最近还在看Python版的rcnn代码,附带练习Python编程写一个小的网络爬虫程序。
抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的。比如说你在浏览器的地址栏中输入 www.baidu.com 这个地址。打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了 一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。HTML是一种标记语言,用标签标记内容并加以解析和区分。浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。
统一资源标志符(Universal Resource Identifier, URI), 统一资源定位符(Uniform Resource Locator,URI),URL是URI的一个子集。
总的来说,网络爬虫的原理很简单,就是通过你事先给定的一个URL,从这个URL开始爬,下载每一个URL的HTML代码,根据你要抓取的内容,观察HTML代码的规律性,写出相应的正则表达式,将所需的内容的HTML代码抠出来,保存在列表中,并按具体要求处理扣出来的代码,这就是网络爬虫,其实就是一个对若干有规律的网页的HTML代码进行处理的程序。(当然,这只是简单的小爬虫,对于一些大型爬虫,可以设置有很多线程分别处理每一次获取到的URL地址)。其中要实现正则表达式的部分内容,应该导入re包,要实现URL的加载,阅读功能需要导入urllib2包。
显示网页代码:
import urllib2 response = urllib2.urlopen('http://www.baidu.com/') html = response.read() print html
当然,在请求服务器服务的过程中,也会产生异常:URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。
对网页的HTML代码进行处理:
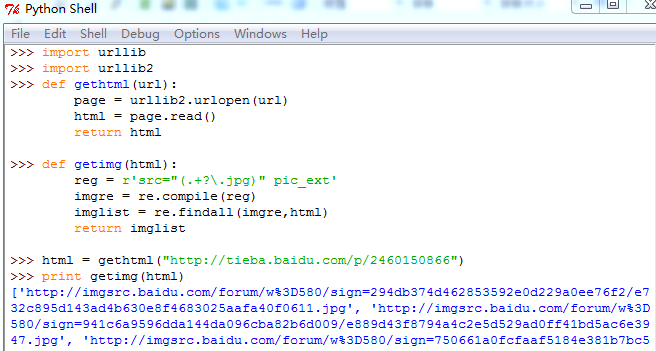
import urllib2 import re def getimg(html): reg = r'src="(.+?.jpg)" pic_ext' imgre = re.compile(reg) imglist = re.findall(imgre,html) return imglist
上面代码找到参数HTML页面中所有图片的URL,并且分别保存在列表中,然后返回整个列表。程序执行结果如下:
整篇文章比较低级,还望各位看官不吝赐教。除了程序中所用到了这些基本的方式,还有更强大的Python爬虫工具包Scrapy。