在构建大型程序的时候,为了方便代码管理,会根据不同的功能把代码分为多个片段(或模块)并存储在不同的文件中,在代码执行时需要把这些代码模块合并成一个单一的可执行文件,这个合并过程称之为链接。本文详细描述了链接的整个过程。
一、从源代码到可执行目标文件
GCC编译C源码有四个步骤:
预处理——> 编译——> 汇编 ——> 链接
1. 预处理阶段,预处理器将C源代码包含的头文件编译进来,形成预处理文件。
2. 编译阶段,在这个阶段编译器会检查代码的规范性,是否有语法错误等,在确定无误后,编译器把代码翻译成汇编语言。
3. 汇编阶段,汇编器把在编译阶段生成的汇编语言转成二级制目标代码,分为可重定位目标文件,可执行目标代码和可共享目标代码。
4. 链接阶段,链接器把多个可重定位目标文件链接成最终可执行的目标文件。
接下来主要分析了链接阶段;
二、可重定位目标文件
代码模块在编译之后会形成可重定位目标文件,文件中存储的代码为二进制格式,但是这些代码是不能载入内存中运行的,原因有二:
a. 可能确少入口函数,在C语言中,入口函数为main;
b. 一些符号引用(全局变量或函数)缺乏定义,这些符号的定义存在其他模块文件中;
可重定位目标文件中除了基本的程序指令和程序数据之外,还提供了其他的数据结构(比如符号表)来提供链接时需要的信息。可重定位目标文件分为多个节,主要的节段如下;
1. 代码和数据
.text节:存储所有指令和常量,编译器对指令中的未知符号,会生成对应的重定位条目;
.data节: 存储所有已被初始化的全局变量、静态变量;
.bss节:存储所有未被初始化或初始化为0的全局变量和静态变量;
这三个节是目标文件的主体,负责符号定义和符号引用,程序运行时这些节的内容会加载入内存中执行,其他节是为了帮助链接器和加载器完成代码的链接和加载。另外存储数据的还有3个伪节:
.UNDEF:未定义符号,表明被这个目标文件引用,但是在其他地方定义
.COMMON:表示还未分配位置的未初始化的数据目标
.ABS:不该被重定位的符号
2. 符号表
符号表用来描述程序代码和程序数据中存储的指令和数据,其中的符号包含如下几类:
1. 在本模块定义,但是可被其他模块引用的符号,包括函数,全局变量;
2. 在本模块引用,但是在其他模块中定义的符号,包括函数,全局变量;
3. 只被本模块定义和引用的本地符号。带static的函数和带static的全局变量和本地变量;
每一条符号描述的数据结构如下:
1 typedef struct{ 2 int name; 3 char type:4, 4 binding:4; 5 char reserved; 6 short section; 7 long value; 8 long size; 9 }ELF64_Symbol;
符号表中的条目主要描述了符号定义的如下特征:符号类型,即函数还是变量(type),作用域,即全局还是局部(binding),符号定义所在的节(section),符号定义在节中的偏移量(value),符号定义所占空间的大小,连接器正是通过这些信息进行符号解析并对指令和数据进行重定位。
3. rel.text和rel.data
.rel.text: 一个.text节中位置的列表。当链接器将此文件与其他目标文件链接时需要修改这些位置,一般任何调用外部函数或引用全局变量的指令都要修改
.rel.data: 引用或定义的任何全局变量的重定位信息,任何已初始化的全局变量,如果它的初值是一个全局变量地址或外部函数地址,就需要修改
重定位时会修改这两个节段的值,然后链接器会通过这两个字段的条目计算符号引用指向的地址。条目的数据结构如下:
1 typedef struct{ 2 long offset; 3 long type:32, 4 symbol:32; 5 long addend; 6 }ELF64_Rela;
三、可执行目标文件
可执行目标文件可加载到内存中运行,其程序代码和数据中引用的符号都已经定位到对应的虚拟内存空间。由于没有未定义的符号和未初始化的数据目标,所以UNDEF、COMMON和ABS节段是不存在的。可执行目标文件结构如下:
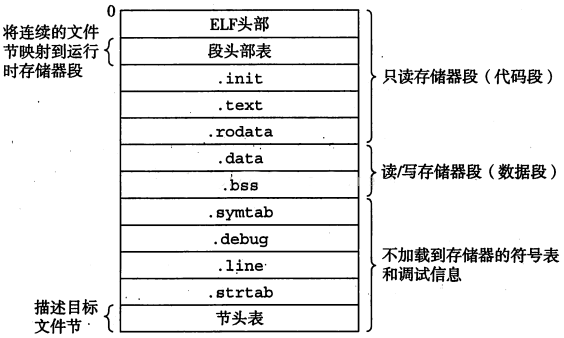
四、链接过程
为了形成可执行的文件,多个可重定位目标文件需要合并在一起,为了正常合并,需要做到以下三点:
1. 解决符号定义冲突,多个符号可能在不同的文件中有多个定义,链接器需要按一定的规则选择其中的一个定义或抛出错误;
2. 重定位,由于多个文件合并成了一个文件,代码和数据在原来文件中的相对地址在新文件中将会发生改变,因此他们的位置需要重新定位,并且需要修改符号表和rel.data即rel.text表;
3. 计算符号引用地址,文件合并之后每个符号引用都有了唯一的定义,因此需要计算符号引用指向的地址,并将符号引用替换为对应的地址;
1. 符号解析——解决符号定义冲突
由于多个模块中可能存在对同一符号的重复定义,通过符号解析过程,可以确保每一个符号有且只有一个定义,并且符号表中对每个定义只存在唯一的符号解析。我们把已经初始化或初始化为0的符号称之为强符号,未初始化的符号称之为弱符号,符号解析规则如下:
规则一: 同一个符号不能存在两个及两个以上的强类型,否则抛出错误;
规则二: 同一个符号如果存在1个强类型和多个弱类型,那么选择强类型;
规则三: 同一个符号如果存在多个弱类型,则随机选择一个;
备注:多重定义全局变量会造成一些意想不到的错误,而且是默默发生的,编译系统不会警告,并会在程序执行很久后才能表现出来,且远离错误处。特别是在模块很多的大型软件中,这类错误很难修正,因此定义全局变量时要习惯赋初始值。
符号解析时,链接器会创建3个空的列表,分别存储未定义的符号(假设为A),已定义的符号(假设为B),以及目标文件列表(假设为C)。初始状态三个列表都为空,接下来链接器会依次选择目标文件,并将其加入列表C,然后根据目标文件的定义和解析规则更新A和B,当所有目标文件都遍历完成后,如果A不为空,说明有的符号引用未定义,会抛出错误。否则表明所有的引用都有唯一的定义,然后就能进行重定位了。
2. 重定位
符号解析完成后,由于每一个符号引用都有对应的唯一的定义,因此可以获得其地址和所占空间大小,根据这些信息可以依次把代码和数据按不同的字段聚合在一起,并重新定位聚合后符号的内存位置,然后修改符号表及rel.text和rel.data表中的符号描述。下面是一个简单的演示示例,两个模块分别定义了两个变量x,y:
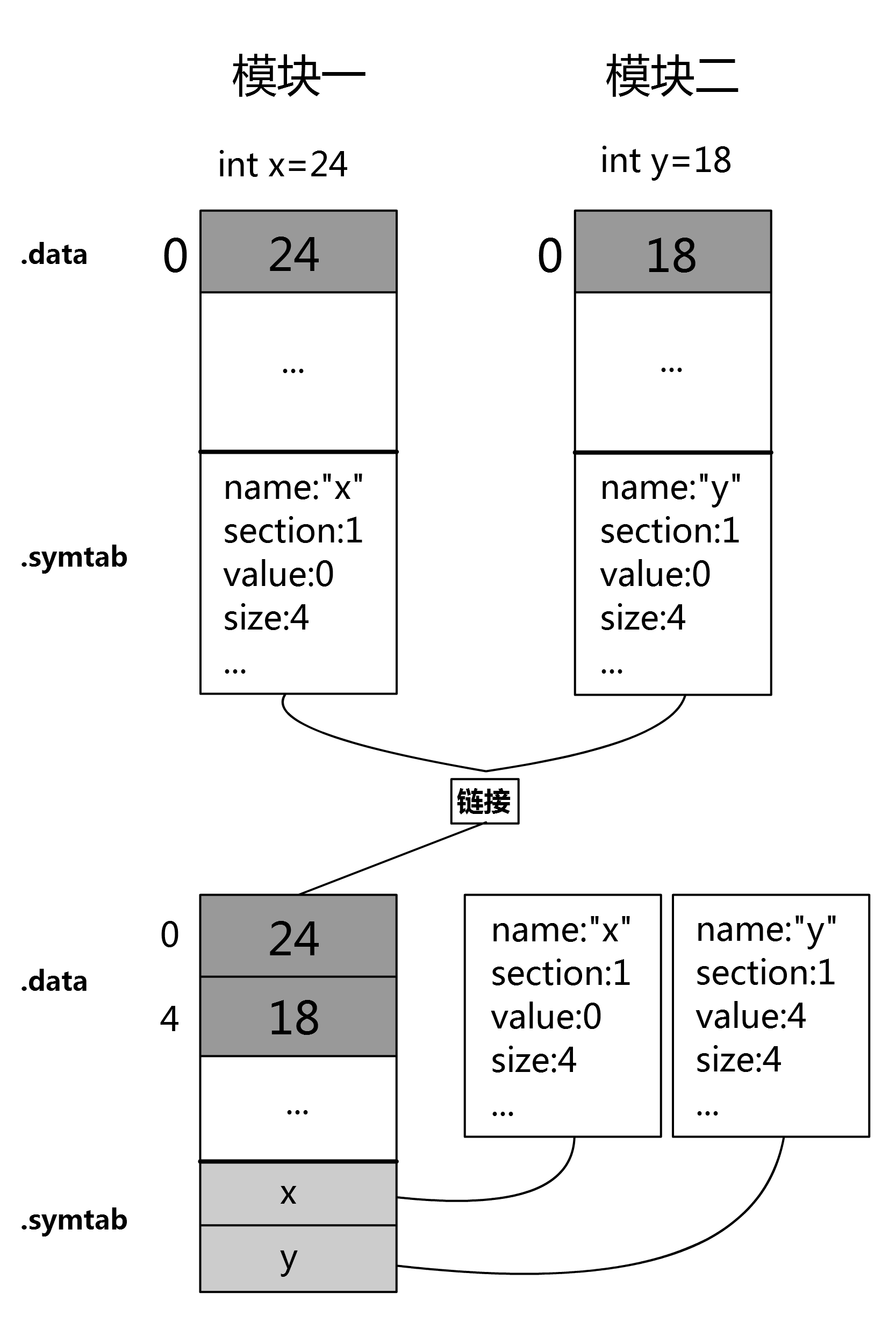
3. 计算符号引用地址
重定位完成后通过rel.text和rel.data中的值可以计算出引用符号的地址,从而把代码和数据中的符号引用替换为相应的内存地址;