前一篇总结了下生产者Java API,本篇参照源码总结下生产数据的具体流程,先上图:
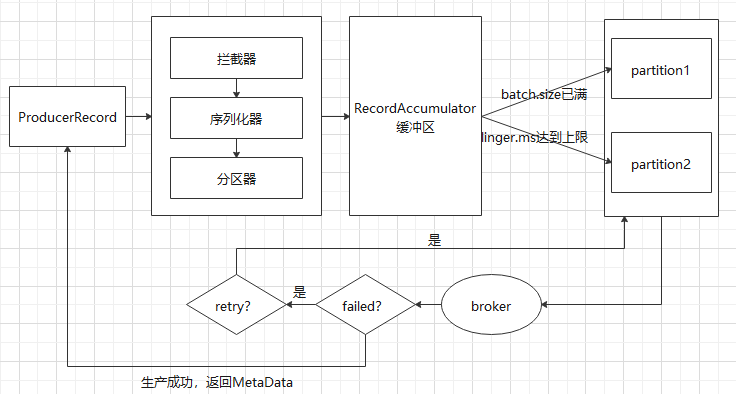
1. Producer创建时,会创建一个Sender线程并设置为守护线程
2. 生产消息时,内部其实是异步流程;生产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建)
3. 这里提下分区器:分区器在2.4.0版本做了优化,尽量保证粘性,也就是每个批次的尽量发往一个分区;批次发送后,新的批次按照轮询策略发往其他分区
4. 批次发送的条件为:缓冲区数据大小达到batch.size或者linger.ms达到上限
5. 批次发送后,发往指定分区,然后落盘到broker;如果生产者配置了retrires参数大于0并且失败原因允许重试,那么客户端内部会对该消息进行重试
6. 落盘到broker成功,返回生产元数据给生产者
7. 元数据返回有两种方式:一种是通过阻塞直接返回,另一种是通过回调返回