概述
现代操作系统了提供了一种对主存的抽象概念,叫做虚拟内存。它为每个进程提供了一个非常大的,一致的和私有的地址空间。虚拟内存提供了以下的三个关键能力:
- 它将主存看成是一个存储在磁盘空间上的地址空间的高速缓存,主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据。
- 它为内阁进程提供了一致的地址空间,简化了内存管理。
- 它保护了每个进程的地址空间不被其他进程破坏。
物理和虚拟寻址
计算机的主存可以看做是一个由 M 个连续的字节大小的单元组成的数组。每个字节都有一个唯一的物理地址(Physical Address,PA)。第一个字节的地址为 0,接下来的地址为 1,以此类推。CPU 访问内存的最简单的方式是使用物理寻址(physical addressing)。

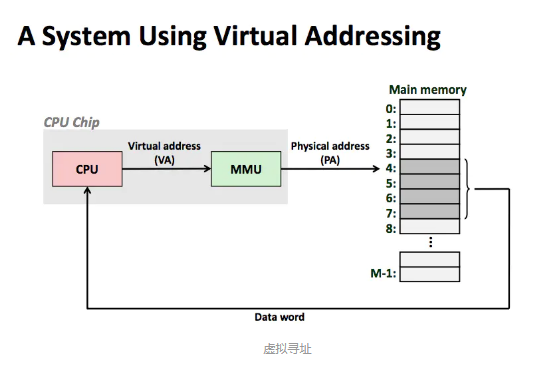
现在处理器采用的是一个程序虚拟寻址(virtual addressing)的寻址方式,如上图所示。CPU 通过生成一个虚拟地址(virtual address,VA)来访问主存,这个虚拟地址在被送到主存之前会先转换成一个物理地址。将虚拟地址转换成物理地址的任务叫做地址翻译(address translation),地址翻译需要 CPU 硬件和操作系统之间的配合。 CPU 芯片上叫做内存管理单元(Menory Management Unit, MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
地址空间
地址空间(address space)是一个非负整数 地址 的有序合集:{0,1,2,... }
在一个带虚拟内存的系统中,CPU 从一个有 N= 2 的 n 次方 个地址的地址空间中生成虚拟地址,这个地址空间就称为虚拟地址空间:
{0,1,2,3,...., N-1}。
一个系统还有一个地理地址空间,对应于系统中物理内存的 M 个字节: {0,1,2,3,..., M-1}。
一个地址空间的大小通常是由表示最大地址所需要的位数来描述的,比如,一个包含 N = 2 的 n 次方 个地址的虚拟地址空间就叫做一个 n 位地址空间,现代操作系统通常支持 32 位或者 64 位虚拟地址空间。
虚拟内存做为缓存的工具
从概念上来说,虚拟内存被组织成为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,也就是字节数组。每个字节都有一个唯一的虚拟地址作为数组的索引。磁盘上活动的数组内容被缓存在主存中。在存储器结构中,较低层次上的磁盘的数据被分割成块,这些块作为和较高层次的主存之间的传输单元。主存作为虚拟内存的缓存。
虚拟内存(VM)系统将虚拟内存分割成称为虚拟页(Virtual Page,VP)的大小固定的块,每个虚拟页的大小为 P = 2 的 p 次方 字节。同样的,物理内存被分割为物理页(Physical Page,PP),大小也为 P 字节(物理页也称作页帧(page frame))。
在任意时刻,虚拟页面的集合都分为三个不相交的子集:
- 未分配的,VM 系统还未分配(或者创建)的页,未分配的页没有任何数据和它们关联,因此不占用任何内存空间。
- 缓存的,当前已缓存在物理内存中的已分配页。
- 未缓存的,未缓存在物理内存中的已分配页。

上图展示了在一个有 8 个虚拟内存的虚拟内存中,虚拟页 0 和 3 还没有被分配,所以在磁盘上不存在。虚拟页 1,4,6 被缓存在物理内存中。虚拟页 2,5,7 已经被分配了,但是当前并没有缓存在主存中。
DRAM 缓存的组织结构

我们使用 SRAM 缓存来表示位于 CPU 和 主存之间的 L1, L2 和 L3 高速缓存,使用 DRAM 缓存来表示虚拟内存系统中的缓存,也就是主存。
在存储器层次结构中, DRAM 比 SRAM 慢个大约 10x 倍,磁盘比 DRAM 慢大约 10, 000x 倍。因此 DRAM 缓存的不命中比 SRAM 缓存中的不命中要昂贵的多,因为 DRAM 缓存不命中需要和磁盘传送数据,而 SRAM 缓存不命中是和 DRAM 传送数据。
归根到底, DRAM 缓存的组织结构是由巨大的不命中开销驱动的。
页表
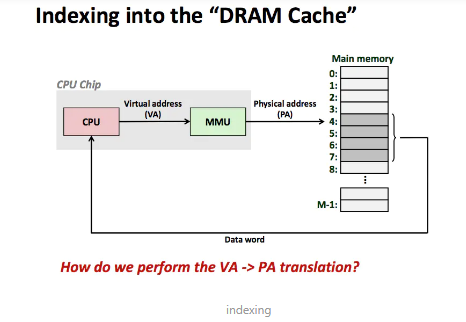
VA 是通过什么方式转成 PA 呢 ?
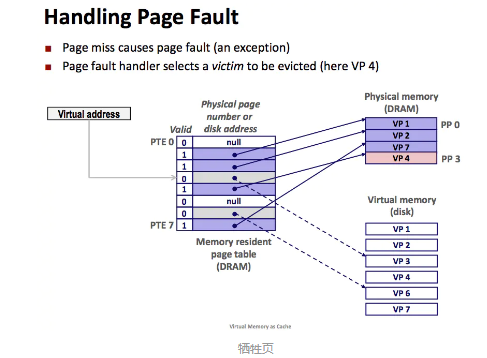
同任何缓存一样,虚拟内存系统必须有某种方法来判定一个虚拟也是否缓存在 DRAM 的某个地方。如果命中缓存,那么虚拟内存系统还必须确认这个虚拟页存在哪个物理页中。如果没有命中缓存,那么虚拟内存系统必须判断虚拟页存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到 DRAM,替换这个牺牲页。
这些功能由软硬件联合提供,包括操作系统软件,MMU 中的地址翻译硬件和一个存放在物理内存中叫页表(page table)的数据结构,页表将虚拟页映射到物理页。每次地址翻译硬件将一个虚拟地址转换成物理地址时都会读取页表。

上图展示了一个页表的基本结构,页表就是一个页表条目(Page Table Entry,PTE)的数组。虚拟地址空间中的每个页在页表中都有一个 PTE。在这里我们假设每个 PTE 是由一个有效位(Valid bit)和一个 n 位地址字段组成的。有效位表明了该虚拟页当前是否被缓存在 DRAM 中。如果有效位为 1,那么地址字段就表示 DRAM 中相应的物理页的起始位置,这个物理页缓存了该虚拟页。如果有效位为 0,那么一个 null 地址表示这个虚拟页还未被分配,否则对应的这个地址就指向该虚拟页在磁盘上的起始位置。
上图所示中一共有 8 个虚拟页和 4 个物理页的页表,4 个虚拟页 VP1, VP2, VP4, VP7 当前被缓存在 DRAM 中,VP0 和 VP5 还未被分配,而剩下的 VP3 和 VP6 已经被分配了,但是当前未被缓存。



局部性
当我们了解了虚拟内存的运作机制之后,是不是觉得虚拟内存的效率会很低呢?因为页面没有命中的代价非常大。是不是担心虚拟内存会影响程序的性能呢?其实虚拟内存运作的非常好。它充分利用了局部性( locality )的原理。

在程序整个运作过程中,程序引用的不同页面的总数可能超出了物理内存的总大小,但是局部性原则可以保证在任意时刻,程序将趋向于在一个较小的活动页面(active page)集合上工作,这个集合被称作工作集(working set)或者常驻集合(resident set)。在程序初始开销之后也就是将工作集页面调入主存,接下来对这个工作集的访问会产生命中,这样就不会产生额外的磁盘消耗。
如果程序有良好的时间局部性,那么虚拟内存将工作的非常好。如果程序没有良好的时间局部性也就是工作集的大小超出了主存的大小,那么程序将会进入一个称作 抖动(thrashing)的状态,这个时候页面将不断地换进换出,程序会出现性能问题。
虚拟内存作为内存管理的工具
虚拟内存大大简化了内存管理,操作系统为每个进程提供了一个独立的虚拟地址空间。

在上图中,进程 1 的页表将 VP1 映射到 PP2, VP2 映射到 PP6。进程 2 的页表将 VP1 映射到 PP8, VP2 映射到 PP6。在这里可以看到多个虚拟页面可以映射到同一个共享的物理页面上。
按需页面调度和独立的虚拟地址空间的结合,让 虚拟内存简化了链接和加载,代码和数据共享,以及应用程序的内存分配。
- 简化链接。独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处。
- 简化加载。虚拟内存使得容易向内存中加载可执行文件和共享对象文件。将一组连续的虚拟页面映射到任意一个文件中的任意位置的表示法称作内存映射(memory mapping)。Linux 提供了一个 nmap 的系统调用,允许应用程序自己做内存映射。
- 简化共享。独立地址空间为操作系统提供了一个管理用户进程和操作系统自身之间共享的一致机制。一般情况下,每个进程都有自己私有的代码、数据、堆栈。这些内容不与其他进程共享。在这种情况下,操作系统创建页表,将相应的虚拟页映射到不连续的物理页面。
- 简化内存分配。虚拟内存向用户进程提供一个简单的分配额外内存的机制。当一个用户程序要求额外的堆空间时候,操作系统分配 k 个适当的连续的虚拟内存页面,并且将他们映射到物理内存的中的 k 个任意页面,操作系统没有必要分配 k 个连续的物理内存页面。
虚拟内存作为内存保护的工具
虚拟内存大大简化了内存管理,操作系统提供独立的地址空间使得区分不同进程的私有内存变得容易,但是地址翻译机制可以使用一种自然的方式拓展到提供更好的访问控制。每次 CPU 生成一个地址时,地址翻译硬件都会读一个 PTE ,通过在 PTE 上添加一些额外的控制位来控制对一个虚拟页面内容的访问。
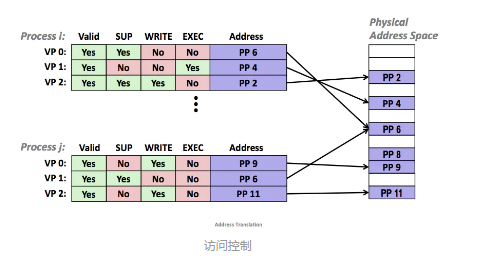
在上图中,每个 PTE 添加了三个控制位, SUP 位表示进程是否必须运行在超级用也就是内核模式下才能访问该页,WRITE 位控制页面的写访问, EXRC 位控制页面的执行。如果有指令违反了这些控制条件,那么 CPU 会触发一个一般保护故障,将控制传递给内核中的异常处理程序。
地址翻译

上图中展示了页面命中的场景,CPU 硬件的执行步骤:
- 处理器 生成一个虚拟地址,并把它传送给 MMU。
- MMU 生成 PTE 地址,并从高速缓存/主存中请求这个 PTE 。
- 高速缓存/主存向 MMU 返回 PTE。
- MMU 构造物理地址,并把它传送给高速缓存/主存。
- 高速缓存/主存返回所请求的数据字给处理器。
页面命中是全部由硬件来处理的,既然有页面命中,那么就有页面不命中的场景。
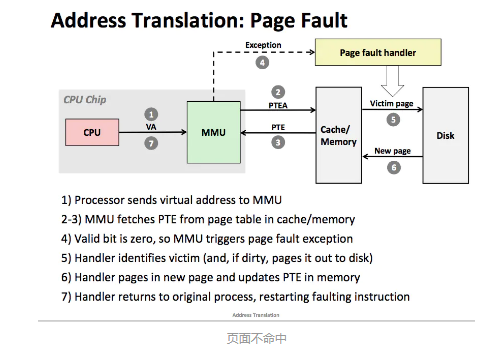
上图展示了页面不命中的场景, CPU 硬件的执行步骤:
- 处理器 生成一个虚拟地址,并把它传送给 MMU。
- MMU 生成 PTE 地址,并从高速缓存/主存中请求这个 PTE 。
- 高速缓存/主存向 MMU 返回 PTE。
- PTE 中的有效控制位为 0 ,所以 MMU 触发了一次异常,传递 CPU 中的控制到操作系统内核中的缺页异常处理程序。
- 缺页处理程序确定出物理内存中的牺牲页,如果这个页面已经被修改了,则把它换出到磁盘。
- 缺页处理程序调入新的页面,并更新内存中的 PTE。
- 缺页处理程序返回原来的进程,再次执行导致缺页的指令, CPU 将引起缺页的虚拟地址重新发送给 MMU ,因为虚拟页面现在存在主存中,所以会命中,主存将请求字返回给处理器。
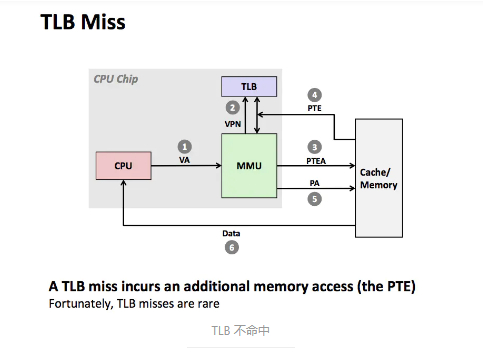
地址翻译的过程执行起来太慢了?怎么解决呢?答案你应该也猜到了,就是添加缓存。在 MMU 中包含了一个 TLB (Translation Lookaside Buffer)缓存。

我们来看看 TLB 命中的场景,
- 第 1 步 CPU 产生一个虚拟地址
- 第 2 和 3 步 MMU 从 TLB 中取出对应的 PTE 。
- 第 4 步 MMU 将这个虚拟地址翻译成一个物理地址,并且将它发送到高速缓存/主存。
- 第 5 步 高速缓存/主存将所请求的数据字返回 CPU。
如下图所示,当 TLB 不命中的时候, 多了步骤 3 和 4 ,MMU 必须从 L1 缓存中取出对应的 PTE , 新取出的 PTE 存放在 TLB 中,可能会覆盖一个已经存在的 PTE 。
总结
虚拟内存对于计算机系统来说是核心的,虚拟内存也是强大的,同时虚拟内存也是危险的。虚拟内存还包括多级页表,内存映射,动态内存分配,垃圾收集等等内容。限于篇幅,这里只是叙述了一些基本的概念,帮助程序员理解 虚拟内存 这个概念,对具体细节不做深究。若是有兴趣的话,可以参考 《深入理解计算机系统》书籍,了解更多关于计算机虚拟内存要点。
参考
本文是华盛顿大学的公开课 《 The Hardware / Software Interface 》的课程笔记,该课程的参考书籍是大名鼎鼎的 CSAPP 也就是《 深入理解计算机系统 》这书。文章截图来源于课程,文章的内容也参考了 CSAPP 的书本内容。
- https://courses.cs.washington.edu/courses/cse351/17wi/videos.html
- https://book.douban.com/subject/26912767/
作者:要上班的斌哥
链接:https://www.jianshu.com/p/13e337312651
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。