InnoDB主要使用行级锁(row lock),其行锁是通过在索引项上加锁而实现的,如果MySQL的执行计划没有用到索引,那么行锁也就无意义了
InnoDB的行锁是通过给索引上的索引(聚集,非聚集)添加锁来实现的,
只有通过索引条件进行数据索引, InnoDB才使用行级别锁, 否则的话会使用表锁(锁住所有记录).
聚集索引: 主索引文件与数据文件是同一个文件[索引顺序与屋里存储顺序是一致的], 数据全部存储在叶子节点,
非聚集索引: 节点存储的是主键(InnoDB) ,然后通过主键再查找数据, 所以又称作二级索引.
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址.
锁模式:
S锁: 允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
X锁: 允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
意向锁:表示事务准备给数据行加入共享锁, (数据库需要对细粒度的对象上锁,需要首先给粗粒度的对象上锁)。在粗粒度对象上上的锁成为意向锁(表锁, 这样数据库就不需要每条数据去验证是否要加锁了)。innodb的意向锁包括共享意向表锁和排他意向表锁。
IS锁: 对记录加S锁之前必须先获取表的IS锁
IX锁: 事务对记录加X锁之前必须先获取表的IX锁
四种锁的兼容矩阵如下:
|
请求模式 当前模式 |
X |
IX |
S |
IS |
|
X |
冲突 |
冲突 |
冲突 |
冲突 |
|
IX |
冲突 |
兼容 |
冲突 |
兼容 |
|
S |
冲突 |
冲突 |
兼容 |
兼容 |
|
IS |
冲突 |
兼容 |
兼容 |
兼容 |
意向锁就是表级锁,会跟表锁之间有冲突。
行锁包括:
- 间隙锁(Gap Lock),只锁间隙。表现为锁住一个区间(注意这里的区间都是开区间,也就是不包括边界值)。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况.
- 记录锁(Record Lock),只锁记录。表现为仅仅锁着单独的一行记录。
- Next-Key锁(源码中称为Ordinary Lock),同时锁住记录和间隙。从实现的角度为record lock+gap lock,而且两种锁有可能只成功一个,所以next-key是半开半闭区间,且是下界开,上界闭。一张表中的next-key锁包括:(负无穷大,最小的第一条记录],(记录之间],(最大的一条记录,正无穷大)。[对于行的查询,都是采用该方法,主要目的是解决幻读的问题]
- 插入意图锁(Insert Intention Lock),插入操作时使用的锁。在代码中,插入意图锁实际上是Gap锁上加了一个LOCK_INSERT_INTENTION的标记。也就是说insert语句会对插入的行加一个X记录锁,但是在插入这个行的过程之前,会设置一个Insert intention的Gap锁,叫做Insert intention锁。
备注:
临键锁:主要是解决幻读的问题, 是InnoDB的默认行锁.
为什么是使用左开右闭? 因为索引是B+树, 使用右闭合,是因为新加的数据一般都是存在右边节点上.......
意向锁: IX,IS是表锁,更多的时候可以认为是一个标记(数据库加锁之前的标示).....
MVCC (Multiversion concurrent control 多版本并发控制):
当读取数据时如果碰到对象已经上了X锁就直接读取镜像数据。又因为事务隔离级别的不同,在不同事务隔离级别下读取的镜像也会不同。
Undo Log :
undo意为取消,以撤销操作为目的,返回指定某个状态的操作
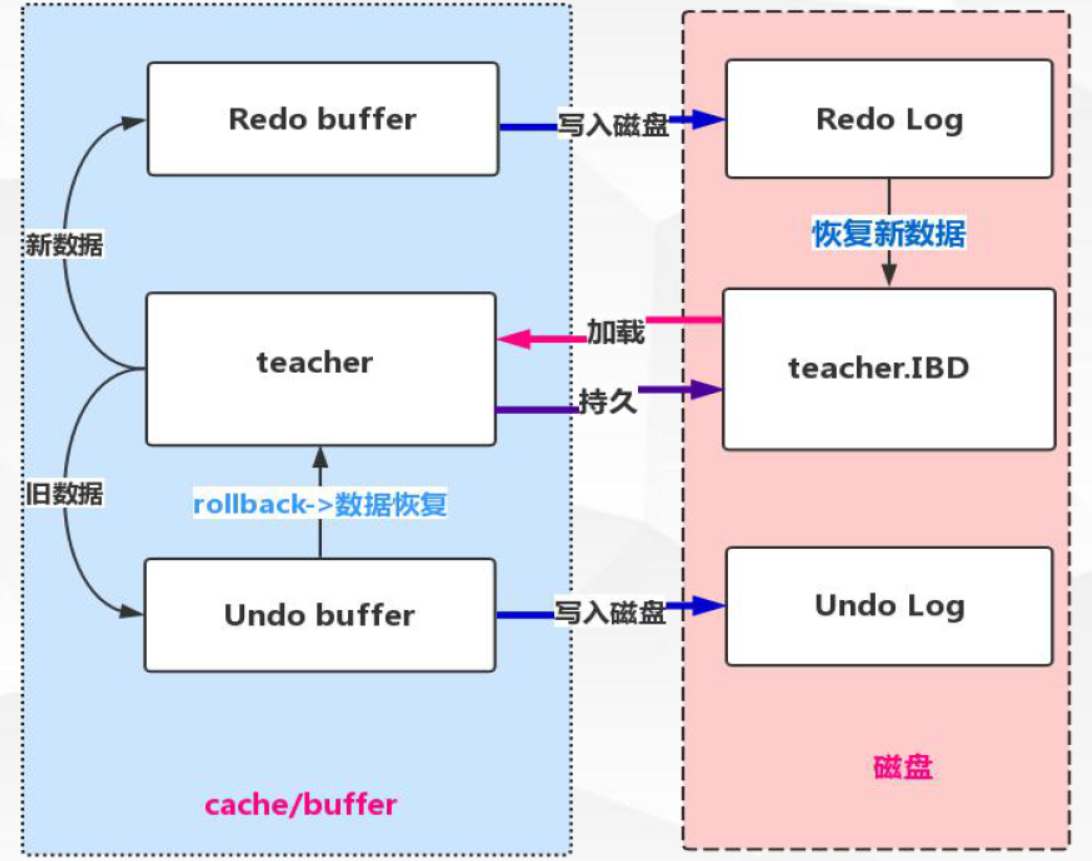
1. undo log指事务开始之前,在操作任何数据之前,首先将需操作的数据备份到一个地方 (Undo Log), 事务处理过程中如果出现了错误或者用户执行了 ROLLBACK语句,Mysql可以利用Undo Log中的备份将数据恢复到事务开始之前的状态
2. UndoLog在Mysql innodb存储引擎中用来实现多版本并发控制. 事务未提交之前,Undo保存了未提交之前的版本数据,Undo 中的数据可作为数据旧版本快照供其他并发事务进行快照读(S锁)
快照读:
SQL读取的数据是快照版本,也就是历史版本,普通的SELECT就是快照读innodb快照读,数据的读取将由 cache(原本数据) + undo(事务修改过的数据) 两部分组成
当前读:
SQL读取的数据是最新版本。通过锁机制来保证读取的数据无法通过其他事务进行修改,UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE都是当前读
Redo Log
Redo log指事务中操作的任何数据,将最新的数据备份到一个地方 (Redo Log)
Redo log的持久:
不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo 中。具体的落盘策略可以进行配置
Redo Log实现事务持久性:
防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redolog进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。
Redo Log配置策略:
指定Redo log 记录在{datadir}/ib_logfile1&ib_logfile2 可通过innodb_log_group_home_dir 配置指定目录存储
一旦事务成功提交且数据持久化落盘之后,此时Redo log中的对应事务数据记录就失去了意义,所以Redo log的写入是日志文件循环写入的
- 指定Redo log日志文件组中的数量 innodb_log_files_in_group 默认为2
- 指定Redo log每一个日志文件最大存储量innodb_log_file_size 默认48M
- 指定Redo log在cache/buffer中的buffer池大小innodb_log_buffer_size 默认16M
Redo buffer 持久化Redo log的策略,Innodb_flush_log_at_trx_commit:
- 取值 0 每秒提交 Redo buffer --> Redo log OS cache -->flush cache to disk[可能丢失一秒内的事务数据]
- 取值 1 默认值,每次事务提交执行Redo buffer --> Redo log OS cache -->flush cache to disk[最安全,性能最差的方式]
- 取值 2 每次事务提交执行Redo buffer --> Redo log OS cache 再每一秒执行 ->flush cache to disk操作
redo, undo log 示例图如下:
plus:
锁升级:
很多数据库如:SQL server就有锁升级的想象,但是innodb并没有锁升级。这是因为innodb根据事务访问的每个页对锁进行管理,采用位图方式,因此不管一个事务锁住页中的一行还是多个记录,其开销通常都是一样的。