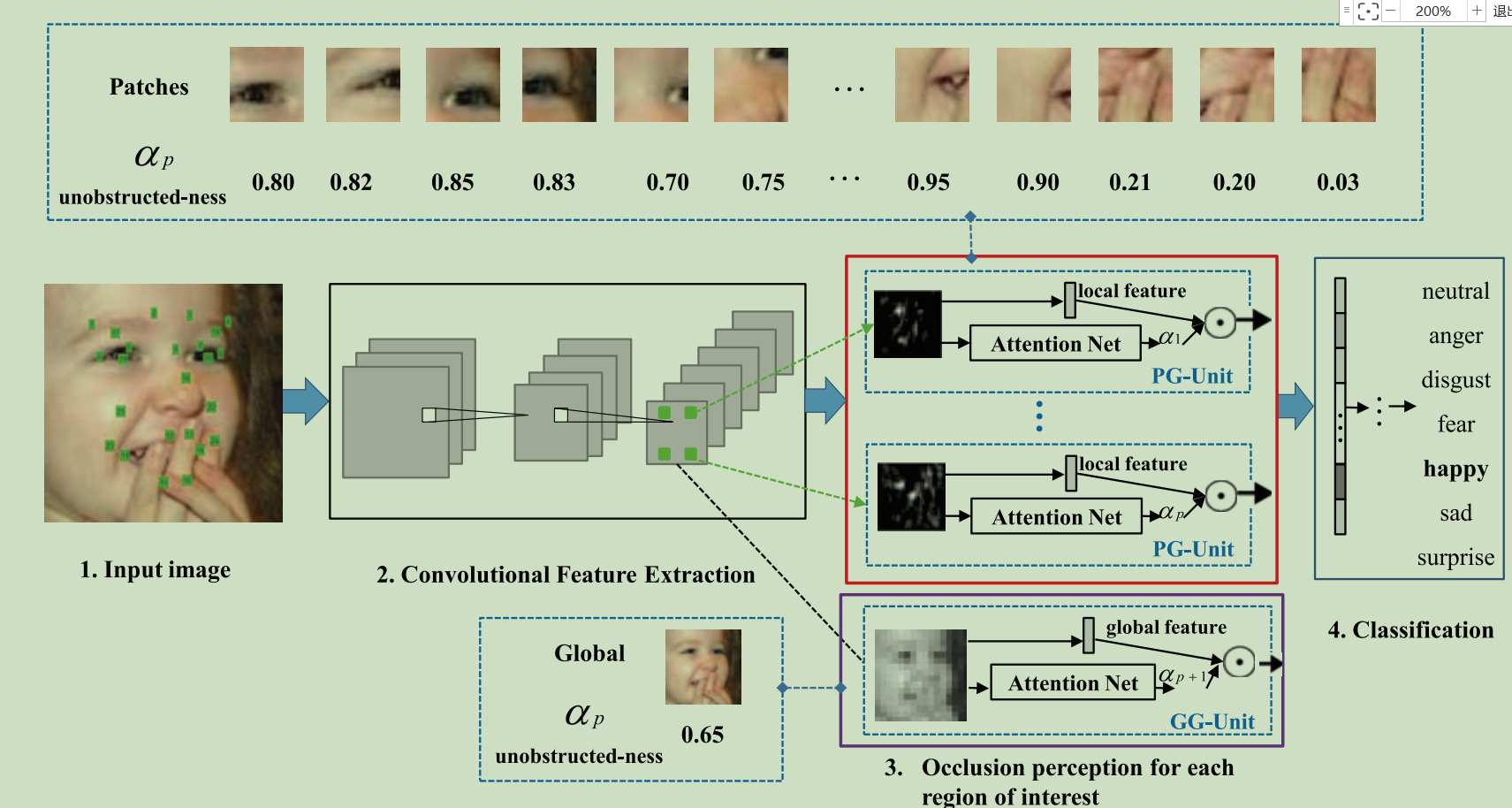
为什么有这篇文章(motivation)?
作者认为人脸不不同的region对FER(人脸表情识别)的贡献是不同的,所以作者把人脸裁剪为patch的形式(利用关键点得到24个patch),计算每个patch对FER的贡献度(利用attention)。但是local patch可能会漏掉一些有用的信息,所以作者提出了global ACNN,对local ACNN获得的信息作为补充。
怎么做?(仅记载local patch部分,global与local操作一样)
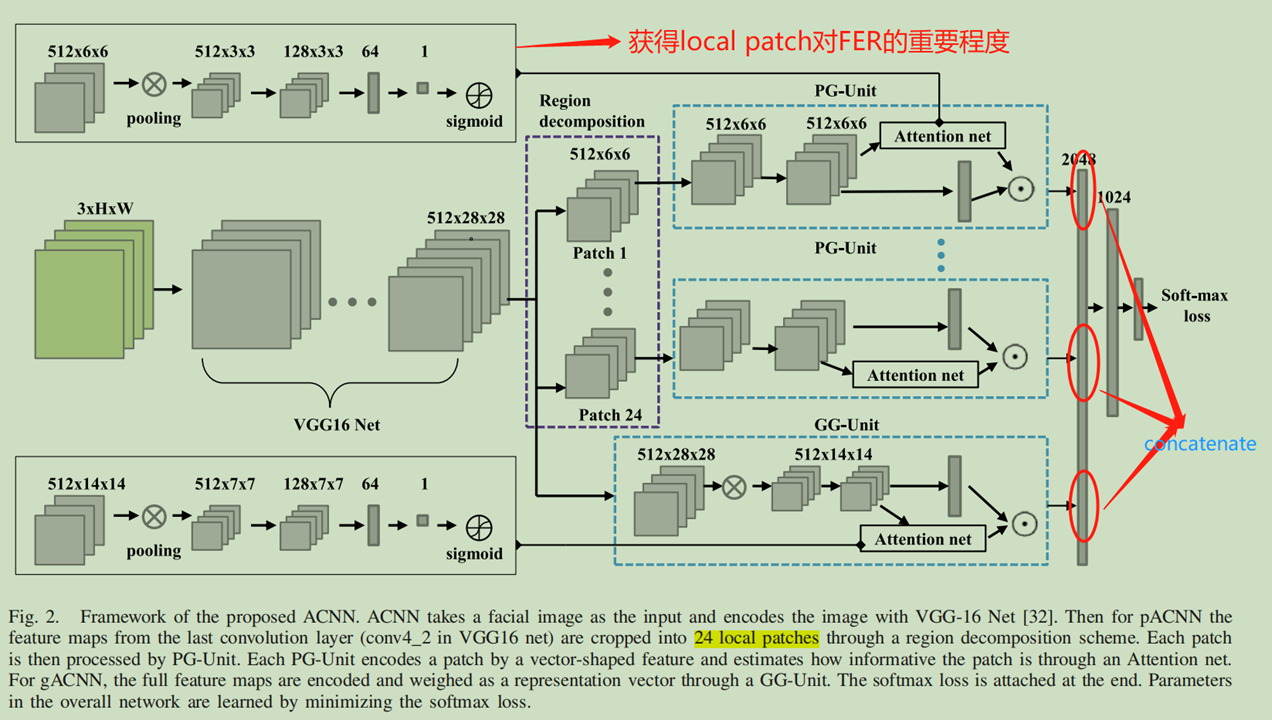
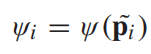 将local patch中的512x6x6的feature map转换为一个unweighted的特征向量
将local patch中的512x6x6的feature map转换为一个unweighted的特征向量
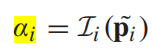 表示第i个patch的没有被遮挡的程度,值越大,说明该patch没有被遮挡,
表示第i个patch的没有被遮挡的程度,值越大,说明该patch没有被遮挡,![]() 表示Attention Net操作, consisting a pooling operation, one convolution
表示Attention Net操作, consisting a pooling operation, one convolution
 表示每个loacl patch带有权重的feature map.
表示每个loacl patch带有权重的feature map.
其中automatically learn = adaptive learning指的是通过最后的softmax来自适应的学习权重。(个人理解,如有错误,请指正!!!)
总结:
1. 本文用的是local patch+ global相结合的方式,并且对local 和global都使用attention对其feature map的向量加权。
2. 但是文章中的Attention net为啥就能对每个local patch学到的权重不一样呢?
答:是因为每一个的local patch的feature map是不同的,所以经过Attention net(每个local pach经过的Attention net的设计模块都是一样的哦)的之后得到不同的权值(权值为标量)【个人理解】
3. 单独考虑local patch对FER的贡献度,没有考虑local patch之间的correaltion对FER的影响。比如人微笑的时候,眉毛,眼睛,嘴巴都呈现弯曲的状态。