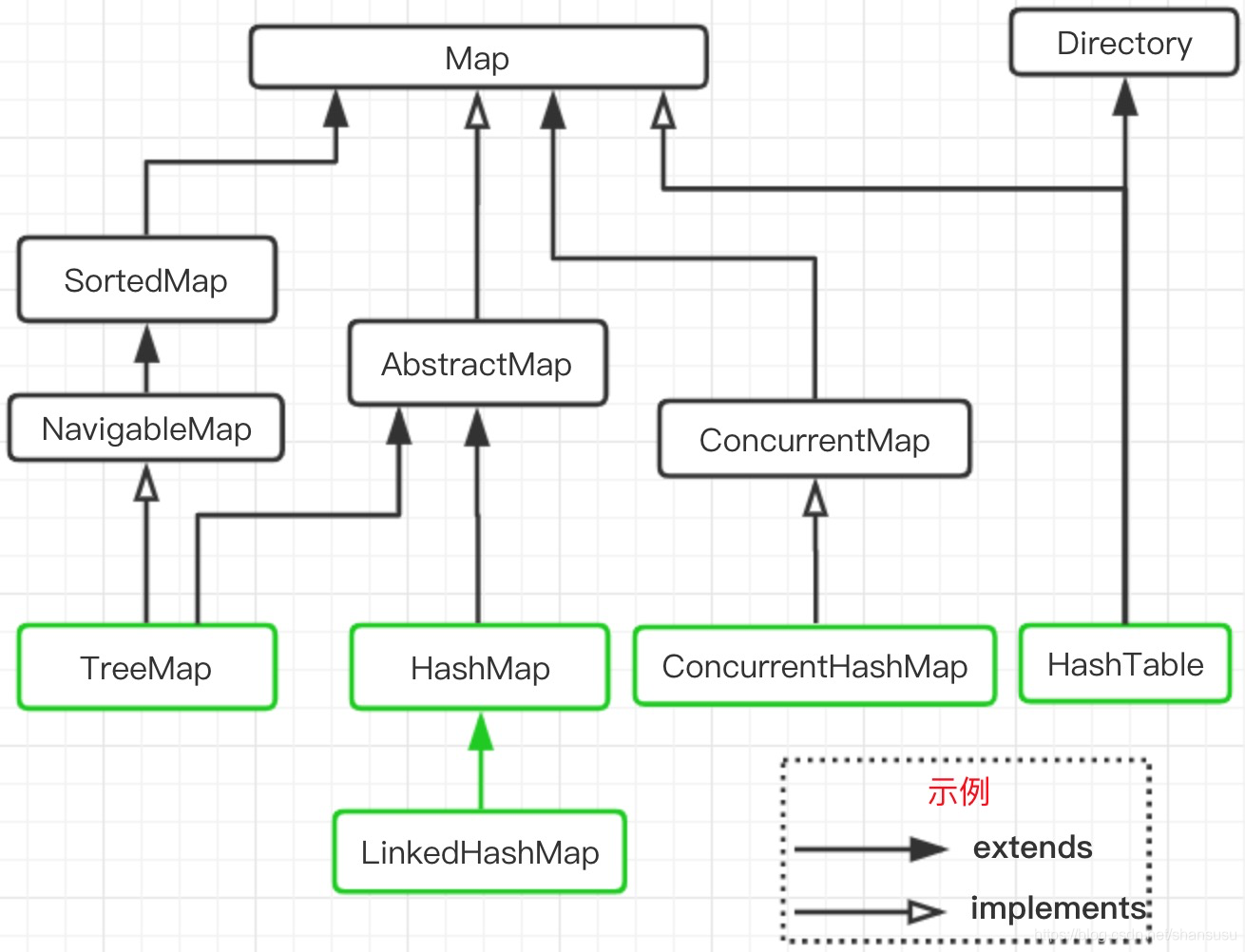
1、HashMap的继承关系
2、基本属性
- 非线程安全
- 初始容量16,加载因子0.75,扩容为原来的2倍
- key可以存null(hash值为0),但智能存一个,value可以存null,可以有多个
- 1.8前数组+链表,1.8后数组+链表+红黑树,桶内的节点个数>8后执行treeifyBin方法,判断长度是否大于最小红黑树容量64,小于扩容,大于则进行树化
- 扩容是2的倍数
3、JDK8中的HashMap有哪些改动?
- JDK7中的底层实现是数组+链表,JDK8中使用的是数组+链表+红黑树。
- JDK7中扩容时有可能出现死锁,JDK8中通过算法优化不会出现死锁了。
- JDK8中对算哈希值的哈希算法进行了简化以提高运算效率
- 链表的插入方式由头插改成了尾插法
4、JDK8中为什么要使用红黑树?
数据量特别大的时候会产生hash碰撞,导致某个链表数据量特别大,链表的查找速度比较慢复杂度是O(n),影响比较差;因此优化成节点数量>8时转化成红黑树,查找的时间复杂度为O(logn)
5、HashMap的put流程
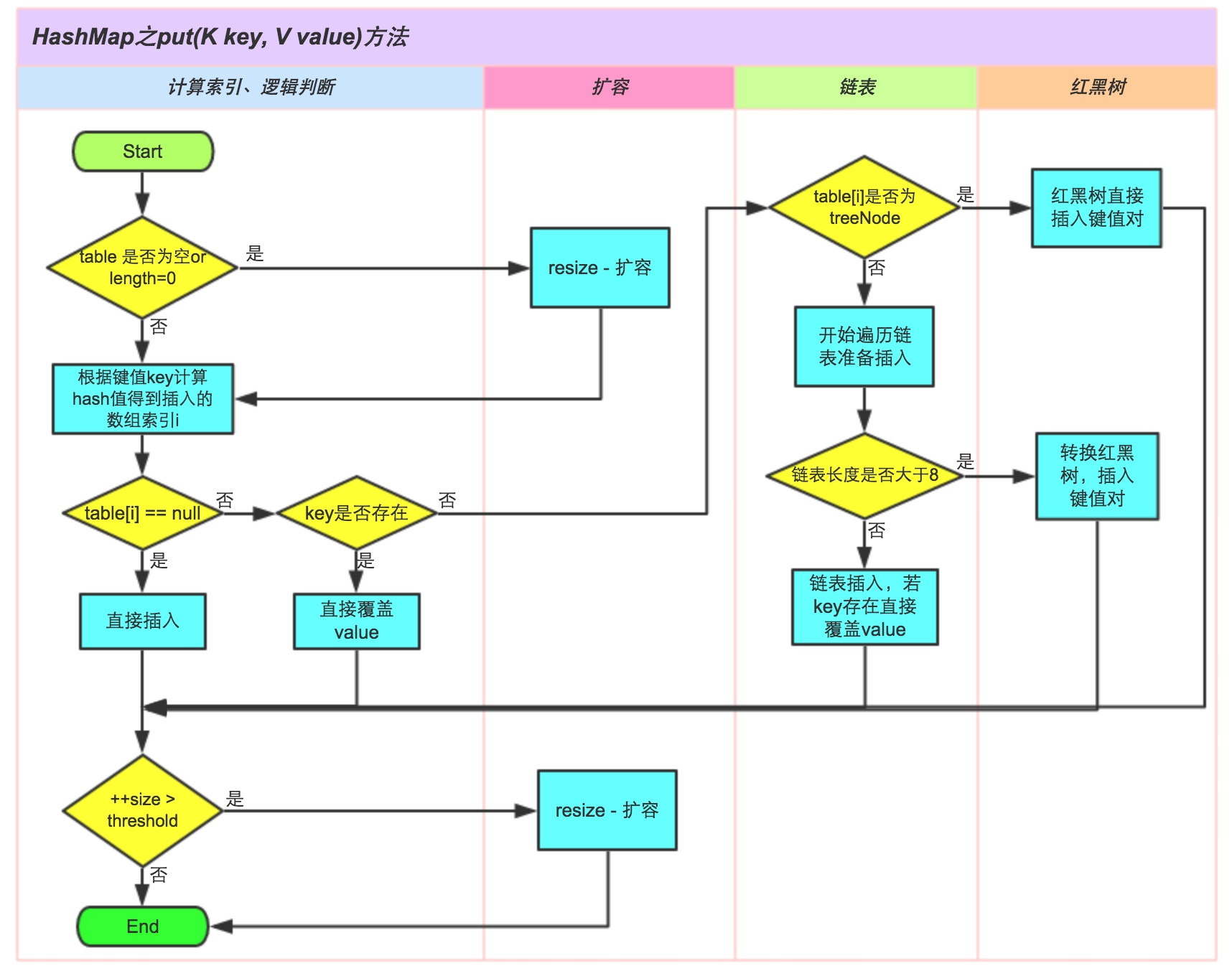
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
2)另一种理解
- 对 Key 求 Hash 值,然后再计算 下标。
- 如果没有碰撞,直接放入桶中,
- 如果碰撞了,以链表的方式链接到后面,
- 如果链表长度超过阀值(TREEIFY_THRESHOLD == 8),就把链表转成红黑树。
- 如果节点已经存在就替换旧值
- 如果桶满了(容量 * 加载因子),就需要 resize。
6、get流程
7、扩容
8、为什么以2的倍数进行扩容?
降低发生碰撞的概率,使散列更均匀。根据key的hash值计算bucket的下标位置时,为了得到这个索引值必须对扰动后的数跟数组长度进行取余运算,即 hash % n (n为hashmap的长度),又因为&比%运算快,n如果为2的倍数,就可以将%转换为&,结果就是 hash & (n-1),所以HashMap长度是2的倍数
9、计算hash的时候为什么 ^(h>>>16) ?

10、HashMap线程安全方面会出现什么问题
1)put的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-valu对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2)resize而引起死循环
这种情况发生在HashMap自动扩容时,当2个线程同时检测到元素个数超过 数组大小 ×负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环。
如果还不明白的话看这两篇文章就可以:
11、Map的遍历方式
参考: