一,概述
Storm用来实时计算源源不断产生的数据,如同流水线生产。
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
二,storm和hadoop的区别

Storm用于实时计算,Hadoop用于离线计算。
Storm处理的数据保存在内存中--redis,源源不断;Hadoop处理的数据保存在hdfs文件系统中,一批一批。
Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
Storm与Hadoop的编程模型相似。
三,storm的核心组件

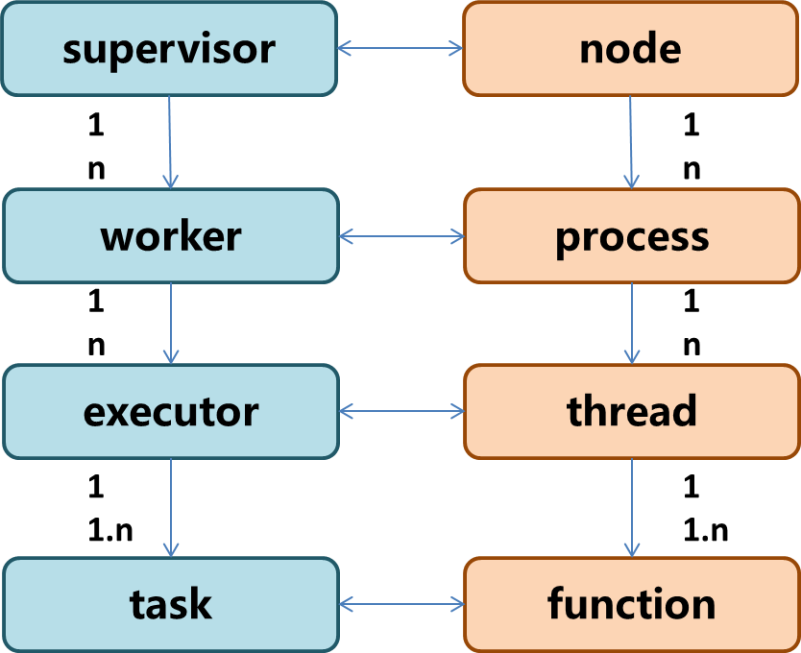
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
executor:线程管理器
四,storm编程模型

Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
数据清洗--》去掉垃圾数据、数据格式化--》把数据格式设置为我们想要的格式--》数据分析
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
Stream:表示数据的流向。
五,集群环境搭建
1,下载解压安装包,关闭防火墙。
2,修改配置文件
vi /home/storm/conf/storm.yaml
########### These MUST be filled in for a storm configura
tion
storm.zookeeper.servers:
- "server1"
# - "server2"
nimbus.host: "192.168.184.131"
storm.local.dir: "/home/storm"
ui.port: 10086
supervisor.slots.ports:
- 6700
- 6701
- 6702
#
# nimbus.seeds: ["host1", "host2", "host3"]集群配置
3,分发安装包
scp -r /export/servers/apache-storm-0.9.5 storm02:/export/servers 然后分别在各机器上创建软连接 cd /export/servers/ ln -s apache-storm-0.9.5 storm
4,启动集群
在nimbus.host所属的机器上启动 nimbus服务 cd /export/servers/storm/bin/ nohup ./storm nimbus & 在nimbus.host所属的机器上启动ui服务 cd /export/servers/storm/bin/ nohup ./storm ui & 在其它个点击上启动supervisor服务 cd /export/servers/storm/bin/ nohup ./storm supervisor &
5,查看集群
访问nimbus.host:/8080,即可看到storm的ui界面。
六,storm常用操作命令
1,提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
storm jar /home/data.jar com.main wordCount
2,杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill wordCount -w 10
3,停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte wordCount
4,启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
5,重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
七,storm日志及进程的熟悉
查看supervisor上worker运行日志信息,运行的jar包在logs目录下会有输出的结果。
八,storm任务提交过程

九,storm的并发机制