之前流水账似的介绍过一篇机器学习入门的文章,大致介绍了如何学习以及机器学习的入门方法并提供了一些博主自己整理的比较有用的资源。这篇就尽量以白话解释并介绍机器学习在推荐系统中的实践以及遇到的问题... 也许很多点在行家的眼里都是小菜一碟,但是对于刚刚接触机器学习来说,还有很多未知等待挑战。
所以读者可以把本篇当做是机器学习的玩具即可,如果文中有任何问题,还请不吝指教。
本篇将会以下面的步骤描述机器学习是如何在实践中应用的:
- 1 什么是推荐系统?
- 2 机器学习的作用
- 3 机器学习是如何使用的?
- 4 基于Spark MLlib的机器学习实践
- 5 推荐资源
翻到最后都是福利啊!
翻到最后都是福利啊!
翻到最后都是福利啊!
问题背景
为什么需要推荐
最开始互联网兴起的时候,是靠分类来组织知识的,最典型的就是hao123;后来随着搜索引擎的兴起,人们主动的获取知识成为流行趋势,例如百度、Google。基于搜索人们可以看到想看的电影,搜到想买的衣服。但是这并能满足所有人的需求,有时候无聊逛一些网站,希望网站能主动发现我的兴趣点,并且主动的给我我感兴趣的内容 ——这就是推荐。比如各种电商网站和视频网站,都可以基于用户搜索的内容和常看的内容,挖掘用户的兴趣,给用户展现用户想看却不知道怎么搜索到的内容。预知用户的需求,这就是推荐的魅力。
这么神奇的功能是怎么做的?难道每个网站都有专门的狗仔跟踪每个用户的需求?这当然是不可能的...
实现推荐的方法有很多,最典型的就是协同过滤。
推荐中的机器学习
协同过滤我就简单的说一下,因为它现在实在是应用的太广泛的....
基于物品的协同过滤
举个例子:
A:前一阵上映的《刺客信条》,我特别喜欢!最近有没有类似的电影啊?
B:我感觉《加勒比海盗》跟他差不多,都是大片!要不你去看看?
A:好呀!那我去看看!这就是基于物品的协同过滤,即推荐相似的物品给这个人。
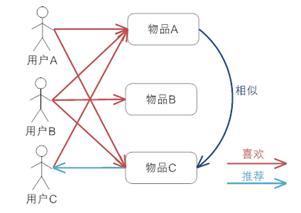
因为A和C物品很相似,因此C用户喜欢了A物品,那么推测他也会喜欢C物品,因此把C物品推荐给他。
基于人的协同过滤
举个例子:
A:最近好无聊,你有没有什么喜欢的电影,介绍一下?
B:我喜欢看《神奇女侠》,要不你去看看?
A:好滴,一般你推荐的电影我都喜欢,那周末我去看看!这就是基于人的协同过滤,即会依据相似的人来推荐喜欢的内容。
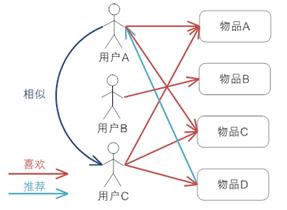
相似,因此就把C喜欢的物品D推荐给了A。
其实推荐就是这么简单,那么后续我们来看看它的内部原理和实践吧!
机器学习
数学知识
上面就是典型的协同过滤的场景,要想弄明白如何基于机器学习实现协同过滤,还需要回顾一下数学的基本知识。
很多人都因为数学而不敢深入学习机器学习,其实大家都是上过高数线代概率论的,所以等真正用它的时候,回去翻翻对应的教材,很快就可以捡起来的。如果没时间也可以在网上看看别人总结的一些公式,最基础的应该知道高数中的求导和微分、矩阵的运算、概率论中的一些分布等等。剩下的就针对性的查查书籍即可。
之前看过一篇帖子,还是很基础的,可以看看:
http://www.cnblogs.com/steven-yang/p/6348112.html
理论原理
在协同过滤中,最基础的是要构建人与物品的评分矩阵,这个评分可能来自于你对物品的操作,比如电上网站中,购买或者收藏物品,浏览物品等等都会作为评分的因素进行计算。最终形成人与物品的二维矩阵:
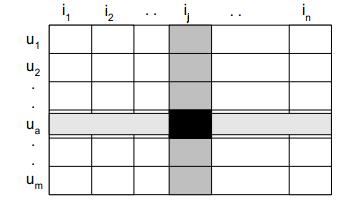
形成上面的矩阵后,就可以进行基于物品或者基于人的推荐了。
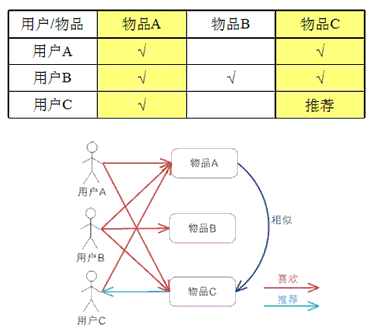
因为物品A和物品C很像,因此物品C推荐给还未购买的用户C
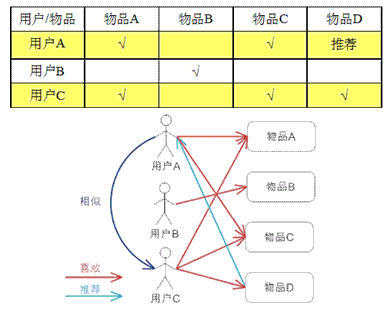
因为用户A和用户C比较像,因此会把用户C购买的物品推给用户A
如何计算是否相似
我之前总结过相似度的一些算法:
http://www.cnblogs.com/xing901022/p/6927024.html
在协同过滤中,常用的是欧氏距离、夹角余弦、皮尔逊系数以及杰卡德距离,有兴趣的可以关注下各个算法的实现。
降维
在真正的电商环境下,往往具有很多的用户以及很多的商品,每个用户并不是对所有的商品都有评分的,因此这个矩阵实际上是一个非常稀疏的矩阵。如果想要在计算机中完全的表示这样一个矩阵,它其实根本无法计算,数据量实在太庞大了(除非你的数据量根本没那么大,那么可以直接跳过这一部分了)。
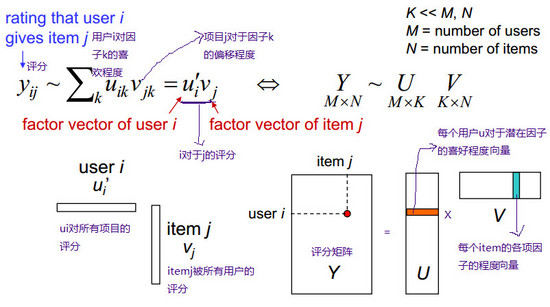
在这种二维矩阵中,最常用的降维手段是SVD——矩阵分解。有矩阵基础的都应该知道,一个MxN的矩阵可以由一个MxK以及KxN的两个矩阵相乘得出。因此降维的手段就是把这个矩阵分解成两个矩阵相乘。
比如,一个矩阵形成下面两个矩阵:
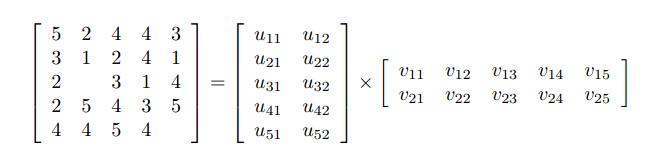
实际在机器学习中,是使用交替最小二乘ALS来求解两个矩阵的。再说就远了,可以简单的理解成,先随机一个MxK的矩阵,然后用ALS求得另一个矩阵,然后固定这个求得的矩阵,再反过来求第一个矩阵,直到找到近似的最优解。这个最后得到的两个矩阵,实际上相乘后,原来有的值还在,但是原来的没有的会预测出来一个分值。基于这个分值,就可以做用户的推荐了。
系统架构
架构设计
关于机器学习中的系统架构,可以仿照美团很多年前写的一篇文章,现在看来对于刚开始构建推荐系统,还是很有帮助的。
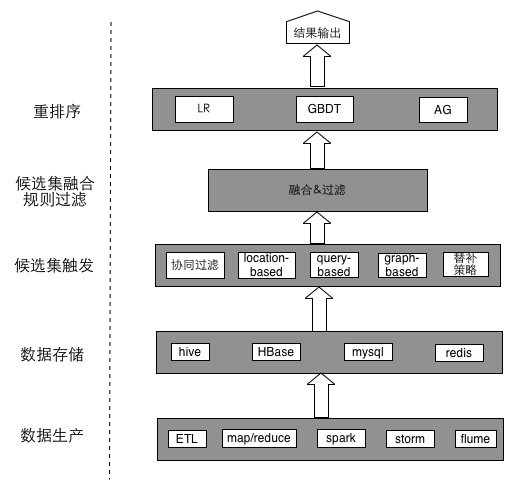
- 在构建推荐系统前,首先应该有足够完善的数仓机制,能拿到想要的底层数据。
- 基于底层数据,可以进行数据的预处理,比如归一化、标准化、去除噪声点离群点等。
- 数据预处理之后,应该通过一定的评分机制形成评分矩阵。
- 基于评分矩阵训练模型,得出模型后就可以进行推荐了。
- 因为推荐的算法可能有多种,最后还需要把各个结果进行融合去重
- 去重后的推荐列表需要经过特定的排序算法,展现给用户。排序的算法一般跟业务相关,比如基于权重、交替显示、分区显示,或者是基于LR等算法进行排序。
另外,这里只看到了离线的部分,通常推荐还需要结合实时的部分,比如用户当前搜索的条件、地理位置、时间季节等,进行实时的跟踪推荐。
这样一个推荐系统的架构就完成了。
注意的问题
- 首先,就是判断你的数据量是不是需要降维,如果数据量很小,降维后推荐的效果未必好;
- 其次,数据最初的调查非常重要。比如有多少用户、有多少商品、多少是合法的数据、清洗的规则等等
- 另外,各种推荐的算法各有特点,需要针对业务场景进行整合和显示。
针对第三种情况,可以详细说下:
- 如果你是在商品的详情页,那么一般用户最常见的需求,一个是对比同类的产品、另一个是查看关联度最高的商品。同类的产品可以基于内容来做、关联度最高的商品可以参考《机器学习实战》中Apriori以及FPgrowth,最典型的就是啤酒和尿布的案例。
- 如果是在购物车的页面,最好是只推荐关联或者搭配活动的商品,不然用户本来想买A,你给推荐了同类的商品B,结果用户反而犹豫不决,不敢下单。
- 如果是在支付完成的页面,那么最好推荐搭配的商品,比如用户刚刚买过螺丝刀,你要是再给推荐一个更便宜的螺丝刀,用户真实恨不得马上退货。如果你再推荐一个扳子或者锤子或者钉子,那感觉就不一样了。
- 如果是列表的详情页,就复杂了。最好还是基于用户当前的搜索来挖掘用户潜在的需求,这样的推荐才会更精确。比如说,你通过历史记录,猜测用户最喜欢的是袜子;结果用户登录网页,搜索的是牛肉干,如果没事结合搜索条件,推荐出来的最靠前的可能是袜子,这并不是用户当前的需求,那效果肯定是不好的。
等等,很多的场景都需要结合业务来设定,上面说的也不是官方的做法,只是个人的想法而已。
代码实践
最后就直接基于Spark MLlib,来实践一下ALS的协同过滤吧!
基于Spark MLlib的协同过滤
代码和测试数据都是基于Spark官方提供的example包,如果读者有兴趣可以查看官网文档,各个例子都有描述。
数据也可以在下面的云盘中下载:
http://pan.baidu.com/s/1dF07bAL
代码如下,修改下路径,就可以直接跑的!
package xingoo.mllib
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by xinghailong on 2017/6/9.
*/
object MovieLensALSTest {
val implicitPrefs: Boolean = true
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("MovieLensALS-Test").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
// 读取评分矩阵
val ratings = sc.textFile("C:\Users\xingoo\Documents\workspace\my\Spark-MLlib-Learning\resouce\sample_movielens_ratings.txt")
.map { line =>
val fields = line.split("::")
// 是否有负的评分
if (implicitPrefs) {
/*
* MovieLens ratings are on a scale of 1-5:
* 5: Must see
* 4: Will enjoy
* 3: It's okay
* 2: Fairly bad
* 1: Awful
* So we should not recommend a movie if the predicted rating is less than 3.
* To map ratings to confidence scores, we use
* 5 -> 2.5, 4 -> 1.5, 3 -> 0.5, 2 -> -0.5, 1 -> -1.5. This mappings means unobserved
* entries are generally between It's okay and Fairly bad.
* The semantics of 0 in this expanded world of non-positive weights
* are "the same as never having interacted at all".
*/
// 为每一行创建Rating
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble - 2.5)
} else {
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}
}.cache()
val numRatings = ratings.count()
val numUsers = ratings.map(_.user).distinct().count()
val numMovies = ratings.map(_.product).distinct().count()
println(s"Got $numRatings ratings from $numUsers users on $numMovies movies.")
// 按照权重切分rdd
val splits = ratings.randomSplit(Array(0.8, 0.2))
// 用80%的数据作为训练集
val training = splits(0).cache()
// 用20%的数据作为测试集
val test = if (implicitPrefs) {
/*
* 0 means "don't know" and positive values mean "confident that the prediction should be 1".
* Negative values means "confident that the prediction should be 0".
* We have in this case used some kind of weighted RMSE. The weight is the absolute value of
* the confidence. The error is the difference between prediction and either 1 or 0,
* depending on whether r is positive or negative.
*/
splits(1).map(x => Rating(x.user, x.product, if (x.rating > 0) 1.0 else 0.0))
} else {
splits(1)
}.cache()
val numTraining = training.count()
val numTest = test.count()
println(s"Training: $numTraining, test: $numTest.")
ratings.unpersist(blocking = false)
val model = new ALS()
.setRank(10) //矩阵分解的隐含分类为10
.setIterations(10) //迭代次数为10
.setLambda(1) //正则项lambda参数为1
.setImplicitPrefs(implicitPrefs)
.run(training)
// 计算模型的准确度
val rmse1 = computeRmse(model, training, implicitPrefs)
val rmse = computeRmse(model, test, implicitPrefs)
println(s"Test RMSE = $rmse1.")
println(s"Test RMSE = $rmse.")
sc.stop()
}
/** Compute RMSE (Root Mean Squared Error). */
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], implicitPrefs: Boolean)
: Double = {
def mapPredictedRating(r: Double): Double = {
if (implicitPrefs) math.max(math.min(r, 1.0), 0.0) else r
}
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map{ x =>
((x.user, x.product), mapPredictedRating(x.rating))
}.join(data.map(x => ((x.user, x.product), x.rating))).values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).mean())
}
}推荐资源——都是福利
数学篇

1 《高等数学·统计大学 第六版》·上册,需要看一下导数和微分
2 《高等数学·同济大学 第六版》·下册,最小二乘在下册,也可以看下!
机器学习理论篇

5 《统计分析方法学》,里面好多重要的概念,比如正则化、标注等等

6 《机器学习》,权威书籍,这个就不给链接了,怕侵权!有想要的私聊吧....
机器学习Spark实战篇

7 《Spark MLlib机器学习实战》,这个同上
http://www.cnblogs.com/xing901022/p/7003968.html