编译实际就是翻译,是将人类易读(为啥?因为开发语言的目的就是为了让人容易使用)的语言转换为机器或程序易读的语言。Java的编译器是javac,它将.java文件编译为.class文件,也就字节码文件。
和中级语言如C不同的是,Java没有直接生成CPU可读的机器码。为了实现跨平台能力,javac生成的字节码会由不同平台的虚拟机来识别。编译的过程大学本科会学到,在课程《编译原理》中;硕士阶段会继续深入学习形式语言和自动机理论。编译原理的课件网上一大堆,这里不说了。
放一张Java编译过程的图(出处见水印,侵删):
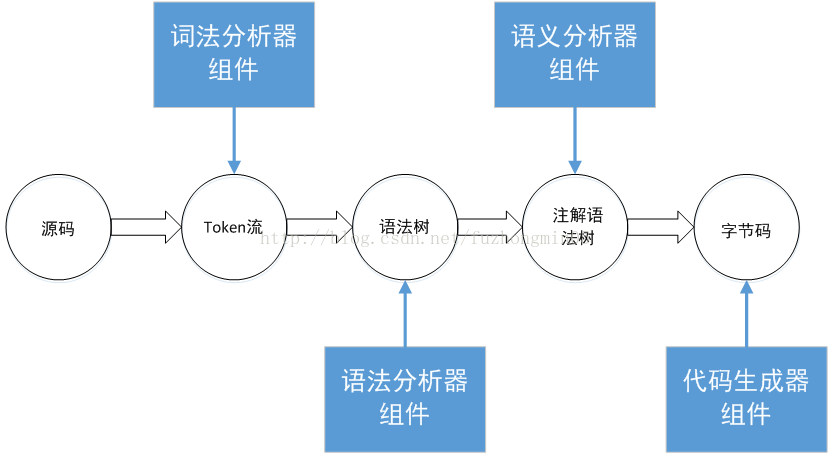
这个只是从编译原理角度看到的Java编译过程。几乎全部语言都是这样的编译过程,但是具体到某一门语言,都会有各自根据语言特性的差异实现。比如Java有注解处理程序,最常见的就是lombok。

- javac会把命令指定的源文件解析为语法树,并把外部可见的定义放到符号表中
- 调用注解处理程序,如果生成了新的文件就重新走第一步,一直到没有新文件产生
- 把语法树解析为类文件。类引入的其他依赖会在类路径寻找并被编译
这三个阶段是由JavaCompiler类控制的,我们来分别看一下这三个过程。
com.sun.tools.javac.main.JavaCompiler类,位于tools.jar中。tools.jar提供了Javac/javap/javadoc等命令的实现
解析和进入
解析
源文件会被处理为unicode字符(因为源文件的字符是任意的,可以是uft-8也可以是gbk,也可以是其他任意),在进入虚拟机以前使用的是优化过的utf-8字符,进入虚拟机后是utf-16。然后通过com.sun.tools.javac.parser.Scanner类转换为token。com.sun.tools.javac.parser.JavacParser会读取token流,并调用com.sun.tools.javac.tree.TreeMaker创建语法树。语法树是从com.sun.tools.javac.tree.JCTree的子类构造的,JCTree是一个抽象类,并且是接口Tree的实现类。
进入
每一棵语法树都会被com.sun.tools.javac.comp.Enter处理,它会将遇到的符号都放入符号表。符号表是编译过程中用到的一张hash表,它会记录变量、方法、自定义类等的定义信息,可用于检查代码是否正确(比如变量是否重复定义,因为重复定义会在符号表中冲突),使用符号的时候就直接从符号表拿,并按照符号表中记录的定义使用。语法树生成阶段的产出是一个TODO list,里面是需要分析并生成类文件的语法树。创建语法树包括3个阶段,类排队进入下一个阶段。
在第一阶段,所有类符号都被放入各自的可访问范围(public/private/包/子类),并递归判断引用类的可访问性。完成的时候会给一个com.sun.tools.javac.comp.MemberEnter对象。
如果存在package-info.java,它的语法树也会放进TODO list
在第二阶段,通过调用MemberEnter.complete()方法标记类被处理完。完成包括两步:(1)可以看到类的参数、子类、接口等信息;(2)进入自己的可访问范围。(2)依赖(1),所以(1)后面进入了一个halfcompleted队列。

第一阶段决定了一个定义能不能被访问到,第二阶段是Lazy的,类的成员第一次被访问才会进入符号表,但是最终队列里的类都会被处理掉变成完成。这是由MemberEnter的两阶段来保证的。
注解处理
这里用到com.sun.tools.javac.processing.JavacProcessingEnvironment。
从概念上看,注解处理是编译前的一个小步骤,主要就是解析源文件,看一下需要调用哪个注解处理器。第一轮之后如果产生了新文件,就多执行几轮。直到没有新文件了就开始编译。
而实际上,在文件被编译以前,可能不知道该用哪个注解处理器。所以为了避免使用注解处理器前进行不必要的解析并放进符号表,JavacProcessingEnvironment有点没按照概念模型走,但是依然满足在实际编译前就处理了注解。怎么办的呢?
在文件被解析并进入符号表后,JavacProcessingEnvironment会被调用。一般来说,如果符号有误就会中止处理并报错,但是有可能符号定义是通过注解产生的(比如lombok的getter/setter/ToString),这时候不能报错。
所以要处理注解,要使用单独的类加载器。
注解处理器运行后,JavacProcessingEnvironment会决定是否需要进一步处理。需要继续处理注解的话会创建一个新的JavaCompiler对象,从头开始处理新文件。如此反复。最后JavacProcessingEnvironment会返回一个JavaCompiler对象提醒开始编译,这个JavaCompiler对象要么是最初用于解析源文件那个,要么是最后一轮注解处理中用到那个。
分析和生成
这一步是在前面的基础上生成.class文件的。
分析语法树的时候如果发现依赖了但是没在javac命令中指定的类,就去源文件路径和类路径下查找。如果在类路径下找到,就直接拿过来看看是否是合法使用;如果在源文件路径下找到,就要进行解析、放入符号表、进入TODO list。
语法树的分析和类文件生成是由一些处理TODO list条目的“观察者”完成的。这里并不要求观察者们一个一个的去处理,因为是在内存中完全不必要。只要最终每个条目都被处理即可(除非出错了没法处理)处理过程会用到这些类:
- com.sun.tools.javac.comp.Attr
- com.sun.tools.javac.comp.Flow
- com.sun.tools.javac.comp.TransTypes
- com.sun.tools.javac.comp.Lower
- com.sun.tools.javac.jvm.Gen
一旦类文件生成,前面生成的东西就不用了。为了节省内存空间会把他们的引用改成null,以让GC去回收掉。