这是在博客园的第一篇文章,由于本人还是一个编程菜鸟,也写不出那些高大上的牛逼文章,这篇文章就是对自己这段时间学习python的一个总结吧。
众所周知python是一门对初学编程的人相当友好的编程语言,就像本屌丝一样,一学就对它产生好感了!当然,想要精通它还有很多东西需要学习。那废话不多说了,下面我就来说一下如何用python3.x与mysql数据库构建一个简单的爬虫系统(其实就是把从网页上爬下来的内容存储到mysql数据库中)。
首先就是搭建环境了,这里就简介绍一下我的环境吧。本机的操作系统是win7,python版本是3.3,mysql数据库版本是5.6,mysql-wokebench版本是5.2。
环境搭建完后,就可以开始来写爬虫了。这里实验的网站是鼠绘动漫网(本人是个漫画迷^_^)。先去网站踩点,寻找我们需要的内容,这里我只需要爬网站的每一话
漫画的名字与各漫画的图片链接。下面就直接上代码啦

import urllib.request
import re
from mysql.connector import *
#爬取整个网页的方法
def open_url(url):
req=urllib.request.Request(url)
respond=urllib.request.urlopen(req)
html=respond.read().decode('utf-8')
return html
#爬取每个页面中每一话漫画对应的链接
def get_url_list(url):
html=open_url(url)
p=re.compile(r'<a href="(.+)" title=".+ <br>.+?">')
url_list=re.findall(p,html)
return url_list
#自动进入每一话漫画对应的链接中爬取每一张图片对应的链接并插入到mysql数据库
def get_img(url):
#获取每个页面中每一话漫画对应的链接
url_list=get_url_list(url)
#连接mysql数据库
conn=connect(user='root',password='',database='test2')
#创建游标
c=conn.cursor()
try:
#创建一张数据库表
c.execute('create table cartoon(name varchar(30) ,img varchar(100))')
except:
#count用来计算每一张网页有多少行数据被插入
count=0
for each_url in url_list:
html=open_url(each_url)
p1=re.compile(r'<img src="(.+)" alt=".+?>')
p2=re.compile(r'<h1>(.+)</h1>')
img_list=re.findall(p1,html)
title=re.findall(p2,html)
for each_img in img_list:
c.execute('insert into cartoon values(%s,%s)',[title[0],each_img])
count+=c.rowcount
print('有%d行数据被插入'%count)
finally:
#提交数据,这一步很重要哦!
conn.commit()
#以下两步把游标与数据库连接都关闭,这也是必须的!
c.close()
conn.close()
num=int(input('前几页:'))
for i in range(num):
url='http://www.ishuhui.com/page/'+str(i+1)
get_img(url)
这是数据库的结果:
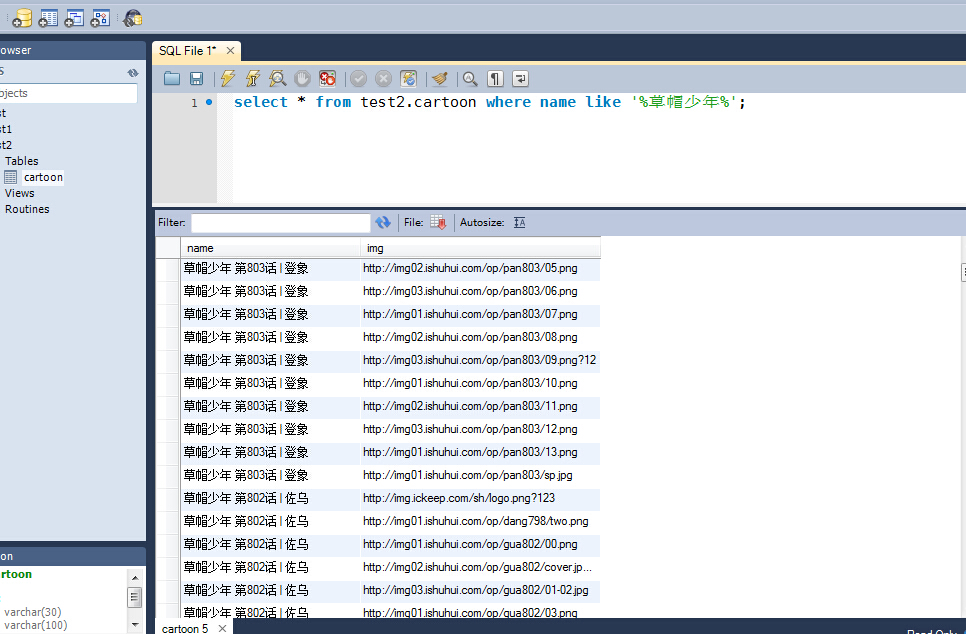
代码已经注释的很清晰了。这里需要注意的是要去下载mysql-connector-python模块,这是一个python与mysql连接的模块,直接
pip install mysql-connector-python --allow-external mysql-connector-python
可以看出用python写爬虫并把数据存入数据库是很简单的,这也是python优雅的地方!当然,这只是一个很简单的爬虫系统,还有很多细节要去完善,只适合小
数据。但是学习都是从简单的开始嘛。
http://www.cnblogs.com/tester-zhenghan/p/4887838.html