本文翻译自http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/ (自学笔记,能力有限,翻译太烂了,建议看原文)
本文用于介绍Word2Vec的Skip-Gram神经网络结构,本文不会介绍Word2Vec的常规介绍性知识和抽象性见解,而将会深入研究Skip-Gram神经网络模型。
Skip-Gram模型
Skip-Gram模型的最基本形式非常简单,但是经过一些微调和增强后它开始变得复杂。Word2Vec使用机器学习中常用的方法来训练网络,此网络是一个具有单个隐藏层的简单网络。在这里我们的目标是获取隐藏层的权重矩阵(权重矩阵的行向量实际上就是我们要学习的“单词向量”)。
假任务
“假任务”是指获取隐藏层的权重矩阵。训练神经网络将执行以下操作:给定句子中间的特定单词(输入单词),网络告诉我们词汇中每个单词成为输入单词的附近单词(“附近”意味着此算法有一个“窗口大小”参数,这是一个超参数。例如窗口大小为5时,意味着前后各5个共10个单词)的概率。输出概率将与找到输入的单词附近的每个词汇单词的可能性有关。例如,给训练后的网络输入“苏联”,那么“联盟”和“俄罗斯”这样的单词的输出概率就会比“西瓜”和“袋鼠”这样的无关单词的输出概率要高得多。
我们将通过向神经网络提供训练文档中找到的单词对(word pairs)来训练神经网络。下面的示例显示了一些训练样本(单词对),单词对将从句子“The quick brown fox jumps over the lazy dog.”中获取。此处设置“窗口大小”为2,以蓝色突出显示的单词是输入单词(也可以叫做“中心单词”),输入单词附近的单词可以叫做“背景单词”。如图所示。
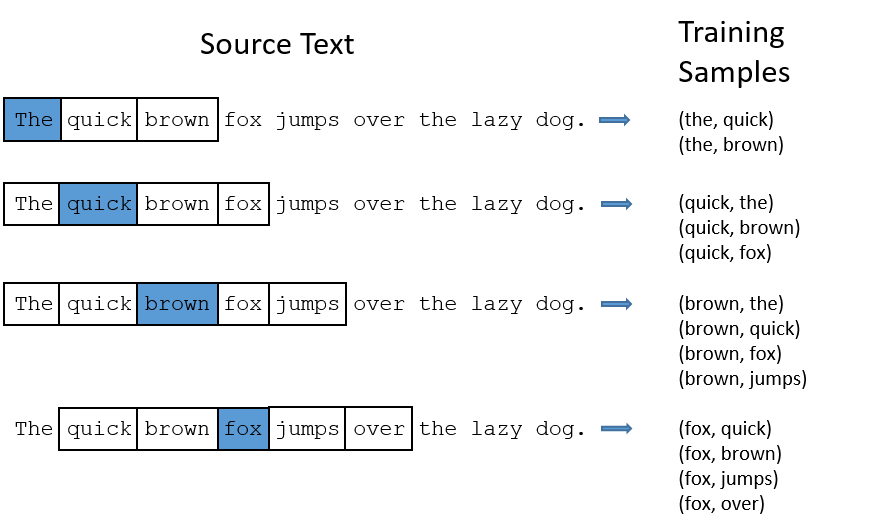
这样我们能够获取几十个单词对,网络会从每个配对出现的次数中学习统计信息。例如,(“苏联”,“联盟”)出现的次数可能会比(“苏联”,“萨斯卡彻特”)出现的次数多,网络训练结束后,如果输入“苏联”一词,则输出“联盟”的可能性会比输出“萨斯卡彻特”的可能性高的多。
模型细节
神经网络无法直接训练单词,因此需要一种适合网络训练的方法来表示单词。首先,我们先根据我们的训练文档构建单词词汇库--假设我们构建的词汇库中有10000个不同的单词。
这样,例如“ants”可以表示为一个10000维的one-hot向量,此向量在与“ants”对应的地方值为1,其他位置为0。网络的输出是一个10000维的单个向量,对于我们的词汇表中的每个单词,其中包含随机选择的邻近单词就是该词汇表单词的概率。神经网络结构如图所示。
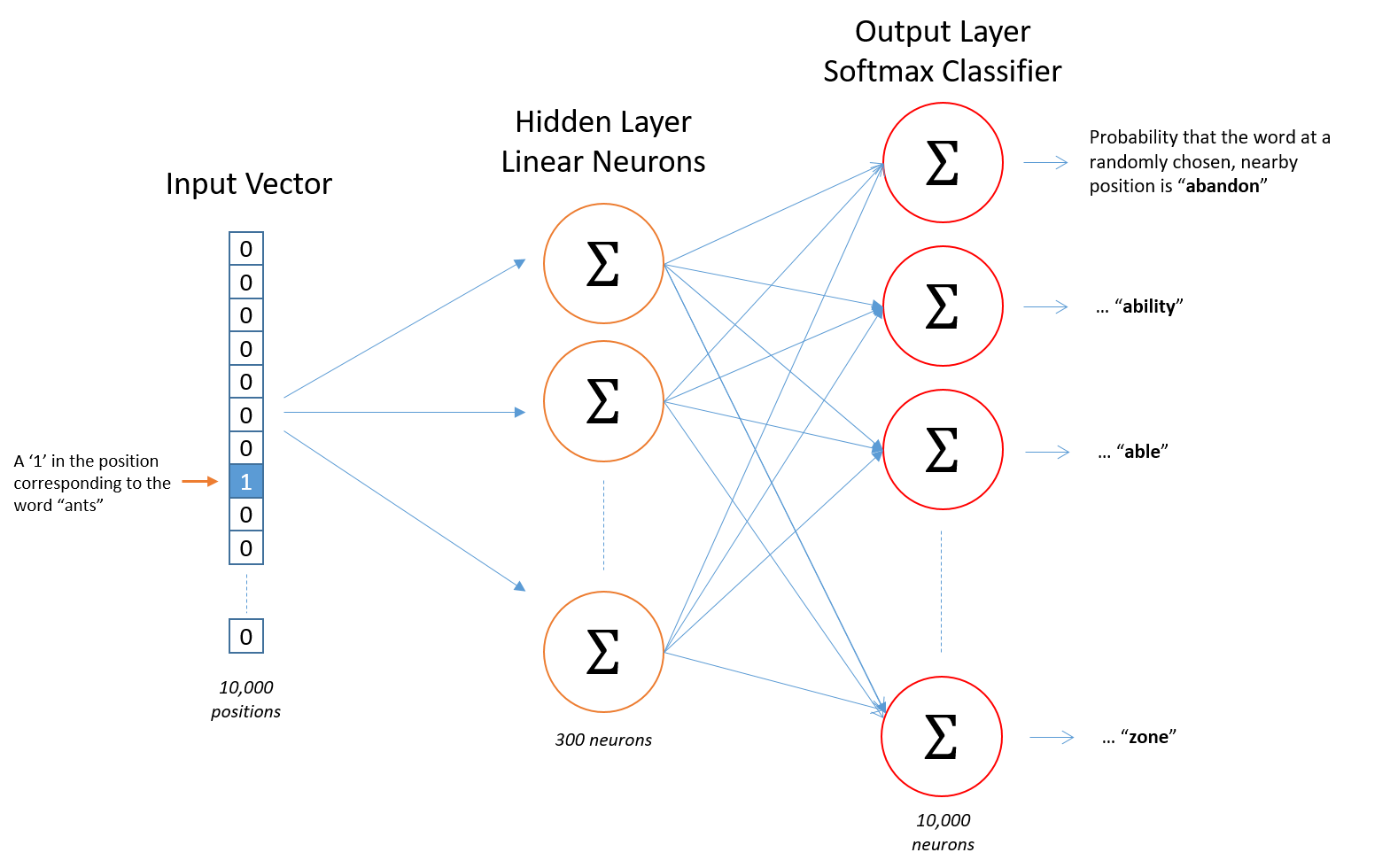
隐藏神经元上没有激活功能,但是输出神经元使用softmax,稍后再说。
当在单词对上训练此网络时,输入是代表输入单词的one-hot向量,训练输出也是代表输出单词的one-hot向量。但是,当您在一个输入单次上评估经过训练的网络时,输出向量实际上将是一个概率分布(即一堆浮点数,而不是一个one-hot向量)
隐藏层
对于我们的示例,我们需要学习的实际上是300维的单词向量。因此隐藏层将由权重矩阵表示,该矩阵具有10000行(词汇表中的每个单词一个)和300列(每个隐藏神经元一个)。
查看此权重矩阵后会发现,它的行向量其实就是我们所需要的单词向量。如图所示。
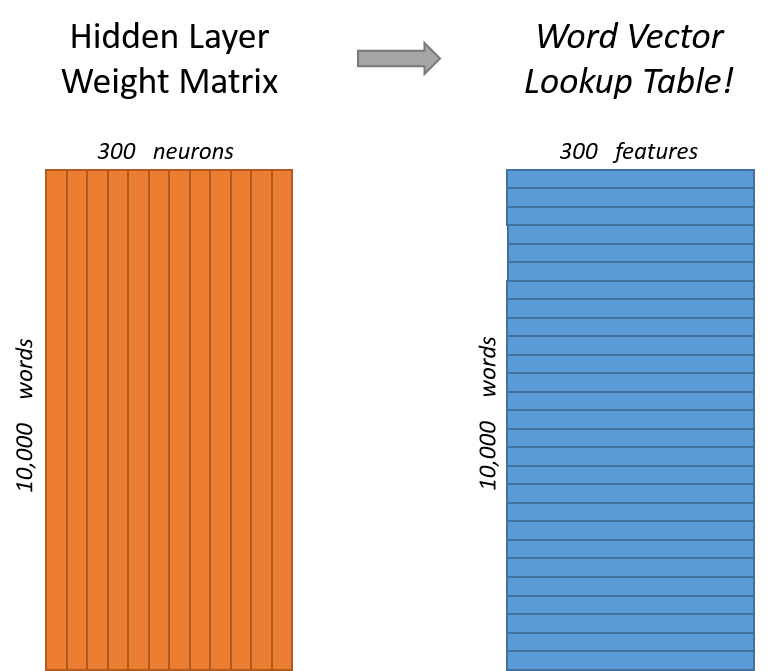
因此,这一切的最终目的实际上是学习此隐藏层的权重矩阵,完成后就可以扔掉输出层了。
现在,回到训练的模型定义中来。你可能会问:“那个one-hot向量几乎全为0,这有什么作用?”如果将1*10000的one-hot向量乘以10000*300的矩阵,则实际上仅选择了对应于“1”的矩阵行。示例如下:

这意味着改模型的隐藏层实际上只是用作查找表。隐藏层的输出只是输入单词的“单词向量”。
输出层
之后“ants”的1*300的单词向量被输送到输出层。输出层是softmax分类器。每个神经元会产生0和1之间的输出,所有这些输出值的和等于1。
具体来说,每个输出神经元都有一个权重向量,将其与隐藏层的单词向量相乘,然后将函数应用于exp(x),最后为了使输出总和等于1,我们将这个结果除以所有10000个输出节点的和。
