SQLserver2008全文检索使用方法
1. 开启SQL Full-text服务
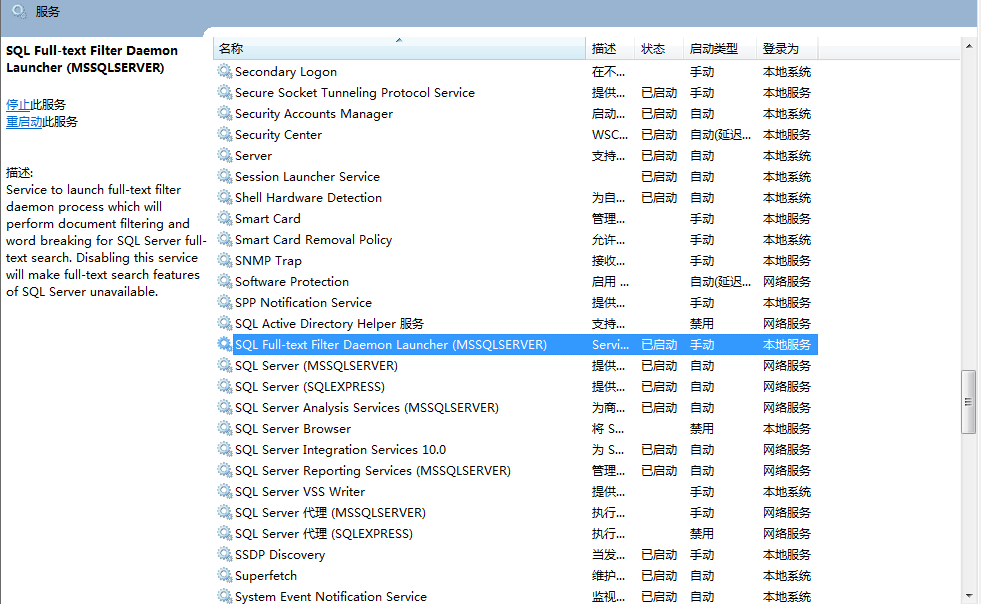
图1 开启 SQLServer Full-text服务
保证 SQL Full-text Filter Daemon Launcher服务处于开启状态,不同版本SQLServer全文检索服务名称可能稍有不同,如果服务列表中没有这个服务,请使用SQLServer安装光盘安装“全文检索”组件。
2. 启用全文检索
执行SQL语句启用全文检索:
Execute sp_fulltext_database 'enable'
3. 设置全文语言为中文
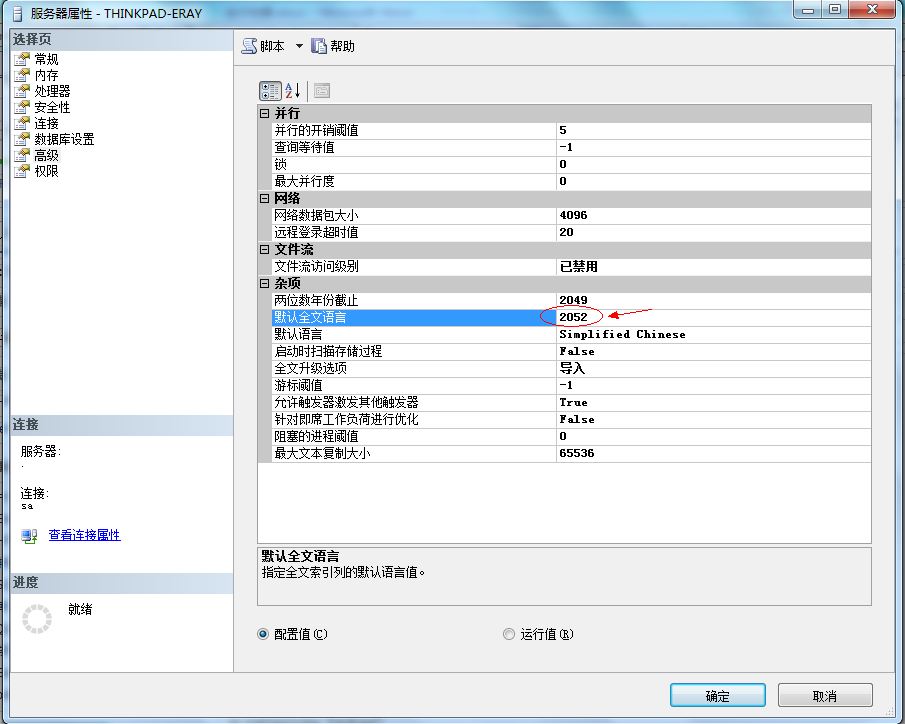
图2 设置全文语言
在服务器->属性->高级中,设置默认全文语言为2052(中文)。
4. 建立数据表
在需要全文检索的数据表中,必须有一列字符型的字段存放文件类型,例如建表语句中的FileType。必须有一列Varbinary(Max)类型的字段存放文件内容,例如建表语句中的FileContent。
建表SQL语句示例:
CREATE TABLE SampleBlobTable
(
[PKID] int identity(1,1) primary key,
[FileName] Nvarchar(255) null,
[FileType] Nvarchar(32) null,
[FileContent] VARBINARY(MAX) NULL,
[AddTime] datetime default(getdate())
)
5. 建立全文索引
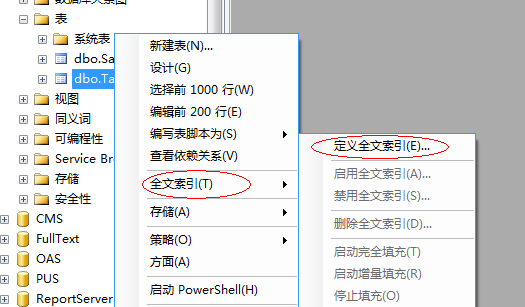
步骤1 建立全文索引
在需要全文检索的数据表上点击右键->全文索引->定义全文索引。
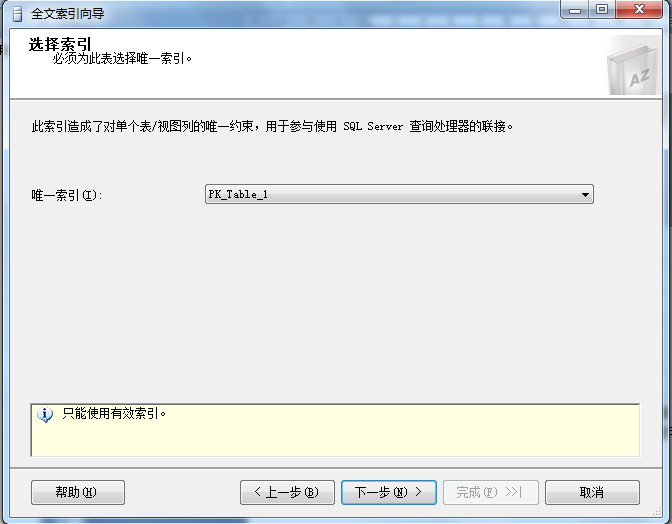
步骤2 选择唯一索引

步骤3 选择表列
选择表列,本例中以FileType列标明文件格式,将文件存入数据库时须正确填写此字段,此字段中的数据内容包括“doc”、“txt”、“xls”等。
后续步骤无需更改默认值,点击下一步继续直至完成。
6. 支持PDF文件
1. 安装 Adobe iFilter
Adobe iFilter6.0:
http://www.adobe.com/support/downloads/thankyou.jsp?ftpID=2611&fileID=2457
Adobe iFilter9.0 for 64bit:
http://www.adobe.com/support/downloads/thankyou.jsp?ftpID=4025&fileID=3941
2. 执行SQL语句
exec sp_fulltext_service 'load_os_resources', 1;
exec sp_fulltext_service 'verify_signature', 0;
3. 重新启动 SQLSERVER
4. 检查支持文件
执行下列语句:
select document_type, path from sys.fulltext_document_types where document_type = '.pdf',如查询结果为下图则表示成功,可以进行PDF的全文检索了。
l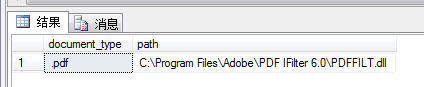
图3 执行结果
7. 查询语法及示例
5. 语法
CONTAINS( { column | * } , '< contains_search_condition >'
)
< contains_search_condition > ::=
{ < simple_term >| < prefix_term >| < generation_term >| < proximity_term >| < weighted_term >
} | { ( < contains_search_condition > )
{ AND | AND NOT | OR } < contains_search_condition > [ ...n ] }
< simple_term > ::=
word | " phrase "
< prefix term> ::=
{ "word * " | "phrase * " }
< generation_term > ::=FORMSOF ( INFLECTIONAL , < simple_term > [ ,...n ] )
< proximity_term > ::=
{ < simple_term > | < prefix_term > }
{ { NEAR | ~ } { < simple_term > | < prefix_term > } } [ ...n ]
< weighted_term > ::=ISABOUT( {{ <simple_term>| < prefix_term >| < generation_term >| < proximity_term >
} [ WEIGHT ( weight_value ) ]
} [ ,...n ]
)
6. 示例
- 查找文件内容含“合同”的数据。
select * from SampleBlobTable where contains(filecontent,'合同')
注意:如果查询条件中包含空格,查询条件需用双引号括起来,如'”合 同”',否则视为语法错误。
- 查找文件内容含“归档”或“标题”的数据。
select * from SampleBlobTable where contains(filecontent,'归档 OR 标题')
注意:多个词之间用逻辑操作符连接 (包括 AND ,AND NOT,OR )。如果词中包含空格,那么这个词要用双引号括起来。
- 查找文件内容含“北京?站”的数据。
select * from SampleBlobTable where contains(filecontent,'北京Near 站')
注意:上述SQL语句将返回包含“北京站”、“北京西站”、“北京东站”等“北京”与“站”无间隔或间隔一个汉字(如果是英文则为一个单词)的数据,不会包含“北京东南站”的数据。
- 查找所有开头字母为”hu”的数据。
select * from SampleBlobTable where contains(filecontent,'hu*')
注意:上述SQL语句将返回包含”human”、”hungry”等单词的数据,此语法只针对英文有效,针对中文“*”符号无论有无,效果均相同。
- 加权查询
select * from SampleBlobTable where contains(filecontent,'ISABOUT (city weight (.8), county weight (.4))')
注意:上述SQL语将将针对city和county两个词进行不同权重的查询,权重不同将影响返回数据集的显示顺序(如果限定返回数量,则间接影响是否返回数据)。
- 多态查询
select * from SampleBlobTable where contains(filecontent,'FORMSOF (INFLECTIONAL,dry)')
注意:查询将返回包含”dry”,”dried”,”drying”等数据,针对英语有效。
作者:王春天 地址:http://www.cnblogs.com/spring_wang/