上一篇文章介绍的是用zip(*data_matrix) ,即便是你使用矩阵,还是要自己加上一些标点符号,括号之类,还是比较复杂的。令人心里痒痒的。
总是感觉不够高效,因为我们最平常喜欢做的是复制粘帖。所以做一个能直接读取文档,并且将其输入到数据库中的东西,应该非常好用,这个对某些喜欢做爬虫的网站来说,应该比较有市场。 :D
这篇就是来用直接打开文档编辑,来重新创造数组或者元组的。
先复习一下上次知识,这里我引用以前的一篇博文的部分内容。
http://blog.csdn.net/spaceship20008/article/details/8316983
################################怎么使用矩阵 zip(*matrix) ##################################
.1.4. Nested List Comprehensions
The initial expression in a list comprehension can be any arbitrary expression, including another list comprehension.
Consider the following example of a 3x4 matrix implemented as a list of 3 lists of length 4:
>>> matrix=[... [1,2,3,4],... [5,6,7,8],... [9,10,11,12], # 注意,这里12后面没有","没有逗号。官方的错误了,这样matrix里面将有4个元素,而第四个为空!!! 官方wiki错误了!... ]
The following list comprehension will transpose rows and columns:
这里,运算从右向左,进行完了之后,进入右边,因为右边有方括号,所以输出的将是数列。
当完成第一个row[0](来自于matrix[0])之后,for row in martix 又进行输出row[0],只不过这次是matrix[1]中的,...,一直输出到matrix[2]完成后跳出左边的循环,继续右边for i in range(4)的循环。目的是为了遍历输出martix[0], martix[1], matrix[2] 中的所有索引为i 的元素。
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
As we saw in the previous section, the nested listcomp is evaluated in the context of the for that follows it, so this example is equivalent to:
>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
which, in turn, is the same as:
这是是我自己想到的。我会用这样的方法
>>> transposed = []
>>> for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
In the real world, you should prefer built-in functions to complex flow statements. The zip() function would do a great job for this use case:
>>> list(zip(*matrix))
[(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)] #注意这里输出的全部变成了tuple元组了,跟上面的不同。zip是一种特殊的类型,在python3中
See Unpacking Argument Lists for details on the asterisk in this line.
- zip(*iterables)
-
Make an iterator that aggregates elements from each of the iterables.
Returns an iterator of tuples, where the i-th tuple contains the i-th element from each of the argument sequences or iterables. The iterator stops when the shortest input iterable is exhausted. With a single iterable argument, it returns an iterator of 1-tuples. With no arguments, it returns an empty iterator. Equivalent to:
def zip(*iterables): # zip('ABCD', 'xy') --> Ax By sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)
The left-to-right evaluation order of the iterables is guaranteed. This makes possible an idiom for clustering a data series into n-length groups using zip(*[iter(s)]*n).
zip() should only be used with unequal length inputs when you don’t care about trailing, unmatched values from the longer iterables. If those values are important, use itertools.zip_longest() instead.
zip() in conjunction with the * operator can be used to unzip a list:
>>> x = [1, 2, 3] >>> y = [4, 5, 6] >>> zipped = zip(x, y) >>> list(zipped) [(1, 4), (2, 5), (3, 6)] >>> x2, y2 = zip(*zip(x, y)) >>> x == list(x2) and y == list(y2) True
##################################引用结束############################################
现在我们来使用怎么直接获取文档中的数据:
复制粘帖(最简单的):
打开PDF文档,复制需要表单的内容。到txt文档里面,发现txt文档里面全部都是换行的。单排数据。

途中图表内容都要单独复制一下。
看看复制到txt什么效果。
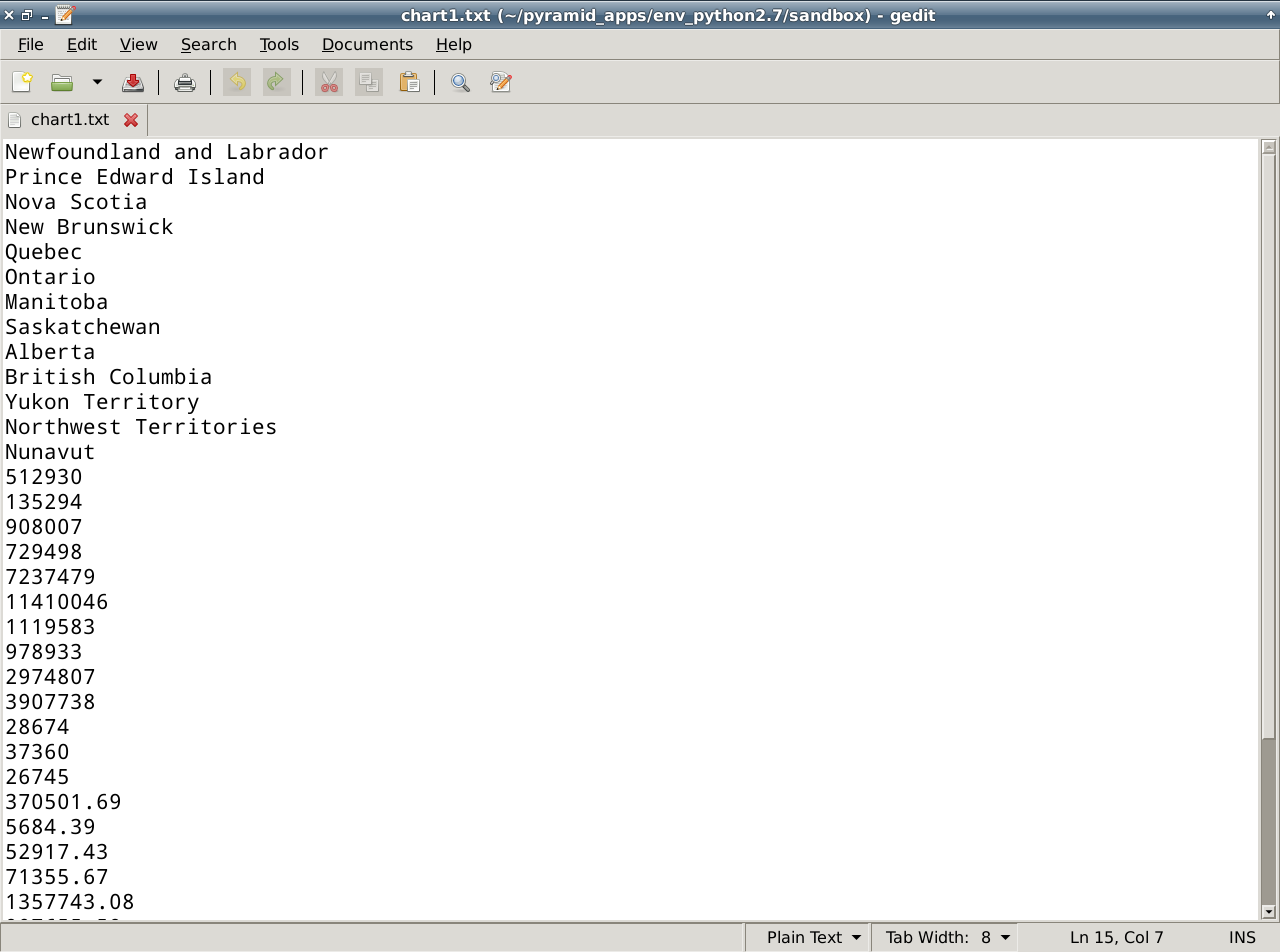
就这样,可以随意复制很多有相同列的不同行的数据了!!!网上的任何的都行。都能到成数组出来,用下面的方法
只要你知道有多少行就行,~列都不用管,反正所有元素是行乘以列,保证txt不要缺少元素就好。
保存成chart1.txt (注意一点是最后一行不能是空行,这个复制粘帖的时候要注意,自己删除就好)
下面是我写的代码:
data = open('chart1.txt','r') temp = [] # declare an empty list [''] for line in data: temp.append(line.strip()) temp.pop() # we have to delete the last Null element of the list # delete him: [''] ##### ## lines Number essential. No need to care about how many rows there are. ##### temp_big = [] for k in range(13): # 13 refers to how many lines of the chart new = [] for i in range(k,len(temp),13): # len(temp) is of x*13. x = rowsNumber new.append(temp[i]) temp_big.append(new) print temp_big
显示效果是:
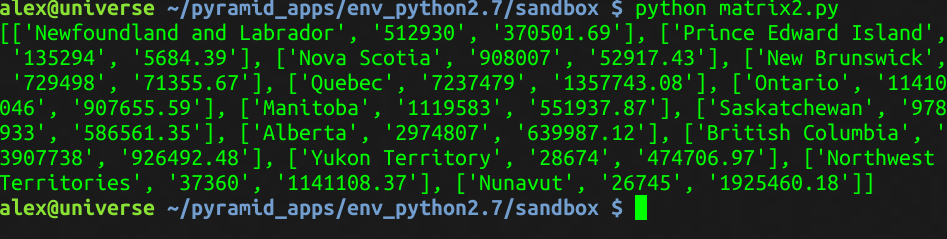
chart1.txt的文档是:
Newfoundland and Labrador
Prince Edward Island
Nova Scotia
New Brunswick
Quebec
Ontario
Manitoba
Saskatchewan
Alberta
British Columbia
Yukon Territory
Northwest Territories
Nunavut
512930
135294
908007
729498
7237479
11410046
1119583
978933
2974807
3907738
28674
37360
26745
370501.69
5684.39
52917.43
71355.67
1357743.08
907655.59
551937.87
586561.35
639987.12
926492.48
474706.97
1141108.37
1925460.18
用上面方法,可以畅通无阻的复制粘帖了。
所以,以后遇到不喜欢输入数据库数据的时候,可以使用这两篇博客的方法。
1. 利用 矩阵方法
1.) 自己编写 需要自己了解矩阵是怎么来的,行列转换怎么换的。可以参考上一篇博客 http://www.cnblogs.com/spaceship9/archive/2013/04/20/3032806.html
2.)使用zip(*matrix)方法。这个build-in功能非常好,还是具体参考一下上一篇博客
2. 利用 阅读文档方法
将需要的数据表文档,按行,按行倍数,每行累加到一个chart1.txt 文档内,然后,再通过上面的python程序,取得数据,获得数组。然后,就遍历插入数据库即可了。
为了研究数据库,讨厌手动输入程序,所以,多多钻研了一些。