使用DTD的原因:
注意:由于它自身的一些缺点,DTD终将被淘汰,但是它还是要学习的。学习完DTD后,后面继续学习XML Schema。
1,通过 DTD,您的每一个 XML 文件均可携带一个有关其自身格式的描述。
2,通过 DTD,独立的团体可一致地使用某个标准的 DTD 来交换数据。
3,您的应用程序也可使用某个标准的 DTD 来验证从外部接收到的数据。
您还可以使用 DTD 来验证您自身的数据。
XML文件
<?xml version="1.0" encoding="utf-8"?>
<!--导入外部dtd文件-->
<!DOCTYPE Students SYSTEM "Students.dtd">
<Students>
<Student num="z001">
<name>小明</name>
<sex>男</sex>
<age>20</age>
<subject><![CDATA[数学&英语]]></subject>
<sport>篮球</sport>
</Student>
<Student num="z002">
<name>小红</name>
<sex>女</sex>
<age>21</age>
<subject><![CDATA[数学&英语]]></subject>
<sport>篮球</sport>
</Student>
<Student num="z003">
<name>小蓝</name>
<sex>男</sex>
<age>23</age>
<subject><![CDATA[数学&英语]]></subject>
<sport>篮球</sport>
</Student>
</Students>DTD文件:
DTD注释格式:<![ IGNORE [ 注释的内容 ]]>
<![ IGNORE [定义Student子元素必须在 Studens父 元素内出现至少一次。]]>
<!ELEMENT Students (Student+)>
<![ IGNORE [ 设置Student元素中必须有name,age,subject,sport元素并且他们的出现顺序也必须是这样的]]>
<!ELEMENT Student (name,sex,age,subject,sport)>
<![ IGNORE [ 设置num属性为必需且唯一的但是属性的值不能是以数字开头]]>
<!ATTLIST Student
num ID #REQUIRED
>
<![ IGNORE [ !ELEMENT name 定义 name 元素为 "#PCDATA" 类型
!ELEMENT sex 定义 sex元素为 "#PCDATA" 类型,下同
]]>
<!ELEMENT name (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT subject (#PCDATA)>
<!ELEMENT sport (#PCDATA)>
测试的html文件:
<html>
<head>
<!--自己编写一个简单的解析工具,去解析XML DTD是否配套-->
<script language="javascript">
// 创建xml文档解析器对象
var xmldoc = new ActiveXObject("Microsoft.XMLDOM");
// 开启xml校验
xmldoc.validateOnParse = "true";
// 装载xml文档,即指定校验哪个XML文件
xmldoc.load("Students.xml");
document.writeln("错误信息:"+xmldoc.parseError.reason+"<br>");
document.writeln("错误行号:"+xmldoc.parseError.line);
</script>
</head>
<body>
</body>
</html>先来用IE测试一下(必须用ie而且需要把IE浏览器的编码格式改为UTF-8其他浏览器兼容模式也OK)

大家可以看到我们的XML文件完全符合DTD的要求,下面我们来修改一下我们的XML文件
(1)将第6行的num属性删去的再刷新网页得到的结果是:
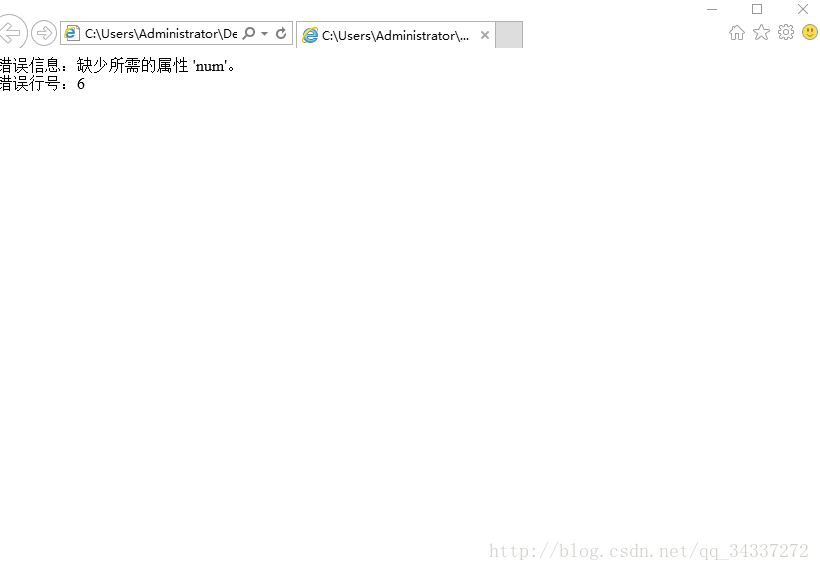
(2)删除第11行的sport元素

(3)将num=”z001”的学生的sex元素和name元素调换位置
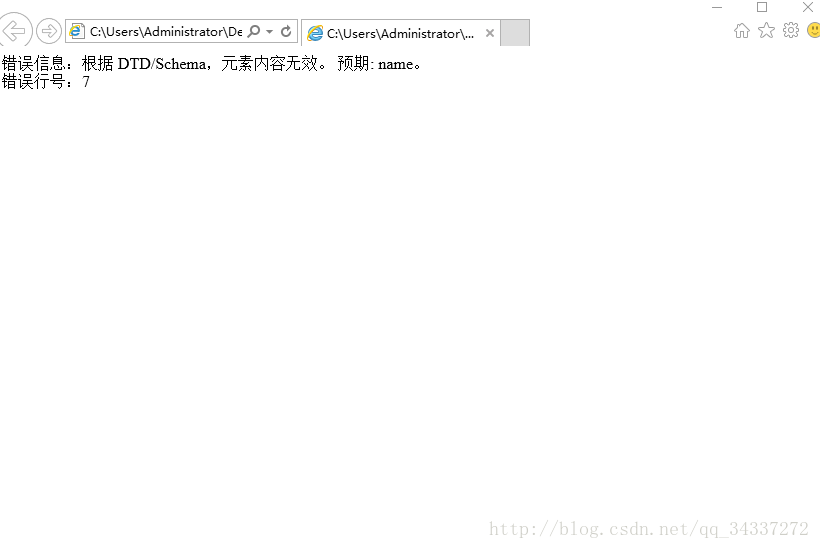
这是我们作业的一小部分后面还要用C++解析(java解析的已经完成,博客里也有)。之前就看过DTD但是只是草草的过了一下,今天重新学了一下。希望大家通过这个例子可以快速掌握DTD,当然我的并不全面。大家可以去 DTD 教程 http://www.w3school.com.cn/dtd/index.asp 详细了解。