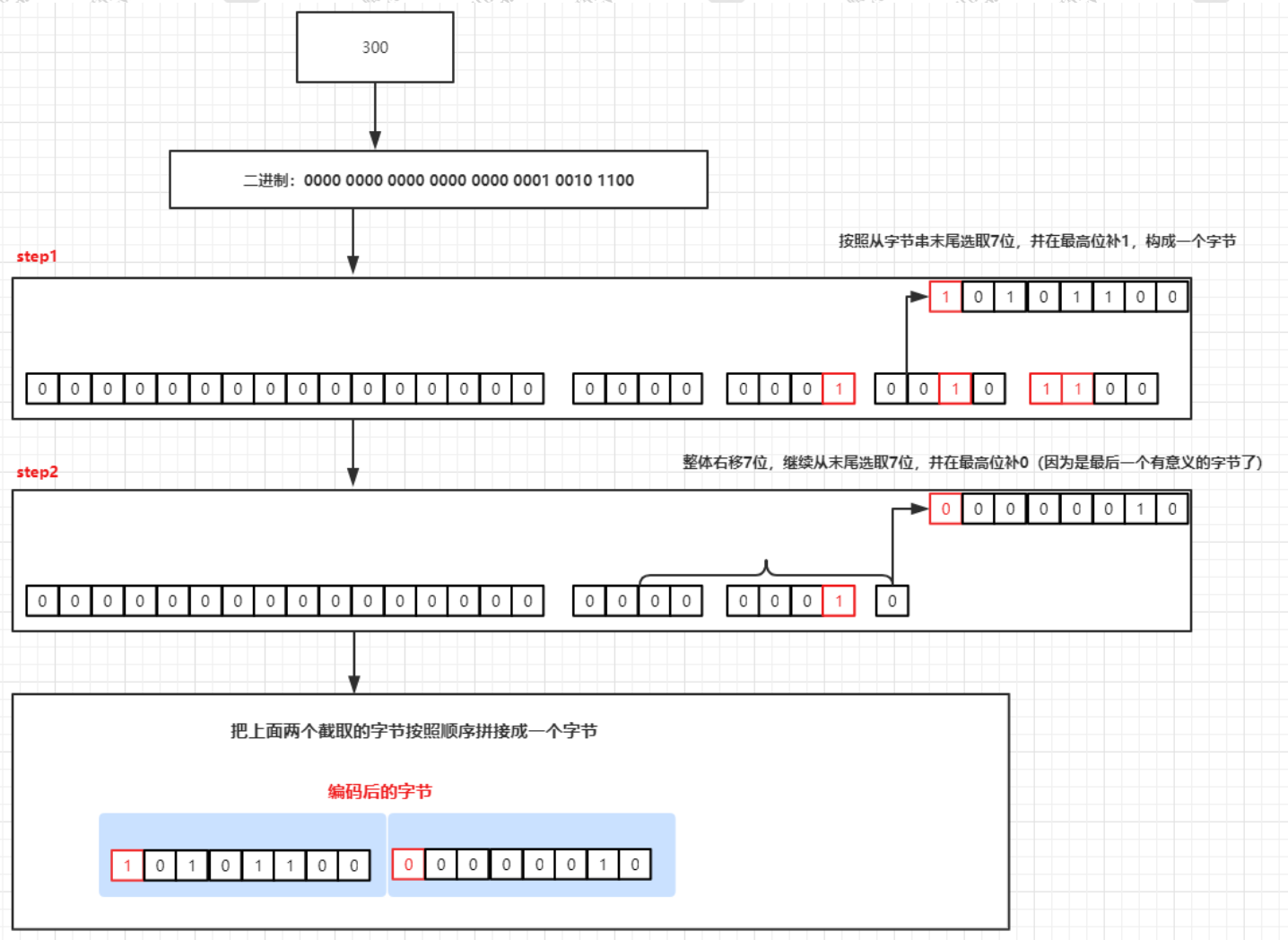
这两个字节分别的结果是:-84 、2
-84是如何计算出来的呢?我们知道在二进制中表示负数的方法,高位设置为1,并且是对应数字的二进制取反以后在再补码表示(补码是反码+1)
所以如果要反过来计算:
1.【补码】10101100 -1 得到10101011
2.【反码】01010100得到的结果为84.由于高位是1,表示负数所以结果为-84
字符转化位编码
“zhangsan”这个字符,需要根据ASCII对照表转化为数字
z = 122、 h = 104 、 a=97 、n = 110 、 g = 103 、 s = 115 、 a = 97 、 n= 110
所以结果为122 104 97 110 103 115 97 110
为什么这里的记过对应ASCII的值呢?为什么没有压缩呢?
varint是对字节码做压缩,但是如果这个数字的二进制只需要一个字节表示的时候,其实最终编码出来的结果是不会变化的。
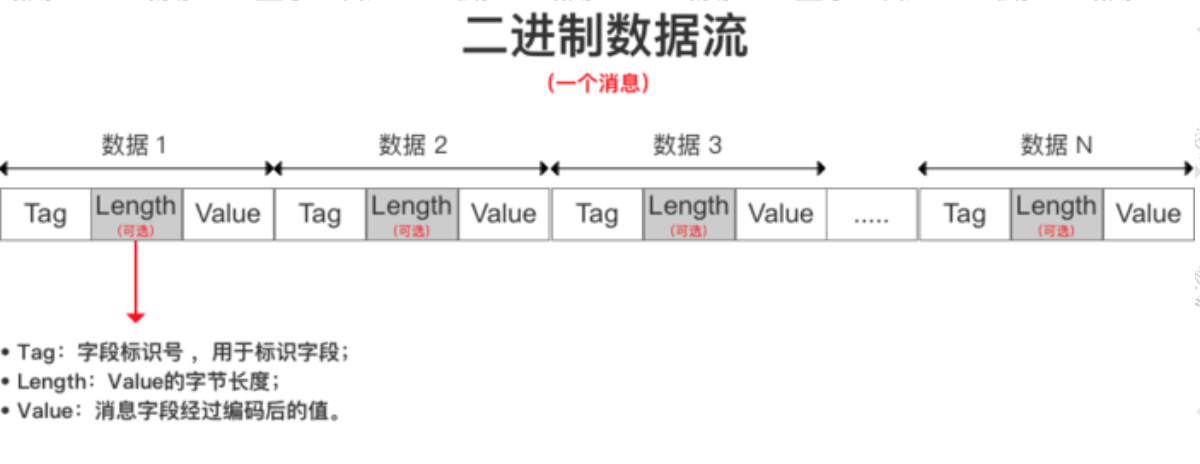
还有两个数字,8和16代表什么呢?这里需要了解protobuf的存储格式了
存储格式
数据类型
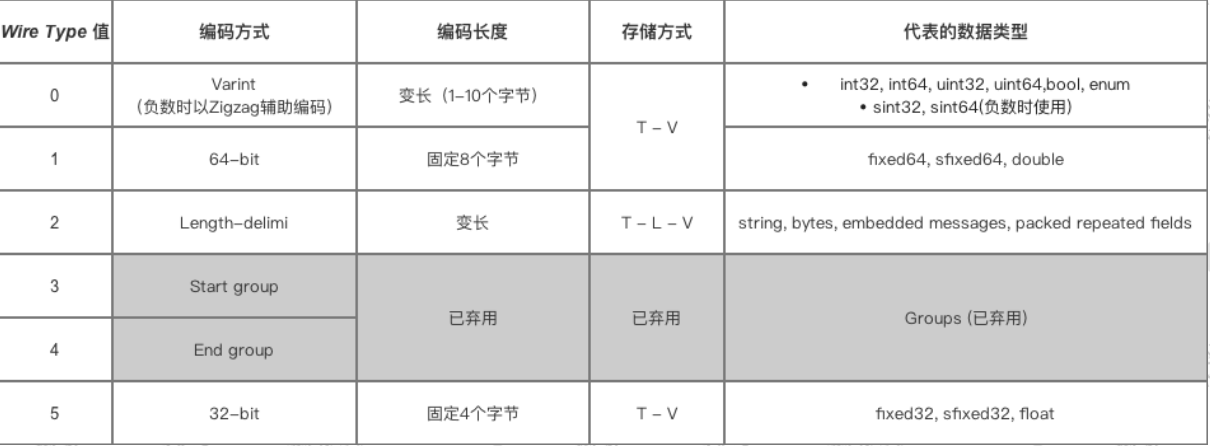
field_number(当前字段的编号) <<3 |write_type
比如zhangsan的字段编号为1,类型write_type的值为2 所以 1<<3 |2 =10
zhangsan的长度是8
age=300的字段编号为2,类型write_type的值为0 所以 2 << 3 |0 = 16
int类型的长度 这里可以省略不写
第一个数字10,代表的是key,剩下的都是value。
负数的存储
在计算机中,负数会被表示为很大的整数,因为计算机定义负数符号位为数字的最高位,所以如果采用varint编码表示一个负数,那么一定需要5个比特位。所以在protobuf中通过sint32/sint64类型来表示负数,
负数的处理形式是采用zigzag编码(吧符号数转化为无符号数),在采用varint编码。
sint32:(n<<1)^(n>>31)
sint64:(n<<1)^(n>>63)
比如存储一个(-300)的值
-300
源码:0001 0010 1100
取反:1110 1101 0011
加1: 1110 1101 0100
n<<1:整体左移一位,右边补0 -> 1101 1010 1000
n>>31:整体右移31位,左边补1 -> 1111 1111 1111
n<<1 ^ n>>31
1101 1010 1000 ^ 1111 1111 1111 = 0010 0101 0111
十进制: 0010 0101 0111 = 599
varint算法:从右往左,选取7位,高位补1/0(取决于字节数)
得到两个字节
1101 01111 0000 0100
-41 4
总结
Protocol buffer的性能好,主要体现在序列化后的数据体积小 & 序列化速度快,最终使得传输效率高,原因如下:
1.编码 / 解码 方式简单 (只需要简单的数学运算 = 位移)
2.采用proto buffer自身的框架代码和编译器共同完成
序列化的数据量体积小(即数据压缩效果好)的原因:
1.采用了独特的编码方式,如varint、zigzag编码方式。
2.采用T-L-V的数据存储方式:减少了分割符的使用 & 数据存储的紧凑
序列化的选型
1.序列化空间开销,也就是序列化产生的结果大小,这个影响到传输的性能;
2.序列化过程中消耗的时长,序列化消耗的时间过长影响到业务的响应时间;
3.序列化协议是否支持跨平台、快语言。因为现在的架构更加灵活,如果存在异构系统通信需求,那么这个是必须要考虑的;
4.可扩展性/兼容性,在实际业务中,系统往往需要随着需求的快速迭代来实现快速更新,这就要求我们采用的序列化协议基于良好的可扩展性/兼容性,比如在现在的序列化数据结构中新增一个业务字段,不会影响到现有的服务。
5.技术的流行程度,越流行的技术意味着使用的公司多,那么相应的技术解决方案也相对成熟
6.学习的难度和易用性
选型建议
对于性能不高的场景,可以采用基于XML的SOAP协议
2.对于性能和间接性有比较高要求的场景,那么Hessian、Protobuf、Thrift、Avro都可以。
3.基于前后端分离,或者独立的对外api服务,选用JSON是比较好的,对于调试、可读性都很不错
4.Avro设计理念偏于动态类型语言,那么这类的场景使用Avro是可以的。
各个序列化技术的性能比较
针对不同序列化技术进行性能比较 : https://github.com/eishay/jvm-serializers/wiki